本文共 4551 字,大约阅读时间需要 15 分钟。
Flink程序优化
使用Flink Checkpoint进行容错处理
计算的中间结果可以说是一种状态,status是个名词,checkpoin是个动词,及checkpoin把status的值持久化到hdfs中
checkpoint是Flink容错的核心机制。它可以定期地将各个Operator处理的数据进行快照存储( Snapshot )。如果Flink程序出现宕机,可以重新从这些快照中恢复数据。
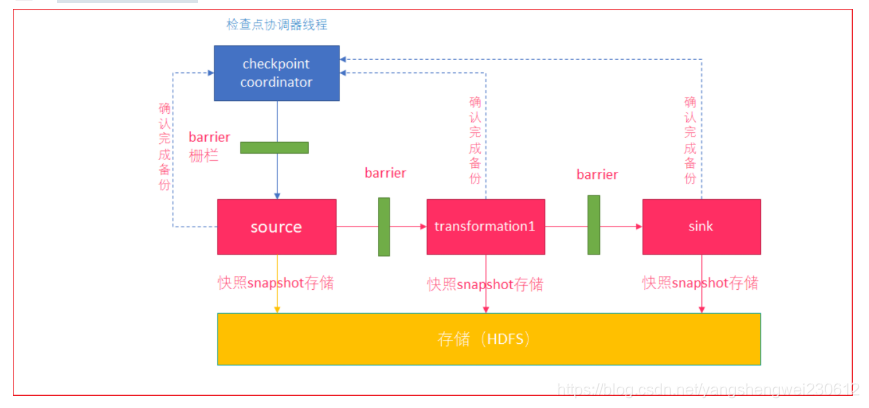
- checkpoint coordinator(协调器)线程周期生成 barrier (栅栏),发送给每一个source
- source将当前的状态进行snapshot(可以保存到HDFS)
- source向coordinator确认snapshot已经完成
- source继续向下游transformation operator发送 barrier
- transformation operator重复source的操作,直到sink operator向协调器确认snapshot完成
- coordinator确认完成本周期的snapshot
配置以下checkpoint:
1、开启 checkpoint
2、设置 checkpoint 保存HDFS的位置
3、配置 checkpoint 的最小时间间隔(1秒)
4、配置 checkpoint 最大线程数 (1)
5、配置 checkpoint 超时时间 (60秒)
6、配置程序关闭,额外触发 checkpoint
7、配置重启策略 (尝试1次,延迟1秒启动)
8、给两个 source 添加 checkpoint 容错支持
- 给需要进行checkpoint的operator设置 uid
参考代码
// 配置Checkpointenv.enableCheckpointing(5000)env.getCheckpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE)// checkpoint的HDFS保存位置env.setStateBackend(new FsStateBackend("hdfs://node1:8020/flink/checkpoint/"))// 配置两次checkpoint的最小时间间隔env.getCheckpointConfig.setMinPauseBetweenCheckpoints(1000)// 配置最大checkpoint的并行度env.getCheckpointConfig.setMaxConcurrentCheckpoints(1)// 配置checkpoint的超时时长env.getCheckpointConfig.setCheckpointTimeout(60000)// 当程序关闭,触发额外的checkpointenv.getCheckpointConfig.enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION)env.setRestartStrategy(RestartStrategies.fixedDelayRestart(1, 1000)) // 3. 将配置添加到数据流中val clickLogJSONDataStream: DataStream[String] = env.addSource(finkKafkaConsumer).uid(UUID.randomUUID().toString).setParallelism(3)// clickLogJSONDataStream.print()val canalJsonDataStream: DataStream[String] = env.addSource(flinkKafkaCanalConsumer).uid(UUID.randomUUID().toString)// canalJsonDataStream.print()
使用Flink时间窗口
生成watermark(水印)
1、实现 extractTimestamp 获取水印时间
设置 EventTime
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
2、获取当前的水印时间
val canalEntityWithWarterMark: DataStream[CanalEntity] = canalEntityDataStream.assignTimestampsAndWatermarks(new AssignerWithPeriodicWatermarks[CanalEntity] { var currentMaxTimestamp = 0L var maxOutOfOrderness = 10 * 1000L // 最大允许的乱序时间是10s override def getCurrentWatermark: Watermark = { return new Watermark(currentMaxTimestamp - maxOutOfOrderness) } override def extractTimestamp(t: CanalEntity, l: Long): Long = { currentMaxTimestamp = t.exe_time currentMaxTimestamp }}) 3、修改使用 apply 方法
