本文共 16100 字,大约阅读时间需要 53 分钟。
第1章 Spark 概述
Spark 是一种基于内存的快速、通用、可扩展的大数据分析计算引擎。
1.2 Spark and Hadoop



1.3 Spark or Hadoop(MapReduce)
Spark 和Hadoop 的根本差异是多个作业之间的数据通信问题 : Spark 多个作业之间数据通信是基于内存,而 Hadoop 是基于磁盘。
MapReduce
数据->map->reducer->磁盘->map->reducer
 Spark 数据->map->reducer->内存->map->reducer
Spark 数据->map->reducer->内存->map->reducer 


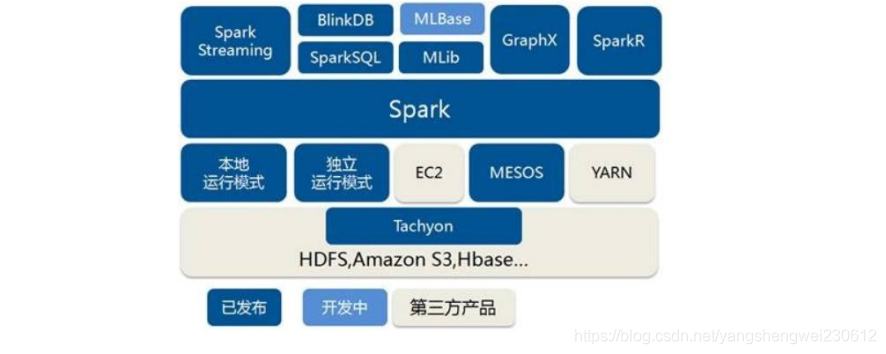
1.4 Spark 核心模块


第2章 Spark 快速上手
2.1 创建 Maven 项目
参考:
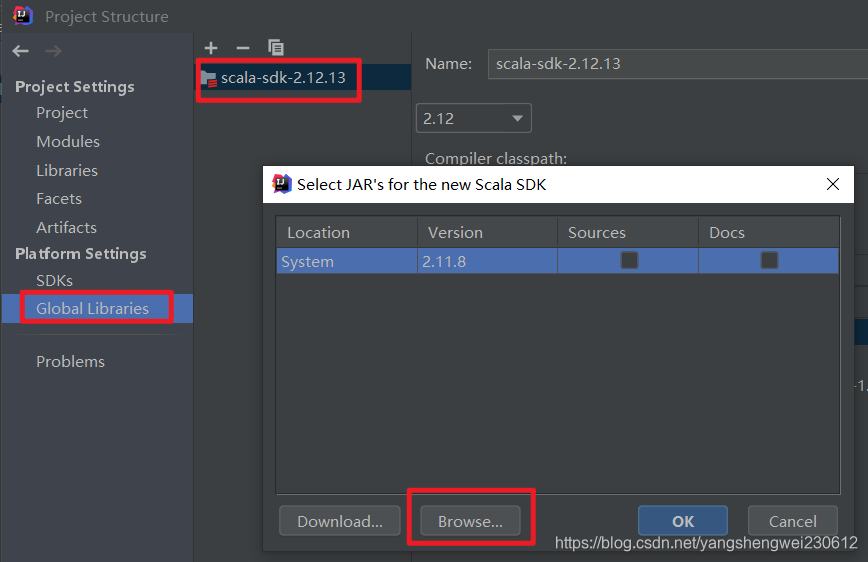
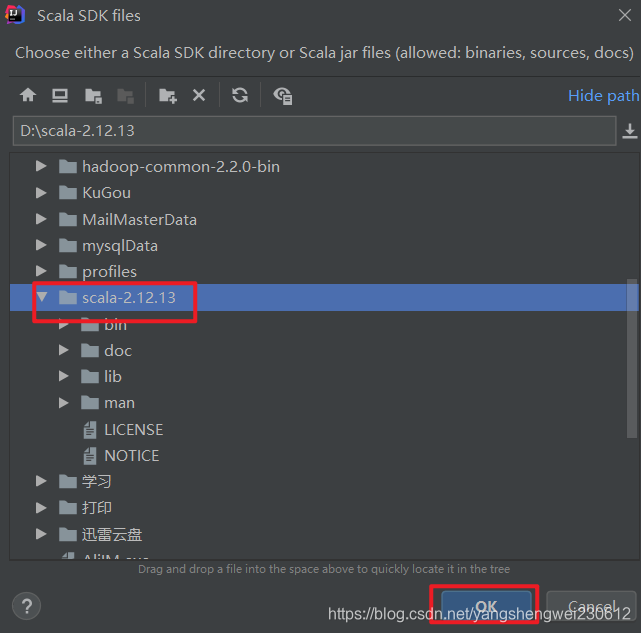
2.1.1 增加 Scala 插件

