本文共 1988 字,大约阅读时间需要 6 分钟。
Spark发展历史
2009年诞生
2014成为Apache顶级项目
2016发布2.0
2019发布3.0
2020年9月份发布3.0.1
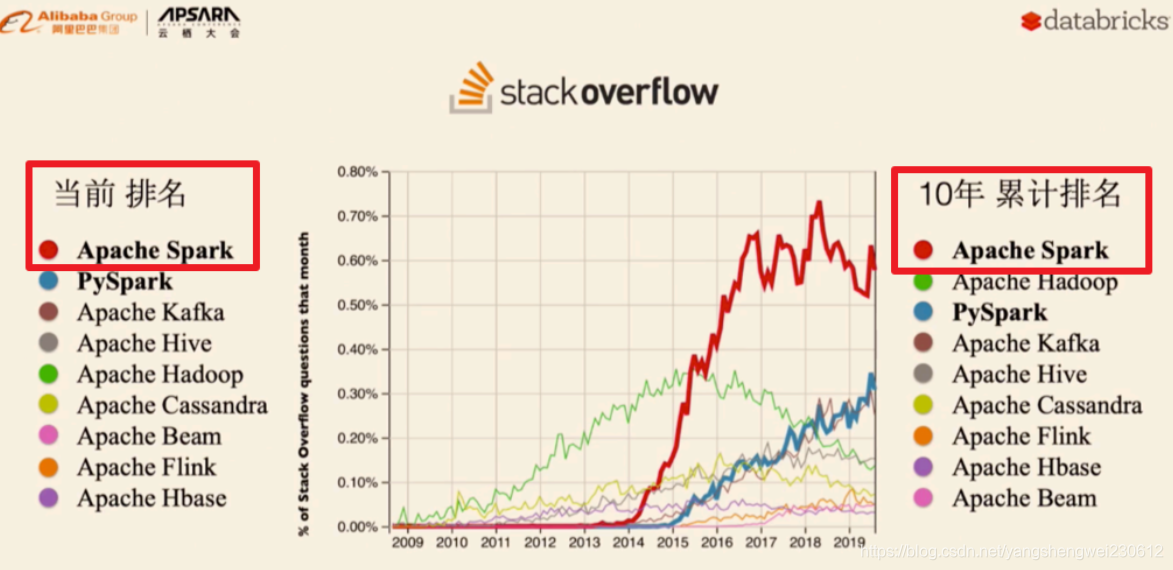
使用现状
Spark环境搭建-Standalone-独立集群
原理
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YVMaWFlo-1623742615085)(Spark-day01.assets/1609553123267.png)]](https://img-blog.csdnimg.cn/20210615154104376.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3lhbmdzaGVuZ3dlaTIzMDYxMg==,size_16,color_FFFFFF,t_70)
操作
1.集群规划
node1:master
ndoe2:worker/slave
node3:worker/slave
2.配置slaves/workers
进入配置目录
cd /export/server/spark/conf
修改配置文件名称
mv slaves.template slaves
vim slaves
内容如下:
node2node3
3.配置master
进入配置目录
cd /export/server/spark/conf
修改配置文件名称
mv spark-env.sh.template spark-env.sh
修改配置文件
vim spark-env.sh
增加如下内容:
## 设置JAVA安装目录JAVA_HOME=/export/server/jdk## HADOOP软件配置文件目录,读取HDFS上文件和运行Spark在YARN集群时需要,先提前配上HADOOP_CONF_DIR=/export/server/hadoop/etc/hadoopYARN_CONF_DIR=/export/server/hadoop/etc/hadoop## 指定spark老大Master的IP和提交任务的通信端口SPARK_MASTER_HOST=node1SPARK_MASTER_PORT=7077SPARK_MASTER_WEBUI_PORT=8080SPARK_WORKER_CORES=1SPARK_WORKER_MEMORY=1g
4.分发
将配置好的将 Spark 安装包分发给集群中其它机器,命令如下:
cd /export/server/
scp -r spark-3.0.1-bin-hadoop2.7 root@node2:$PWD
scp -r spark-3.0.1-bin-hadoop2.7 root@node3:$PWD
创建软连接
