本文共 2421 字,大约阅读时间需要 8 分钟。
BILSTM-CRF
在中,我们知道CRF层可以从训练数据集中学习一些约束,以确保最终预测的实体标签序列是有效的。约束可能是:
- 句子中第一个单词的标签应以“B-”或“O”开头,而不是“I-”
- “B-label1 I-label2 I-label3 I- …”,在此模式中,label1,label2,label3 …应该是相同的命名实体标签。例如,“B-Person I-Person”有效,但“B-Person I-Organization”无效。
- “O I-label”无效。一个命名实体的第一个标签应以“B-”而非“I-”开头,换句话说,有效模式应为“O B-label”
- … 阅读本文后,您将了解为什么CRF层可以学习这些约束。
2 CRF层
在CRF层的损失函数中,我们有两种类型的分数。这两个分数是CRF层的关键概念。
2.1 Emission score
emission score来自BiLSTM层。如图2.1所示,例如, w 0 w_0 w0的得分标记为“B-Person”的是1.5。
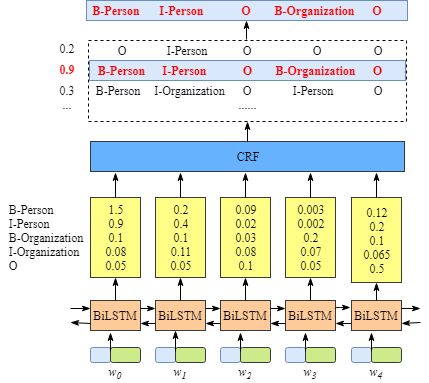
为方便起见,我们将为每个标签提供一个索引号,如下表所示。
| 标签 | 索引号 |
|---|---|
| B-Person | 0 |
| I-Person | 1 |
| B-Organization | 2 |
| I-Organization | 3 |
| O | 4 |
我们使用 x i y j x_{iy_j} xiyj代表emission scrore。 i i i是词的索引, y j y_j yj是标签的索引。例如,根据图2.1, x i = 1 , y j = 2 = x w 1 , B − O r g a n i z a t i o n = 0.1 x_{i=1, y_j=2}=x_{w_1, B-Organization}=0.1 xi=1,yj=2=xw1,B−Organization=0.1,其表示 w 1 w_1 w1被认为是“ B-Organization”的分数是0.1。
2.2 Transition score
我们使用 t y i y j t_{y_{i}y_{j}} tyiyj表示transition score。例如, t B − P e r s o n , I − P e r s o n = 0.9 t_{B-Person, I-Person}=0.9 tB−Person,I−Person=0.9表示标签“B-Person”->“I-Person”的转换分数是0.9。因此,我们有一个转换分数矩阵,用于存储所有标签之间的所有分数。为了使转换得分矩阵更加健壮,我们将再添加两个标签,“START”和“END”。“START”表示句子的开头,而不是第一个单词。“END”表示句末。以下是转换矩阵分数的示例,包括额外添加的“START”和“END”标签。
| START | B-Person | I-Person | B-Organization | I-Organization | O | END |
|---|---|---|---|---|---|---|
| START | 0 | 0.8 | 0.007 | 0.7 | 0.0008 | 0.9 |
| B-Person | 0 | 0.6 | 0.9 | 0.2 | 0.0006 | 0.6 |
| I-Person | -1 | 0.5 | 0.53 | 0.55 | 0.0003 | 0.85 |
| B-Organization | 0.9 | 0.5 | 0.0003 | 0.25 | 0.8 | 0.77 |
| I-Organization | -0.9 | 0.45 | 0.007 | 0.7 | 0.65 | 0.76 |
| O | 0 | 0.65 | 0.0007 | 0.7 | 0.0008 | 0.9 |
| END | 0 | 0 | 0 | 0 | 0 | 0 |
如上表所示,我们可以发现转换矩阵已经学到了一些有用的约束
- 句子中第一个单词的标签应以“B-”或“O”开头,而不是“I-” (从“START”到“I-Person或I-Organization”的转换分数非常低。)
- “B-label1 I-label2 I-label3 I- …”,在此模式中,label1,label2,label3 …应该是相同的命名实体标签。例如,“B-Person I-Person”有效,但“B-Person I-Organization”无效。(例如,从“B-Organization”到“I-Person”的得分仅为0.0003,远远低于其他人。)
- “O I-label”无效。一个命名实体的第一个标签应该以“B-”而不是“I-”开头,换句话说,有效模式应该是“O B-label” (例如,分数 t O , I − P e r s o n t{O, I-Person} tO,I−Person非常小。)
- … 您可能想询问有关转换矩阵的问题。在何处或如何获得转换矩阵?实际上,转换矩阵是BiLSTM-CRF模型的参数。在训练模型之前,您可以随机初始化矩阵中的所有转换分数。所有随机分数将在训练过程中自动更新。换句话说,CRF层可以自己学习这些约束。我们不需要手动构建矩阵。随着训练迭代次数的增加,分数将逐渐变得越来越合理。
下一节
2.3 CRF损失功能
引入CRF损失函数,其由实际路径得分和所有可能路径的总得分组成。
2.4 真实路径得分
如何计算句子真实标签的分数。
2.5 所有可能路径的得分
如何使用逐步玩具示例计算句子所有可能路径的总分。
参考
[1] Lample, G., Ballesteros, M., Subramanian, S., Kawakami, K. and Dyer, C., 2016. Neural architectures for named entity recognition. arXiv preprint arXiv:1603.01360.
转载地址:https://blog.csdn.net/zhang2010hao/article/details/85284687 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