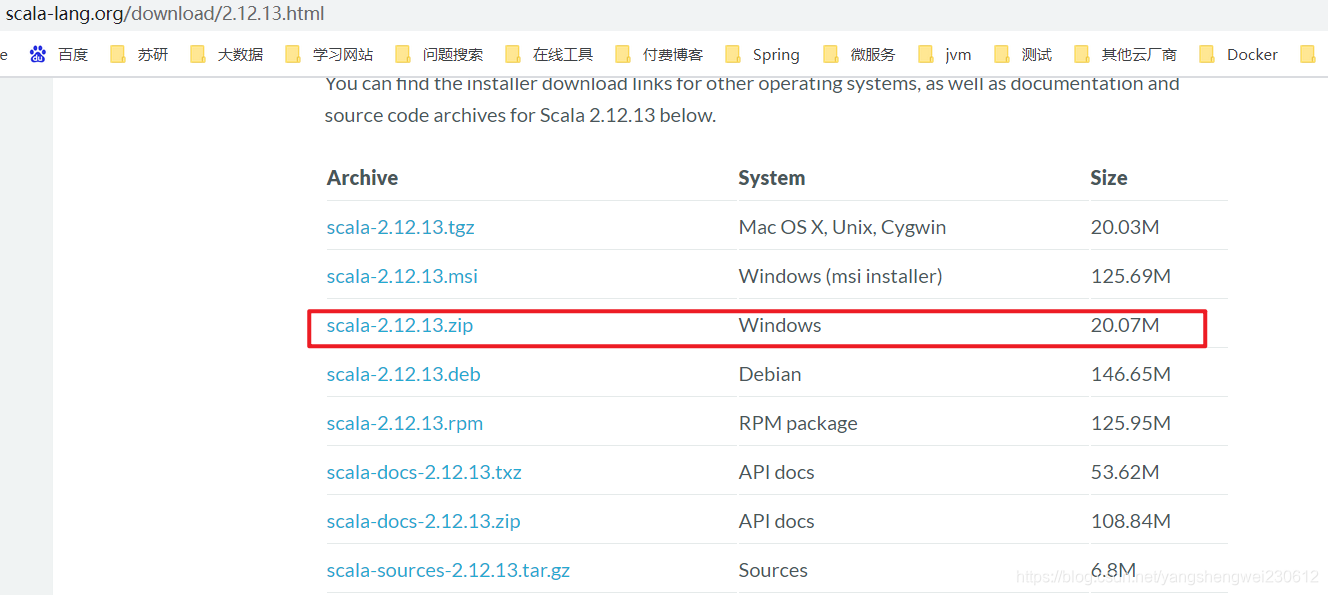
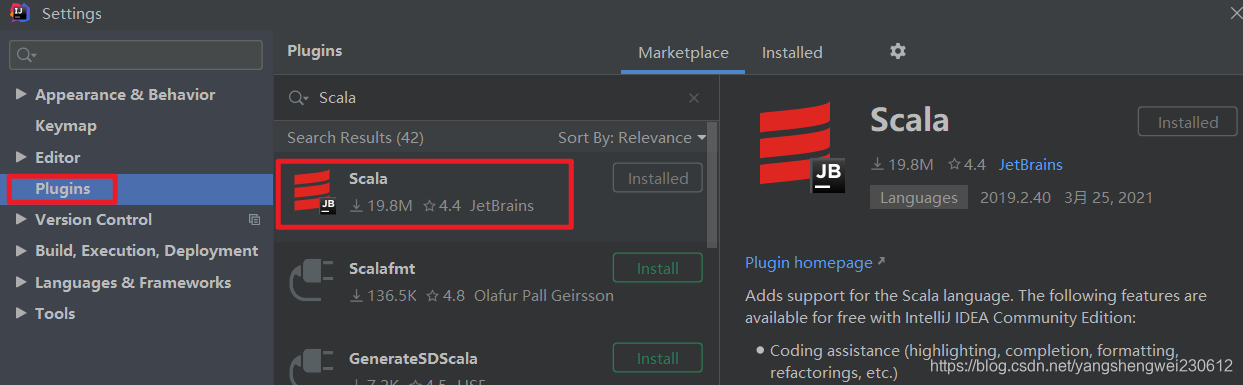 官网下载scala lib 添加至IDEA 百度下载解压:https://www.scala-lang.org/download/2.12.13.html
官网下载scala lib 添加至IDEA 百度下载解压:https://www.scala-lang.org/download/2.12.13.html 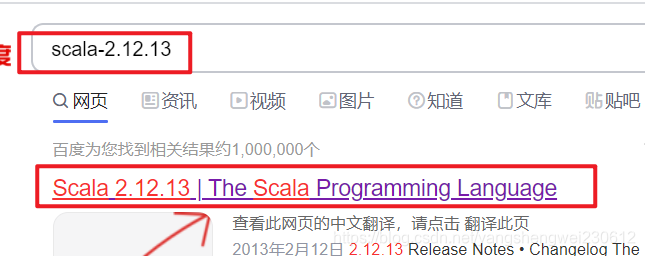
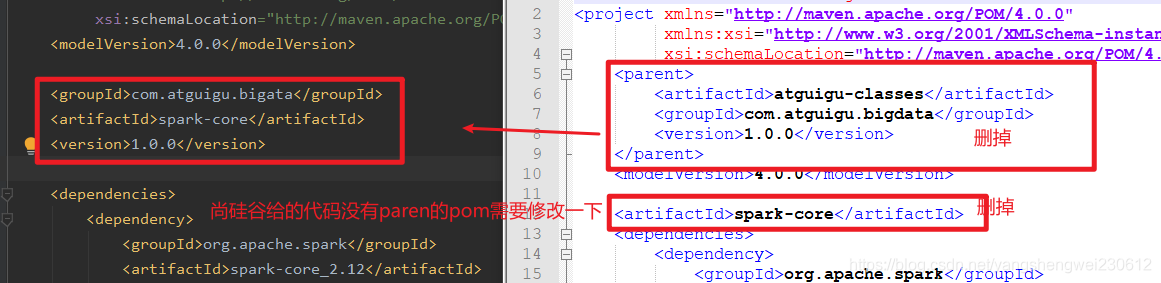
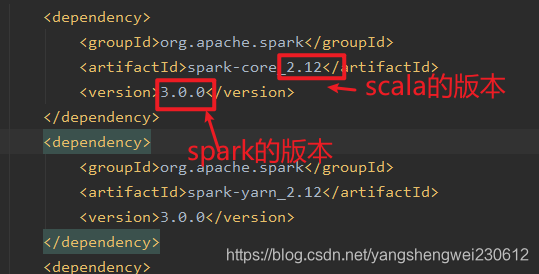
4.0.0 com.atguigu.bigata spark-core 1.0.0 org.apache.spark spark-core_2.12 3.0.0 net.alchim31.maven scala-maven-plugin 3.2.2 testCompile org.apache.maven.plugins maven-assembly-plugin 3.1.0 jar-with-dependencies make-assembly package single
计算思路流程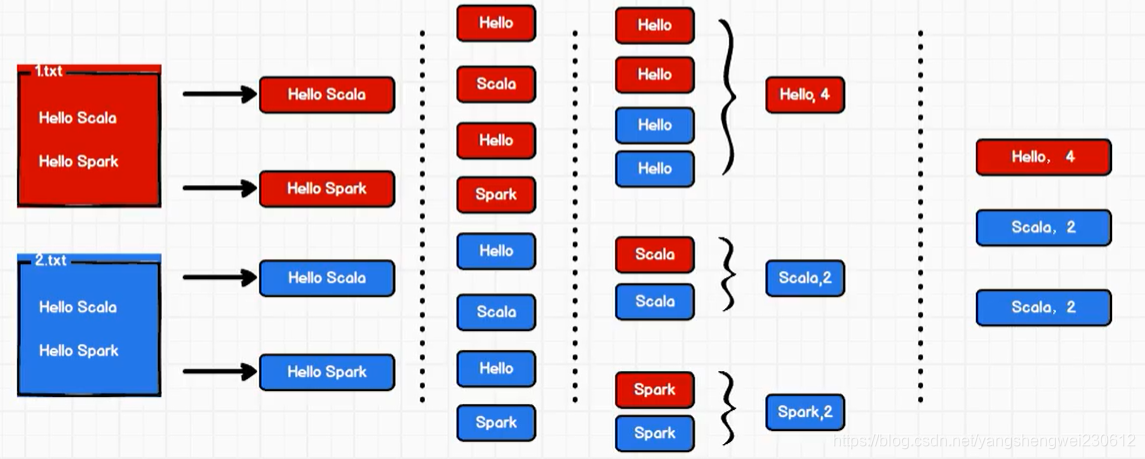
2.1.4 异常处理
如果本机操作系统是 Windows,在程序中使用了 Hadoop 相关的东西,比如写入文件到HDFS,则会遇到如下异常:
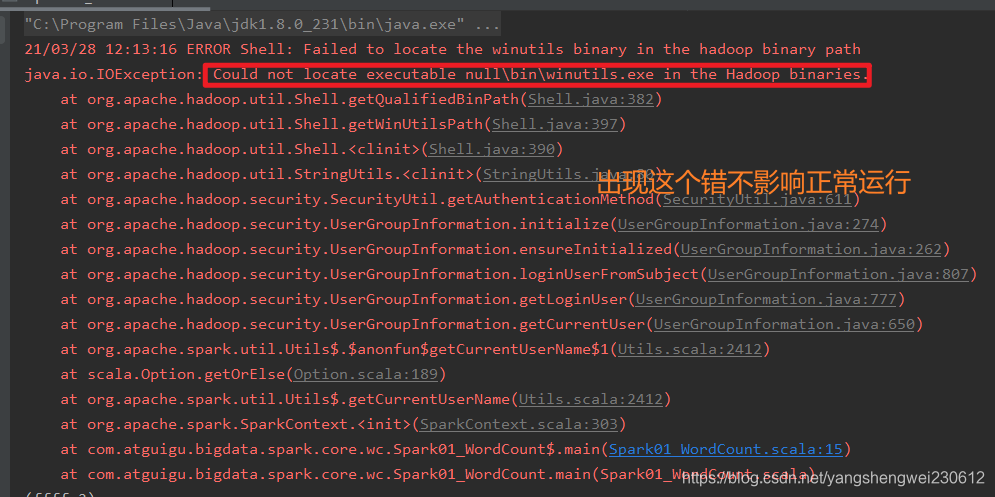
出现这个问题的原因,并不是程序的错误,而是 windows 系统用到了 hadoop 相关的服务,解决办法是通过配置关联到 windows 的系统依赖就可以了
链接:https://pan.baidu.com/s/1V17LkgPQnQpVO-8BqHbRgg 提取码:xe55
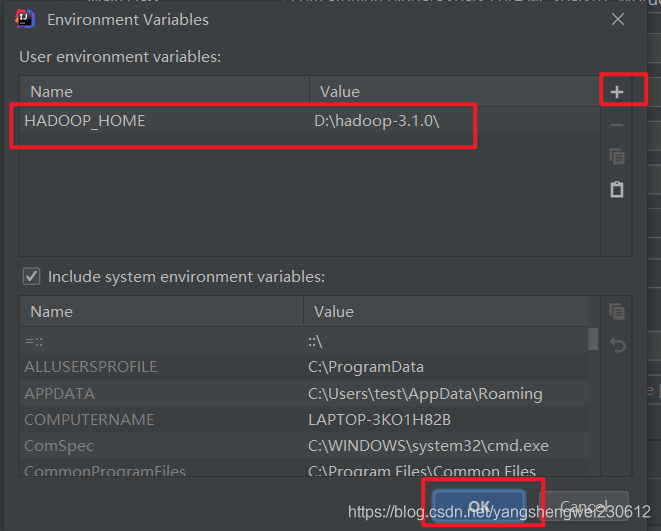
在 IDEA 中配置 Run Configuration,添加 HADOOP_HOME 变量
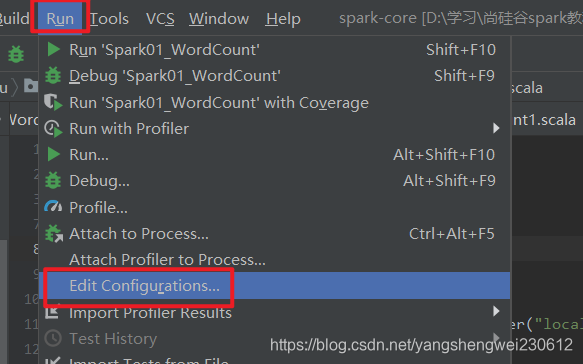
并行数