ln -s /export/server/spark-3.0.1-bin-hadoop2.7 /export/server/spark
测试
1.集群启动和停止
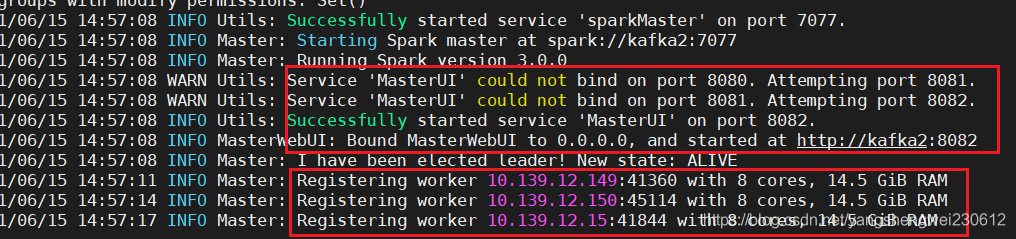
在主节点上启动spark集群
/export/server/spark/sbin/start-all.sh
在主节点上停止spark集群
/export/server/spark/sbin/stop-all.sh
在主节点上单独启动和停止Master:
start-master.sh
stop-master.sh
在从节点上单独启动和停止Worker(Worker指的是slaves配置文件中的主机名)
start-slaves.sh
stop-slaves.sh
2.jps查看进程
node1:master
node2/node3:worker
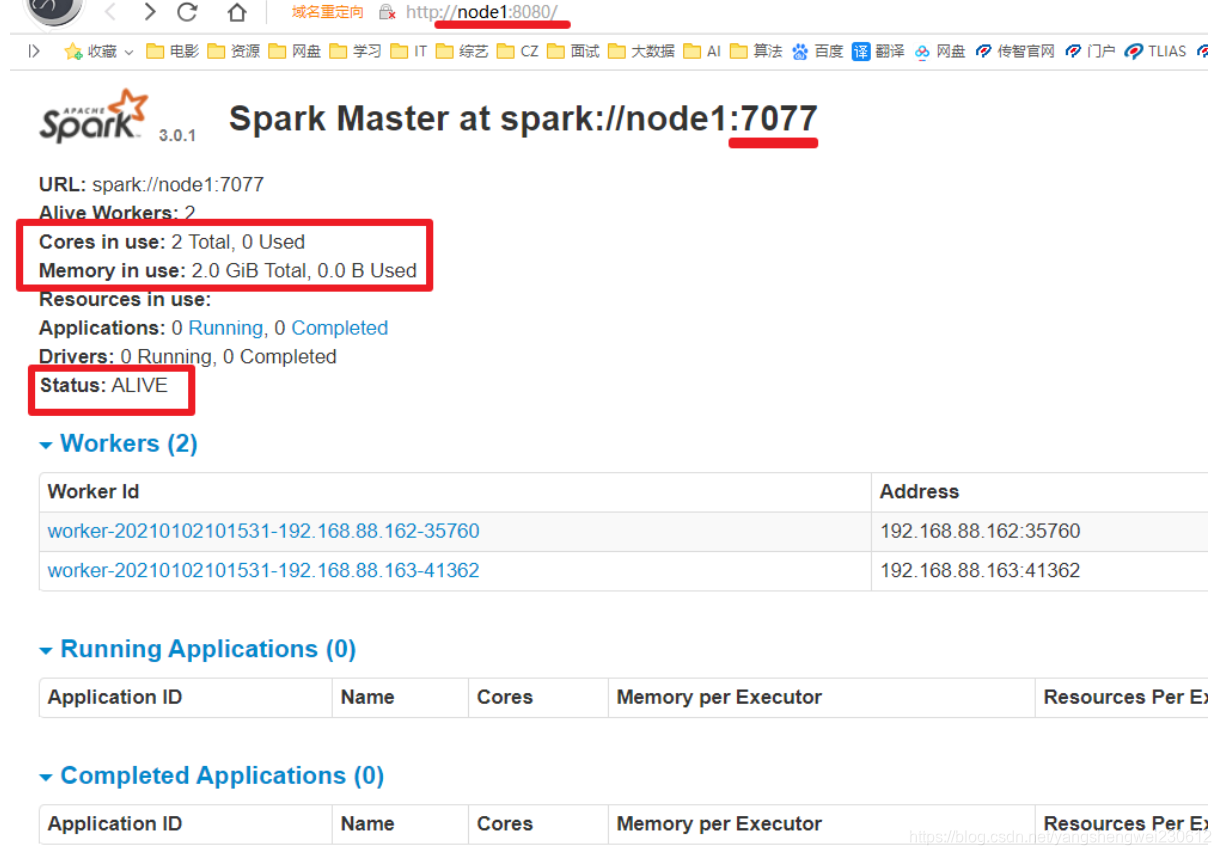
3.打开master web ui
http://node1:8080/如果你设置的***SPARK_MASTER_WEBUI_PORT=8080*** 端口号已存在,spark master会加一尝试找到一个没有被占用的端口号使用
4.启动spark-shell
spark/bin/spark-shell --master spark://kafka2:7077
val textFile = sc.textFile("hdfs://kafka1:9000/user/ysw/input3/user_visit_action.txt")val counts = textFile.flatMap(_.split(" ")).map((_,1)).reduceByKey(_ + _)counts.collectcounts.saveAsTextFile("hdfs://kafka1:9000/user/ysw/user_visit_action1.txt") 6.查看结果
http://node1:50070/explorer.html#/wordcount/output2
7.查看spark任务web-ui
http://node1:4040/jobs/
总结:
spark: 4040 任务运行web-ui界面端口
spark: 8080 spark集群web-ui界面端口
spark: 7077 spark提交任务时的通信端口
hadoop: 50070集群web-ui界面端口
hadoop:8020/9000(老版本) 文件上传下载通信端口
8.停止集群
/export/server/spark/sbin/stop-all.sh
转载地址:https://blog.csdn.net/yangshengwei230612/article/details/117926353 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