// 设置5s的时间窗口val windowDataStream: AllWindowedStream[CanalEntity, TimeWindow] = orderGoodsCanalEntityDataStream.timeWindowAll(Time.seconds(5)) // 设置5秒时间窗口.allowedLateness(Time.seconds(10)) // 设置最大延迟时间.sideOutputLateData(new OutputTag[CanalEntity]("outlateData")) // 设置延迟的数据存放地方val orderGoodsWideEntityDataStream: DataStream[OrderGoodsWideEntity] = windowDataStream.apply((timeWindow, iter, collector: Collector[OrderGoodsWideEntity]) => { var jedis = RedisUtil.getJedis() val iterator = iter.iterator // ... 此处省略 ... collector.collect(orderGoodsWideEntity) val sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss") println(sdf.format(new Date(timeWindow.getStart)) + " " + sdf.format(new Date(timeWindow.getEnd))) }}) 并行度优化
1、调整Kafka topic的分区数量
2、设置Kafka DataStream并行度和Kafka的分区一致
Flink反压原理
什么是背压问题
- 流系统中消息的处理速度跟不上消息的发送速度,会导致消息的堆积
- 许多日常问题都会导致背压
- 垃圾回收卡顿可能会导致流入的数据快速堆积
- 一个数据源可能生产数据的速度过快
- 背压如果不能得到正确地处理,可能会导致 资源被耗尽 或者甚至出现更糟的情况导致数据丢失
在同一时间点,不管是流处理job还是sink,如果有1秒的卡顿,那么将导致至少500万条记录的积压。换句话说,source可能会产生一个脉冲,在一秒内数据的生产速度突然翻倍。
举例说明
1、正常情况
-
消息处理速度 >= 消息的发送速度,不发生消息拥堵,系统运行流畅
 2、异常情况
2、异常情况 -
消息处理速度< 消息的发送速度,发生了消息拥堵,系统运行不畅。

背压问题解决方案
可以采取三种方案:
- 将拥堵的消息直接删除
- 会导致数据丢失,许多流处理程序而言是不可接受的
- 将缓冲区持久化,以方便在处理失败的情况下进行数据重放
- 会导致缓冲区积压的数据越来越多
- 将拥堵的消息缓存起来,并告知消息发送者减缓消息发送的速度
- 对source进行限流来适配整个pipeline中最慢组件的速度,从而获得稳定状态
Flink如何解决背压问题
Flink内部自动实现数据流自然降速,而无需担心数据丢失。Flink所获取的最大吞吐量是由pipeline中最慢的组件决定
Flink解决背压问题的原理
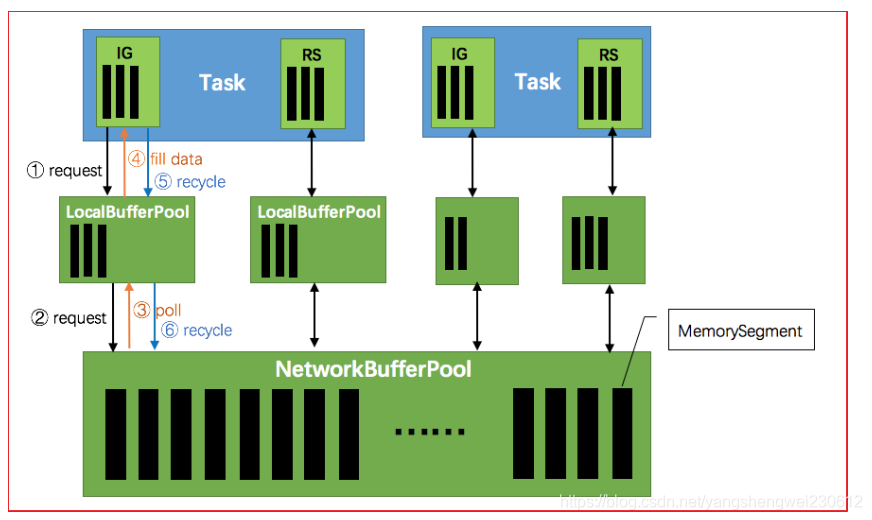

1、TaskManager(TM)启动时,会初始化网络缓冲池(NetworkBufferPool)
- 默认生成 2048 个内存块(MemorySegment)
- 网络缓冲池是Task之间共享的
2、Task线程启动时,Flink 会为Task的 Input Gate(IG)和 ResultPartion(RS)分别创建一个 LocationBufferPool
- LocationBufferPool的内存数量由Flink分配
- 为了系统更容易应对瞬时压力,内存数量是动态分配的
3、Task线程执行时,Netty接收端接收到数据时,为了将数据保存拷贝到Task中
- Task线程需要向本地缓冲池(LocalBufferPool)申请内存
- 若本地缓冲池没有可用内存,则继续向网络缓冲池(NetworkBufferPool)申请内存
- 内存申请成功,则开始从Netty中拷贝数据
- 若缓冲池已申请的数量达到上限,或网络缓冲池(NetworkerBufferPool)也没有可用内存时,该Task的Netty Channel会暂停读取,上游的发送端会立即响应停止发送,Flink流系统进入反压状态
4、经过 Task 处理后,由 Task 写入到 ResultPartion(RS)中
- 当Task线程写数据到ResultPartion(RS)时,也会向网络缓冲池申请内存
- 如果没有可用内存块,也会阻塞Task,暂停写入
5、Task处理完毕数据后,会将内存块交还给本地缓冲池(LocalBufferPool)
- 如果本地缓冲池申请内存的数量超过池子设置的数量,将内存块回收给 网络缓冲池。如果没超过,会继续留在池子中,减少反复申请开销
转载地址:https://blog.csdn.net/yangshengwei230612/article/details/116426223 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