代码示例
package com.atguigu.bigdata.spark.core.wcimport org.apache.spark.rdd.RDDimport org.apache.spark.{ SparkConf, SparkContext}object Spark01_WordCount { def main(args: Array[String]): Unit = { // Application // Spark框架 // TODO 建立和Spark框架的连接 // JDBC : Connection val sparConf = new SparkConf().setMaster("local").setAppName("WordCount") val sc = new SparkContext(sparConf) // TODO 执行业务操作 // 1. 读取文件,获取一行一行的数据 // hello world val lines: RDD[String] = sc.textFile("datas") // 2. 将一行数据进行拆分,形成一个一个的单词(分词) // 扁平化:将整体拆分成个体的操作 // "hello world" => hello, world, hello, world val words: RDD[String] = lines.flatMap(_.split(" ")) // 3. 将数据根据单词进行分组,便于统计 // (hello, hello, hello), (world, world) val wordGroup: RDD[(String, Iterable[String])] = words.groupBy(word=>word) // 4. 对分组后的数据进行转换 // (hello, hello, hello), (world, world) // (hello, 3), (world, 2) val wordToCount = wordGroup.map { case ( word, list ) => { (word, list.size) } } // 5. 将转换结果采集到控制台打印出来 val array: Array[(String, Int)] = wordToCount.collect() array.foreach(println) // TODO 关闭连接 sc.stop() }} 
 提示需要的一个具体文件而不是一个文件夹
提示需要的一个具体文件而不是一个文件夹 windows上解决的办法:
val lines: RDD[String] = sc.textFile(“datas/*”)
使用集合方法计算
scala原生代码

spark提供的

// 相同key的value进行聚合操作 // (word, 1) => (word, sum) val wordToSum: RDD[(String, Int)] = wordToOne.reduceByKey(_+_)
// 创建 Spark 运行配置对象val sparkConf = new SparkConf().setMaster("local[*]").setAppName("WordCount")// 创建 Spark 上下文环境对象(连接对象)val sc : SparkContext = new SparkContext(sparkConf)// 读取文件数据val fileRDD: RDD[String] = sc.textFile("input/word.txt")// 将文件中的数据进行分词val wordRDD: RDD[String] = fileRDD.flatMap( _.split(" ") )// 转换数据结构 word => (word, 1)val word2OneRDD: RDD[(String, Int)] = wordRDD.map((_,1))// 将转换结构后的数据按照相同的单词进行分组聚合val word2CountRDD: RDD[(String, Int)] = word2OneRDD.reduceByKey(_+_)// 将数据聚合结果采集到内存中val word2Count: Array[(String, Int)] = word2CountRDD.collect()// 打印结果word2Count.foreach(println)//关闭 Spark 连接sc.stop() 代码实现
package com.atguigu.bigdata.spark.core.wcimport org.apache.spark.rdd.RDDimport org.apache.spark.{ SparkConf, SparkContext}object Spark02_WordCount1 { def main(args: Array[String]): Unit = { // Application // Spark框架 // TODO 建立和Spark框架的连接 // JDBC : Connection val sparConf = new SparkConf().setMaster("local").setAppName("WordCount") val sc = new SparkContext(sparConf) // TODO 执行业务操作 // 1. 读取文件,获取一行一行的数据 // hello world val lines: RDD[String] = sc.textFile("datas/*") // 2. 将一行数据进行拆分,形成一个一个的单词(分词) // 扁平化:将整体拆分成个体的操作 // "hello world" => hello, world, hello, world val words: RDD[String] = lines.flatMap(_.split(" ")) // 3. 将单词进行结构的转换,方便统计 // word => (word, 1) val wordToOne = words.map(word=>(word,1)) // 4. 将转换后的数据进行分组聚合 // 相同key的value进行聚合操作 // (word, 1) => (word, sum) val wordToSum: RDD[(String, Int)] = wordToOne.reduceByKey(_+_) // 5. 将转换结果采集到控制台打印出来 val array: Array[(String, Int)] = wordToSum.collect() array.foreach(println) // TODO 关闭连接 sc.stop() }} 第3章 Spark 运行环境
Spark 作为一个数据处理框架和计算引擎,被设计在所有常见的集群环境中运行, 在国内工作中主流的环境为 Yarn,不过逐渐容器式环境也慢慢流行起来。接下来,我们就分别看看不同环境下 Spark 的运行
3.1 Local 模式

3.2 Standalone 模式
3.3 Yarn 模式
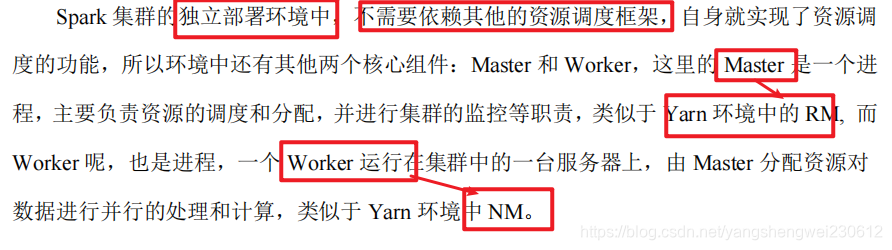
独立部署(Standalone)模式由 Spark 自身提供计算资源,无需其他框架提供资源。这种方式降低了和其他第三方资源框架的耦合性,独立性非常强。但是你也要记住,Spark 主要是计算框架,而不是资源调度框架,所以本身提供的资源调度并不是它的强项,所以还是和其他专业的资源调度框架集成会更靠谱一些。所以接下来我们来学习在强大的 Yarn 环境下 Spark 是如何工作的(其实是因为在国内工作中,Yarn 使用的非常多)。
3.3.1 解压缩文件
将 spark-3.0.0-bin-hadoop3.2.tgz 文件上传到 linux 并解压缩,放置在指定位置。
tar -zxvf spark-3.0.0-bin-hadoop3.2.tgz -C /opt/modulecd /opt/module mv spark-3.0.0-bin-hadoop3.2 spark-yarn
3.3.2 修改配置文件
- 修改 hadoop 配置文件/opt/module/hadoop/etc/hadoop/yarn-site.xml, 并分发
yarn.nodemanager.pmem-check-enabled false yarn.nodemanager.vmem-check-enabled false
- 修改 conf/spark-env.sh,添加 JAVA_HOME 和 YARN_CONF_DIR 配置
mv spark-env.sh.template spark-env.sh。。。export JAVA_HOME=/opt/module/jdk1.8.0_144YARN_CONF_DIR=/opt/module/hadoop/etc/hadoop
3.3.3 启动 HDFS 以及 YARN 集群
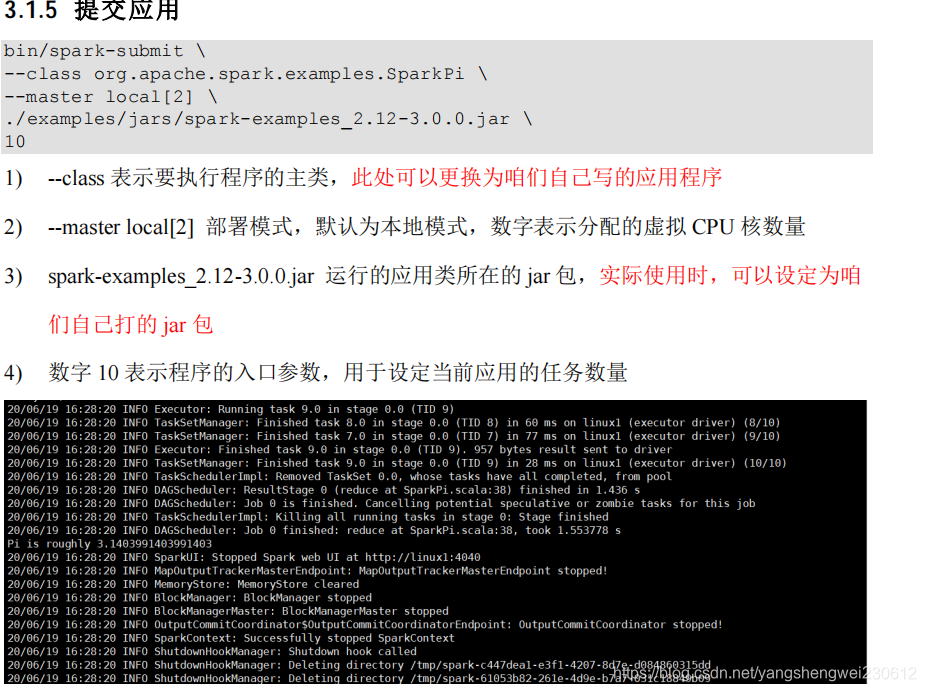
瞅啥呢,自己启动去! 3.3.4 提交应用bin/spark-submit \--class org.apache.spark.examples.SparkPi \--master yarn \--deploy-mode cluster \./examples/jars/spark-examples_2.12-3.0.0.jar \10
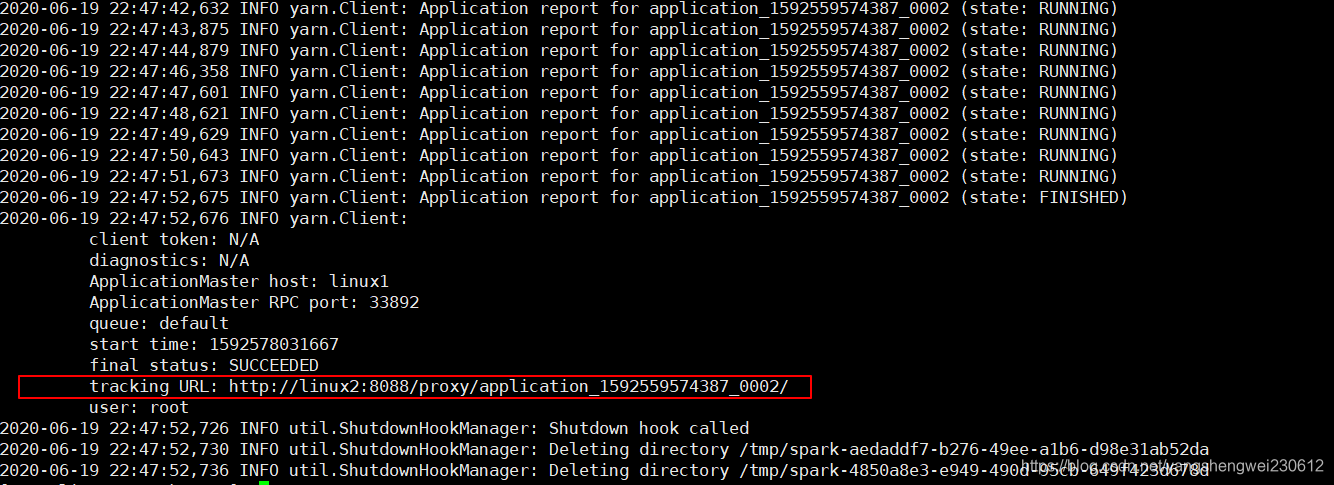



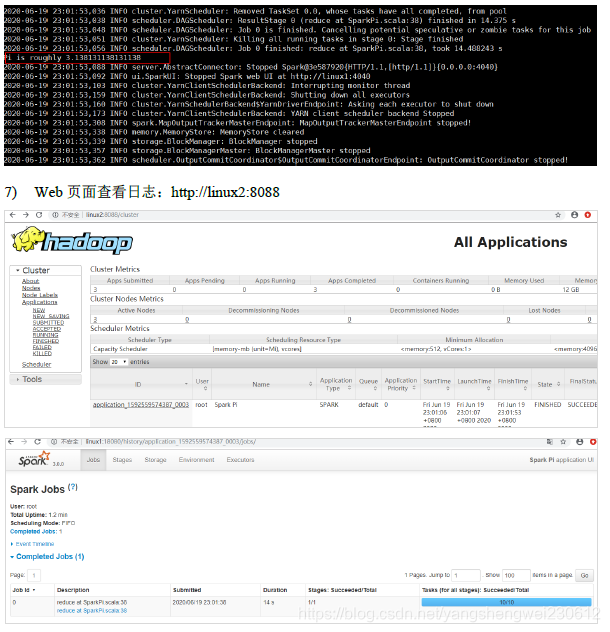
3.4 K8S & Mesos 模式
Mesos 是 Apache 下的开源分布式资源管理框架,它被称为是分布式系统的内核,在Twitter 得到广泛使用,管理着 Twitter 超过 30,0000 台服务器上的应用部署,但是在国内,依然使用着传统的 Hadoop 大数据框架,所以国内使用 Mesos 框架的并不多,但是原理其实都差不多,这里我们就不做过多讲解了。
第4章 Spark 运行架构
4.1 运行架构
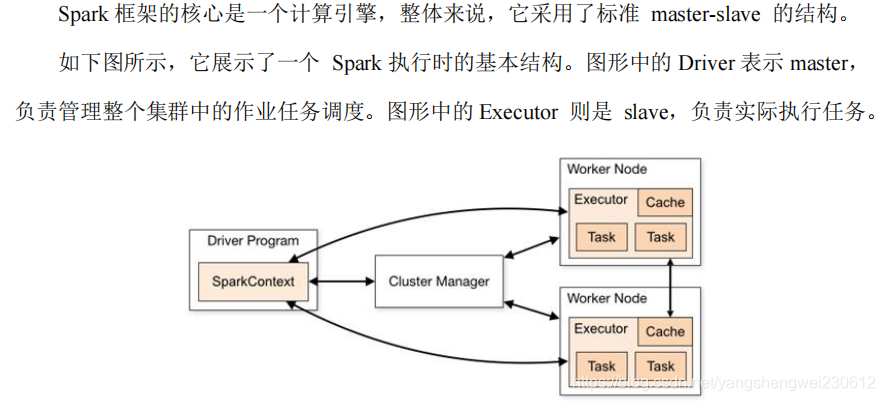
4.2 核心组件( Driver和Executor)


4.2.3 Master & Worker
4.2.4 ApplicationMaster

4.3 核心概念
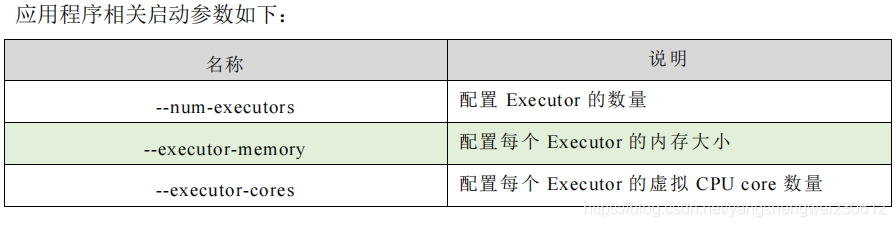
4.3.1 Executor 与 Core

4.3.2 并行度(Parallelism)

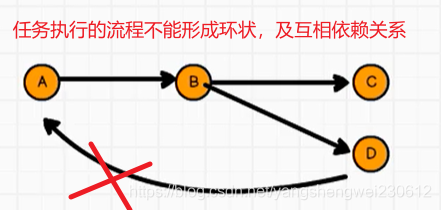
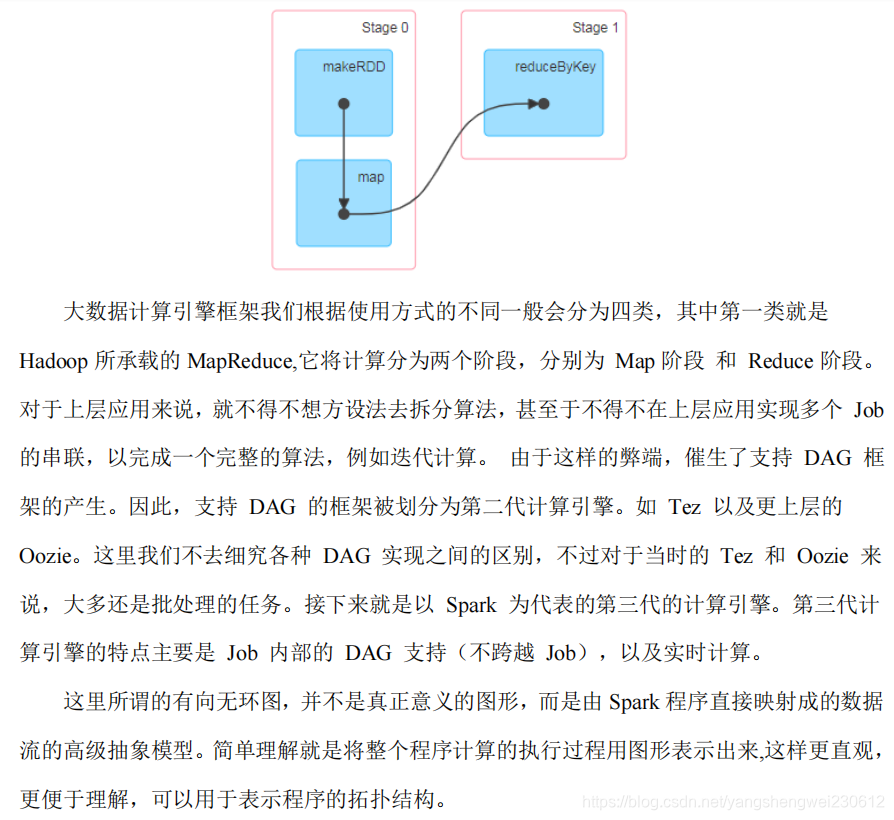
4.3.3 有向无环图(DAG)
任务调度不能形成环状依赖

4.4 提交流程
提交流程主要是两个部分:资源的申请计算的准备,当计算和资源都准备好了,把计算发给资源运行即可

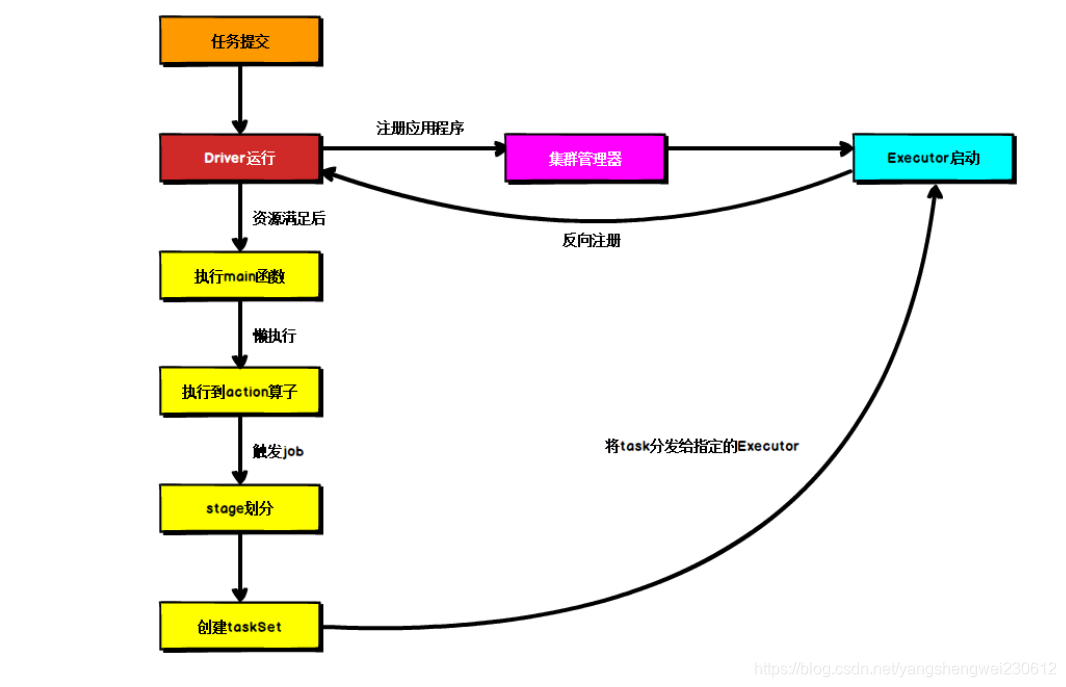

4.2.1 Yarn Client 模式


4.2.2 Yarn Cluster 模式

第5章 Spark 核心编程

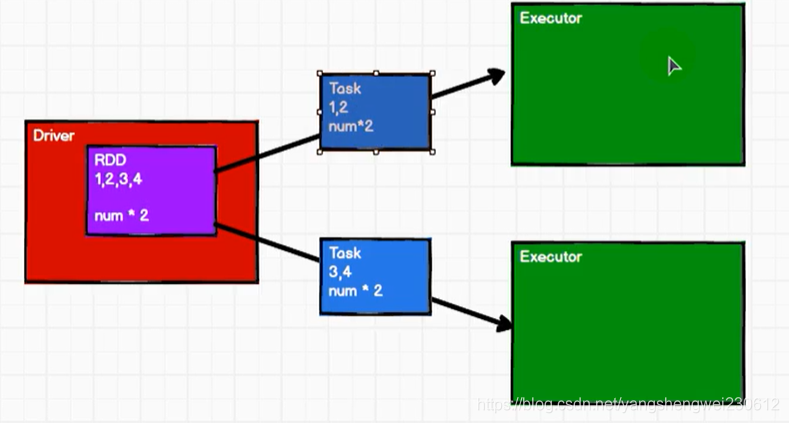
简单的分布式计模型架构:
Driver将任务分发给Executor计算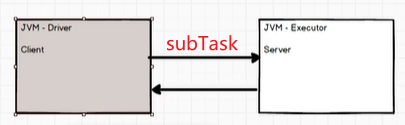 分发给多个Executor
分发给多个Executor 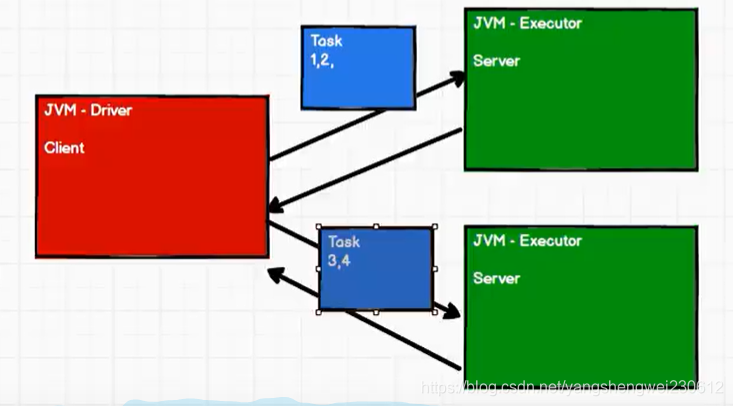

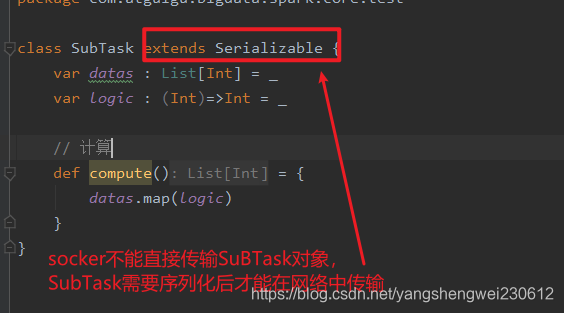
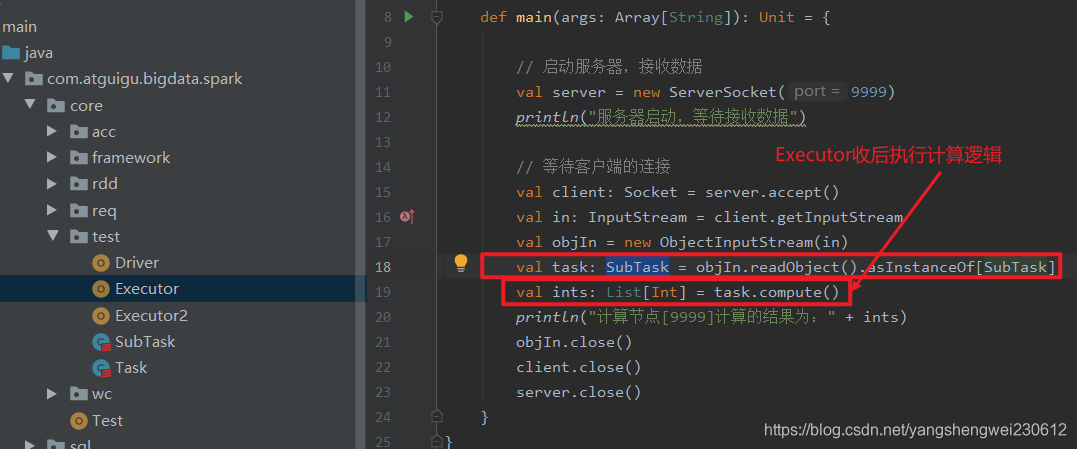 任务对象,包含数据和计算逻辑
任务对象,包含数据和计算逻辑 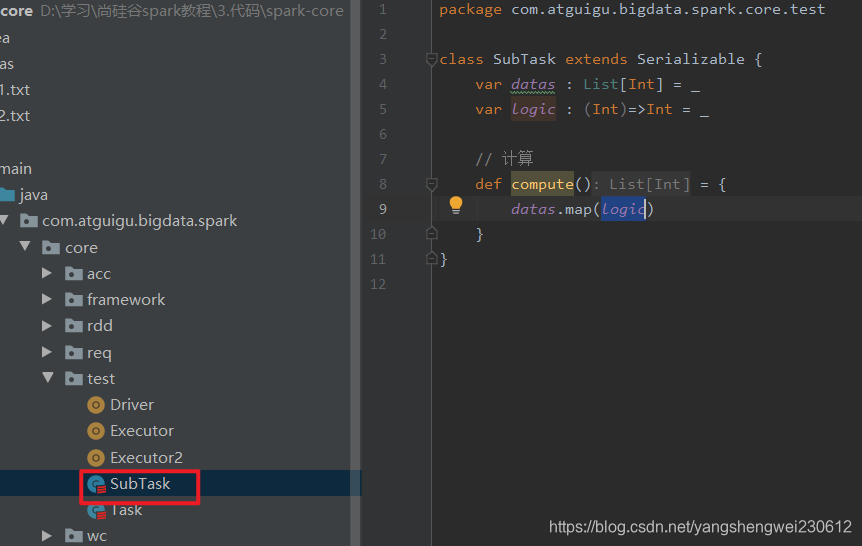
5.1 RDD
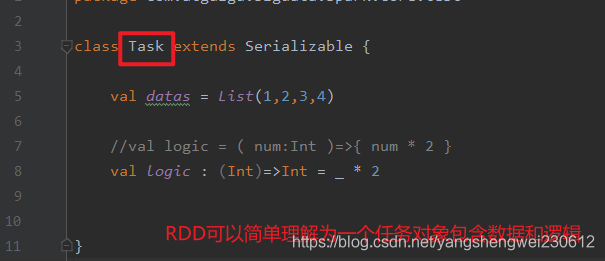
RDD 在整个流程中主要用于将逻辑进行封装,并生成 Task 发送给Executor 节点执行计算,及RDD就是一种把数据和逻辑准备好一种结构。
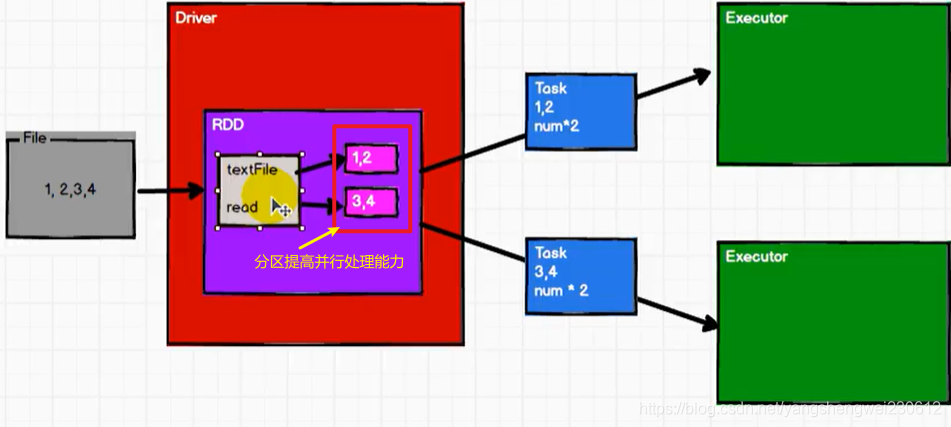
5.1.1 什么是 RDD
说RDD是最小计算单元是因为,一般项目的逻辑计算都是相对复杂的,为了方便编码和以后的扩展,把复杂的逻辑拆分开来就形成了一个个RDD
// 创建 Spark 运行配置对象val sparkConf = new SparkConf().setMaster("local[*]").setAppName("WordCount")// 创建 Spark 上下文环境对象(连接对象)val sc : SparkContext = new SparkContext(sparkConf)// 读取文件数据val fileRDD: RDD[String] = sc.textFile("input/word.txt")// 将文件中的数据进行分词val wordRDD: RDD[String] = fileRDD.flatMap( _.split(" ") )// 转换数据结构 word => (word, 1)val word2OneRDD: RDD[(String, Int)] = wordRDD.map((_,1))// 将转换结构后的数据按照相同的单词进行分组聚合val word2CountRDD: RDD[(String, Int)] = word2OneRDD.reduceByKey(_+_)// 将数据聚合结果采集到内存中val word2Count: Array[(String, Int)] = word2CountRDD.collect()// 打印结果word2Count.foreach(println)//关闭 Spark 连接sc.stop() 一次map/atMap就是一个RDD



5.1.2 核心属性
* Internally, each RDD is characterized by five main properties: * * - A list of partitions * - A function for computing each split * - A list of dependencies on other RDDs * - Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned) * - Optionally, a list of preferred locations to compute each split on (e.g. block locations for * an HDFS file)
➢ 分区列表
分区是为了提高计算执行的时的并行度,类似kafka分区是为提高消费的并行度 RDD 数据结构中存在分区列表,用于执行任务时并行计算,是实现分布式计算的重要属性。/** * Implemented by subclasses to return the set of partitions in this RDD. This method will only * be called once, so it is safe to implement a time-consuming computation in it. * * The partitions in this array must satisfy the following property: * `rdd.partitions.zipWithIndex.forall { case (partition, index) => partition.index == index }` */ protected def getPartitions: Array[Partition] ➢ 分区计算函数
每个分区的计算逻辑 Spark 在计算时,是使用分区函数对每一个分区进行计算/** * :: DeveloperApi :: * Implemented by subclasses to compute a given partition. */ @DeveloperApi def compute(split: Partition, context: TaskContext): Iterator[T]
➢ RDD 之间的依赖关系
RDD 是计算模型的封装,当需求中需要将多个计算模型进行组合时,就需要将多个 RDD 建立依赖关系/** * Implemented by subclasses to return how this RDD depends on parent RDDs. This method will only * be called once, so it is safe to implement a time-consuming computation in it. */ protected def getDependencies: Seq[Dependency[_]] = deps
➢ 分区器(可选)
RDD 数据分区策略选择器 当数据为 KV 类型数据时,可以通过设定分区器自定义数据的分区/** * Optionally overridden by subclasses to specify placement preferences. */ protected def getPreferredLocations(split: Partition): Seq[String] = Nil /** Optionally overridden by subclasses to specify how they are partitioned. */ @transient val partitioner: Option[Partitioner] = None
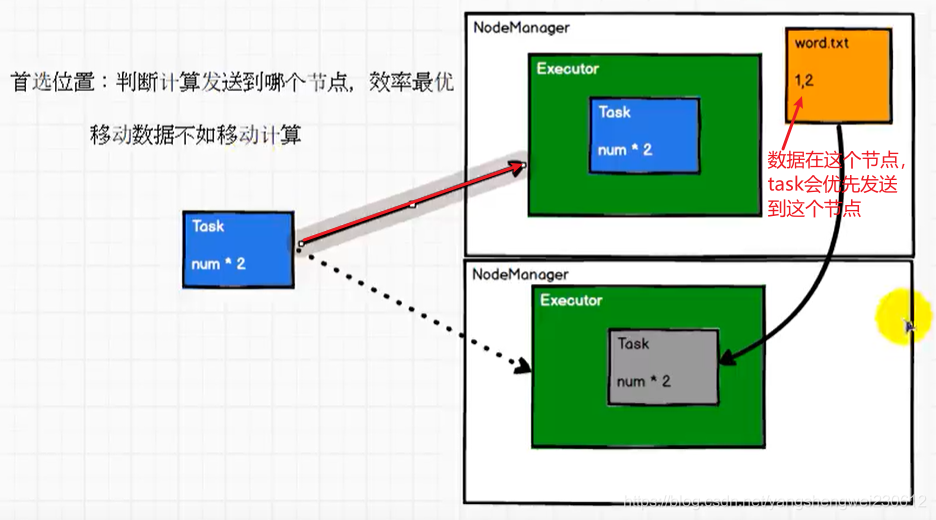
➢ 首选位置(可选)
首选位置及task任务优先选择分配的节点的位置
就近原则 计算数据时,可以根据计算节点的状态选择不同的节点位置进行计算/** * Optionally overridden by subclasses to specify placement preferences. */ protected def getPreferredLocations(split: Partition): Seq[String] = Nil
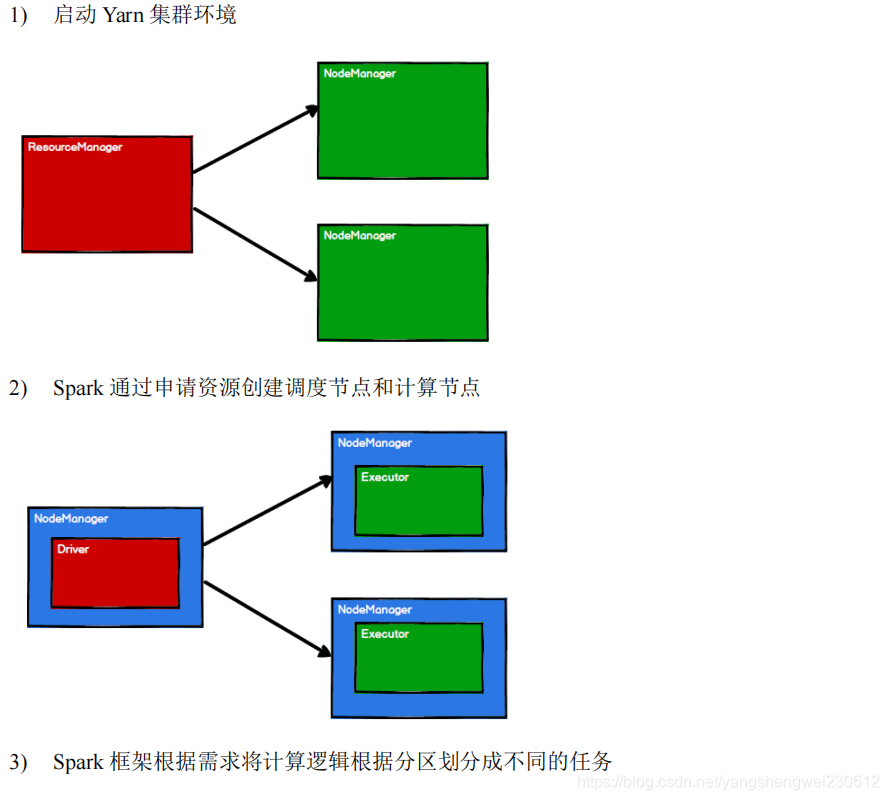
5.1.3 执行原理

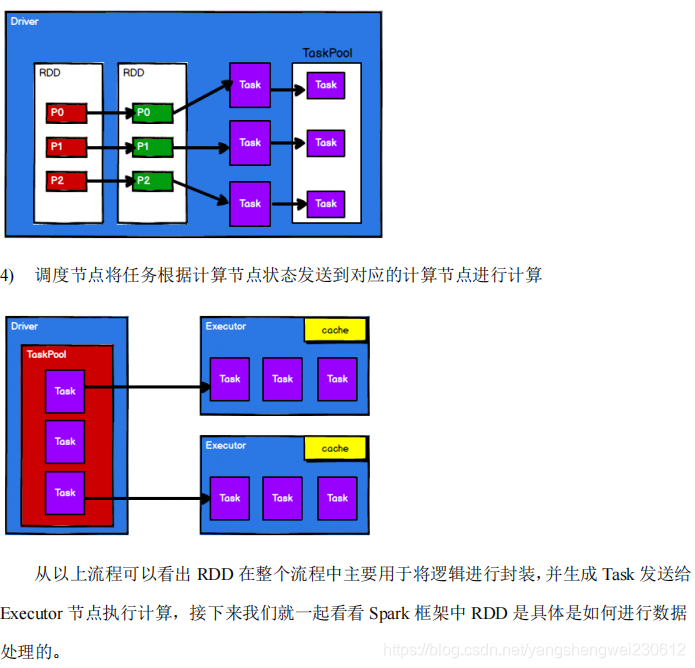
5.1.4 基础编程
5.1.4.1 RDD 创建
在 Spark 中创建 RDD 的创建方式可以分为四种:
- 从集合(内存)中创建 RDD 从集合中创建 RDD,Spark 主要提供了两个方法:parallelize 和 makeRDD

import org.apache.spark.rdd.RDDimport org.apache.spark.{ SparkConf, SparkContext}object Spark01_RDD_Memory { def main(args: Array[String]): Unit = { // TODO 准备环境 val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD") val sc = new SparkContext(sparkConf) // TODO 创建RDD // 从内存中创建RDD,将内存中集合的数据作为处理的数据源 val seq = Seq[Int](1,2,3,4) // parallelize : 并行 //val rdd: RDD[Int] = sc.parallelize(seq) // makeRDD方法在底层实现时其实就是调用了rdd对象的parallelize方法。 // RDD的并行度 & 分区 // makeRDD方法可以传递第二个参数,这个参数表示分区的数量 // 第二个参数可以不传递的,那么makeRDD方法会使用默认值 : defaultParallelism(默认并行度) // scheduler.conf.getInt("spark.default.parallelism", totalCores) // spark在默认情况下,从配置对象中获取配置参数:spark.default.parallelism // 如果获取不到,那么使用totalCores属性,这个属性取值为当前运行环境的最大可用核数 val rdd: RDD[Int] = sc.makeRDD(seq) rdd.collect().foreach(println) // TODO 关闭环境 sc.stop() }} 从底层代码实现来讲,makeRDD 方法其实就是 parallelize 方法
def makeRDD[T: ClassTag]( seq: Seq[T], numSlices: Int = defaultParallelism): RDD[T] = withScope { parallelize(seq, numSlices)} - 从外部存储(文件)创建 RDD 由外部存储系统的数据集创建 RDD 包括:本地的文件系统,所有 Hadoop 支持的数据集, 比如 HDFS、HBase 等。
package com.atguigu.bigdata.spark.core.rdd.builderimport org.apache.spark.rdd.RDDimport org.apache.spark.{ SparkConf, SparkContext}object Spark02_RDD_File { def main(args: Array[String]): Unit = { // TODO 准备环境 val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD") val sc = new SparkContext(sparkConf) // TODO 创建RDD // 从文件中创建RDD,将文件中的数据作为处理的数据源 // path路径默认以当前环境的根路径为基准。可以写绝对路径,也可以写相对路径 //sc.textFile("D:\\mineworkspace\\idea\\classes\\atguigu-classes\\datas\\1.txt") //val rdd: RDD[String] = sc.textFile("datas/1.txt") // path路径可以是文件的具体路径,也可以目录名称 // textFile : 以行为单位来读取数据,读取的数据都是字符串 val rdd = sc.textFile("datas/*") // wholeTextFiles : 以文件为单位读取数据 // 读取的结果表示为元组,第一个元素表示文件路径,第二个元素表示文件内容 // val rdd = sc.wholeTextFiles("datas/*") // path路径还可以使用通配符 * //val rdd = sc.textFile("datas/1*.txt") // path还可以是分布式存储系统路径:HDFS // val rdd = sc.textFile("hdfs://linux1:8020/test.txt") rdd.collect().foreach(println) // TODO 关闭环境 sc.stop() }} - 从其他 RDD 创建 主要是通过一个 RDD 运算完后,再产生新的 RDD。详情请参考后续章节
- 直接创建 RDD(new) 使用 new 的方式直接构造 RDD,一般由 Spark 框架自身使用。
5.1.4.2 RDD 并行度与分区
默认情况下,Spark 可以将一个作业切分多个任务后,发送给 Executor 节点并行计算,而能 够并行计算的任务数量我们称之为并行度。这个数量可以在构建 RDD 时指定。记住,这里的并行执行的任务数量,并不是指的切分任务的数量,不要混淆了。
集合(内存)分区:
// RDD的并行度 & 分区 // makeRDD方法可以传递第二个参数,这个参数表示分区的数量 // 第二个参数可以不传递的,那么makeRDD方法会使用默认值 : defaultParallelism(默认并行度) // scheduler.conf.getInt(“spark.default.parallelism”, totalCores) // spark在默认情况下,从配置对象中获取配置参数:spark.default.parallelism // 如果获取不到,那么使用totalCores属性,这个属性取值为当前运行环境的最大可用核数 val rdd = sc.makeRDD(List(1,2,3,4),2)//集合中的数据划分成2个分区val rdd = sc.makeRDD(List(1,2,3,4),2)//经集合中的数据划分成2个分区
// val rdd = sc.makeRDD(List(1,2,3,4))//使用默认并行度,配置的使用配置的值,不配置的话使用系统cpu的核数
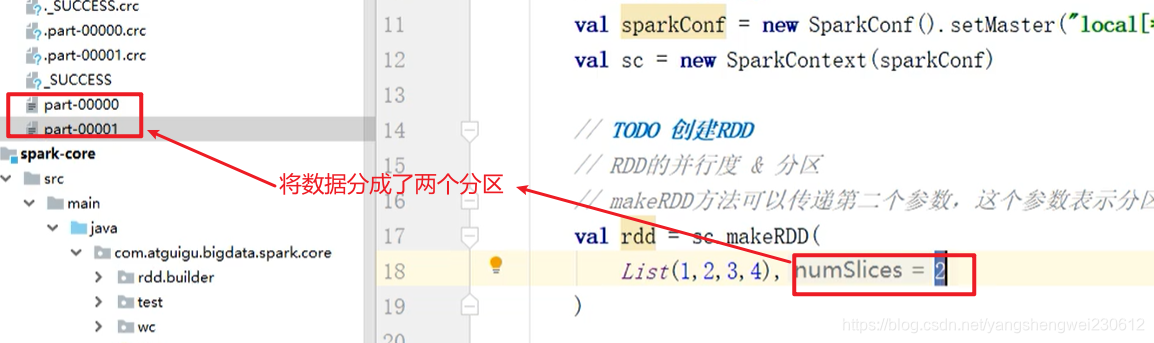

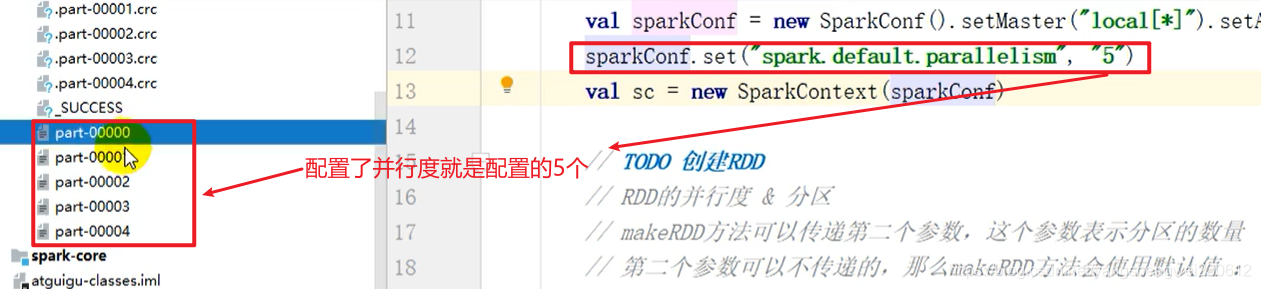
package com.atguigu.bigdata.spark.core.rdd.builderimport org.apache.spark.rdd.RDDimport org.apache.spark.{ SparkConf, SparkContext}object Spark01_RDD_Memory_Par { def main(args: Array[String]): Unit = { // TODO 准备环境 val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD") sparkConf.set("spark.default.parallelism", "5")//设置5个并行度计算 val sc = new SparkContext(sparkConf) // TODO 创建RDD // RDD的并行度 & 分区 // makeRDD方法可以传递第二个参数,这个参数表示分区的数量 // 第二个参数可以不传递的,那么makeRDD方法会使用默认值 : defaultParallelism(默认并行度) // scheduler.conf.getInt("spark.default.parallelism", totalCores) // spark在默认情况下,从配置对象中获取配置参数:spark.default.parallelism // 如果获取不到,那么使用totalCores属性,这个属性取值为当前运行环境的最大可用核数 val rdd = sc.makeRDD(List(1,2,3,4),2)//集合中的数据划分成2个分区 // val rdd = sc.makeRDD(List(1,2,3,4))//使用默认并行度, // 将处理的数据保存成分区文件 rdd.saveAsTextFile("D:\\data\\output") // TODO 关闭环境 sc.stop() }} 读取内存数据时,数据可以按照并行度的设定进行数据的分区操作,数据分区规则的
Spark 核心源码如下:def positions(length: Long, numSlices: Int): Iterator[(Int, Int)] = { (0 until numSlices).iterator.map { i => val start = ((i * length) / numSlices).toInt val end = (((i + 1) * length) / numSlices).toInt (start, end) } 读取文件分区:
Spark读取文件,底层其实使用的就是Hadoop的读取方式
 读取文件数据时,数据是按照 Hadoop 文件读取的规则进行切片分区,而切片规则和数 据读取的规则有些差异,具体 Spark 核心源码如下
读取文件数据时,数据是按照 Hadoop 文件读取的规则进行切片分区,而切片规则和数 据读取的规则有些差异,具体 Spark 核心源码如下 public InputSplit[] getSplits(JobConf job, int numSplits) throws IOException { long totalSize = 0; // compute total size for (FileStatus file: files) { // check we have valid files if (file.isDirectory()) { throw new IOException("Not a file: "+ file.getPath()); } totalSize += file.getLen(); } long goalSize = totalSize / (numSplits == 0 ? 1 : numSplits); long minSize = Math.max(job.getLong(org.apache.hadoop.mapreduce.lib.input. FileInputFormat.SPLIT_MINSIZE, 1), minSplitSize); ... for (FileStatus file: files) { ... if (isSplitable(fs, path)) { long blockSize = file.getBlockSize(); long splitSize = computeSplitSize(goalSize, minSize, blockSize); ... } protected long computeSplitSize(long goalSize, long minSize, long blockSize) { return Math.max(minSize, Math.min(goalSize, blockSize)); } // 1. 数据以行为单位进行读取
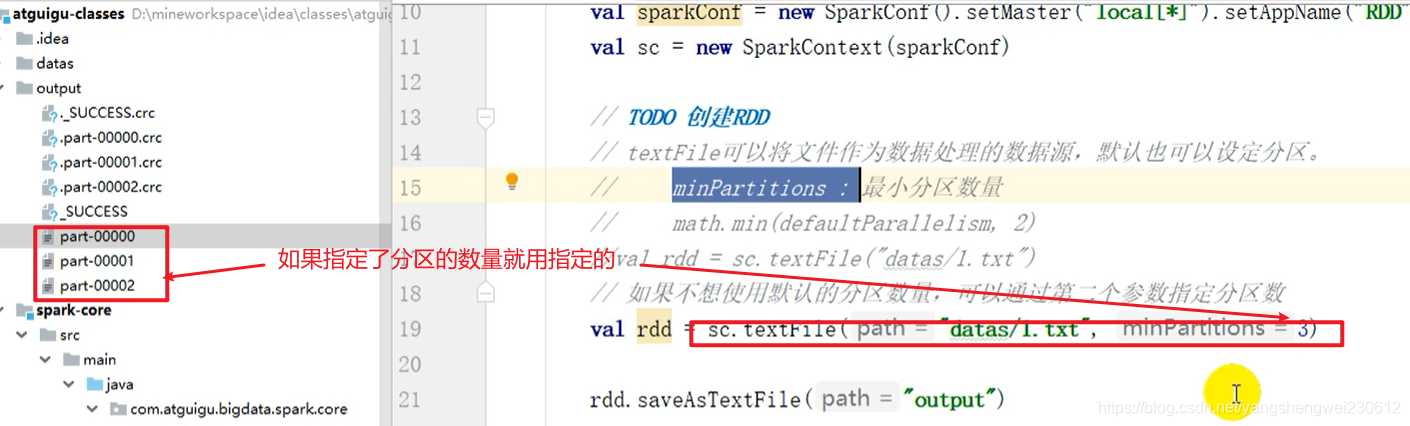
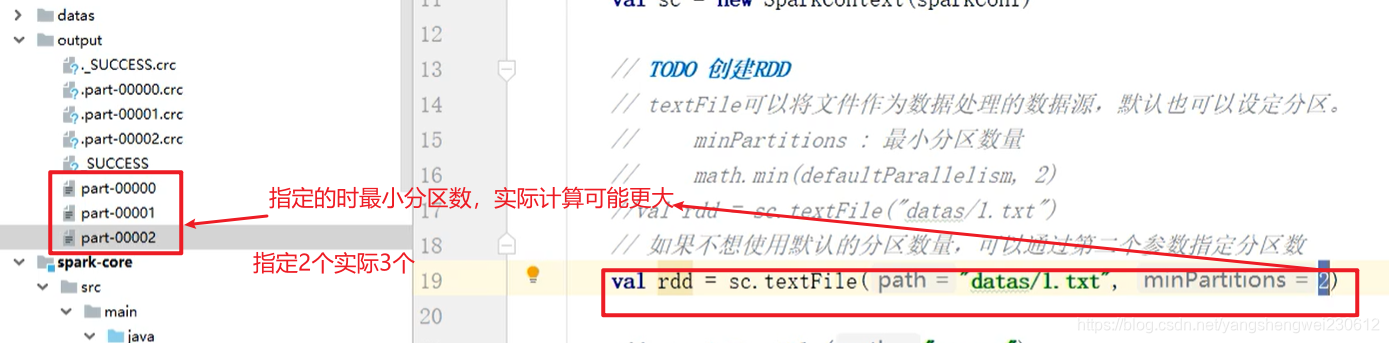
// spark读取文件,采用的是hadoop的方式读取,所以一行一行读取,和字节数没有关系 // 2. 数据读取时以偏移量为单位,偏移量不会被重复读取 /* 1@@ => 012 2@@ => 345 3 => 6package com.atguigu.bigdata.spark.core.rdd.builderimport org.apache.spark.{ SparkConf, SparkContext}object Spark02_RDD_File_Par1 { def main(args: Array[String]): Unit = { // TODO 准备环境 val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD") val sc = new SparkContext(sparkConf) // TODO 创建RDD // TODO 数据分区的分配 // 1. 数据以行为单位进行读取 // spark读取文件,采用的是hadoop的方式读取,所以一行一行读取,和字节数没有关系 // 2. 数据读取时以偏移量为单位,偏移量不会被重复读取 /* 1@@ => 012 2@@ => 345 3 => 6 */ // 3. 数据分区的偏移量范围的计算 // 0 => [0, 3] => 12 // 1 => [3, 6] => 3 // 2 => [6, 7] => // 【1,2】,【3】,【】 val rdd = sc.textFile("datas/1.txt", 2) rdd.saveAsTextFile("output") // TODO 关闭环境 sc.stop() }} // 如果数据源为多个文件,那么计算分区时以文件为单位进行分区 //及先对文件1分区,再对文件2分区 val rdd = sc.textFile("datas/*", 2) 转载地址:https://blog.csdn.net/yangshengwei230612/article/details/115276743 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
