Kafka快速入门+kafka安装






 get /brokers/topics/hello/partitions/0/state
get /brokers/topics/hello/partitions/0/state










 5). 生成数据/发布消息
5). 生成数据/发布消息 
发布日期:2021-06-28 20:55:07
浏览次数:2
分类:技术文章
本文共 7785 字,大约阅读时间需要 25 分钟。
Kafka快速入门+kafka安装
- KAFKA实际上是一个消息队列框架
Kafka快速入门
消息系统
 - 队列
- 队列
- 消息队列及, 队列中放的是消息


Kafka简介

- 由多台kafka的服务器构成kafka集群,来对消息进行管理
- 每一台kafka的服务器又称之为一个节点(节点在kafka中叫Broker)
- 每一个节点对应一个Broker
- kafka的消息是分主题(topic)来存储的,每个主题(topic)用来存储不同的消息。发布消息要指定主题(topic)来存储
- 取消息时也要指定主题
- 一个节点可以包含多个主题(Topic)


- 分区是为了分布式存储
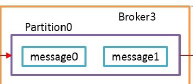
- Message 是放在对应的分区里面的
- Consumer Group:

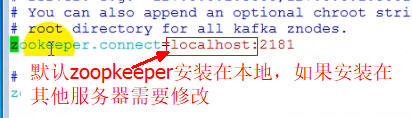
- Zookeeper:kafka的消息(,Message)身并不是存在Zookeeper,Zookeeper用于存储有kafaka的元数据信息(如:kafka集群有多少个节点(Broker)、主题(Topic)的名称等),所以kafaka依赖于Zookeeper,需要搭建Zookeeper服务器
- 什么是元数据 任何文件系统中的数据分为数据和元数据。数据是指普通文件中的实际数据,而元 数据指用来描述一个文件的特征的系统数据,诸如访问权限、文件拥有者以及文件数据 块的分布信息(inode…)等等。在集群文件系统中,分布信息包括文件在磁盘上的位置以及磁盘在集群中的位置。用户需要操作一个文件必须首先得到它的元数据,才能定位到文件的位置并且得到文件的内容或相关属性。
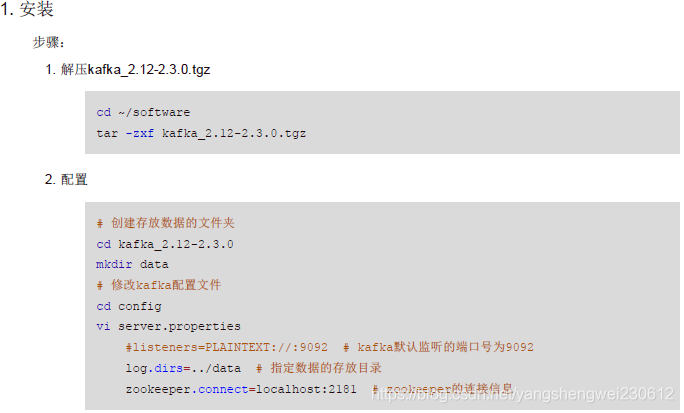
安装Kafka
Kafka一般安装在linux服务器
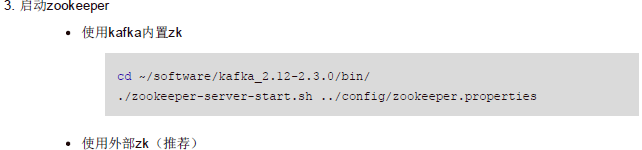
- 如果没有安装zoopkeeper可以用kafka内内置的zoopkeeper,但一般实际项目中都是用自己安装的zookeeper
- 如果使用内置zoopkeeper执行如下命令:
> bin/zookeeper-server-start.sh config/zookeeper.properties
-
如果自己安装指向如下步骤:
-
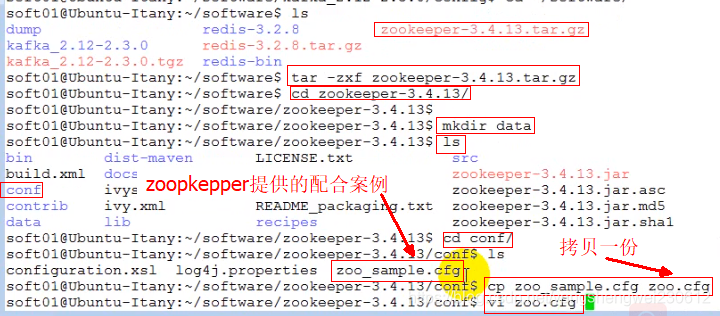
zoopkeeper启动配置
-
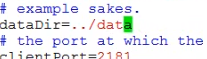
在配置文件中可以看到zoopkeeper数据默认存放的位置

-
可以根据需要修改
 == 注意:以下步骤最好进入root 权限,使用命令 su - 进入root ==
== 注意:以下步骤最好进入root 权限,使用命令 su - 进入root == -
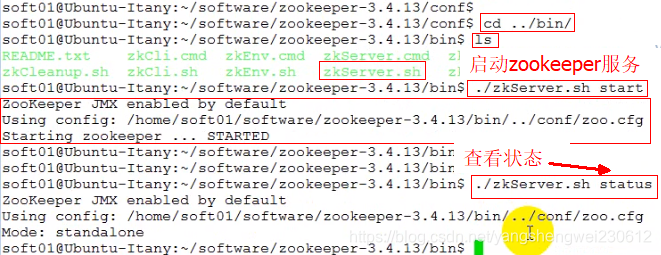
修改好配置文件后启动zookeeper服务,启动后如果使用JPS看不到启动的zookeeper线程,或者使用 ./zkServer.sh status提示如下错入,说明你需要使用root权限


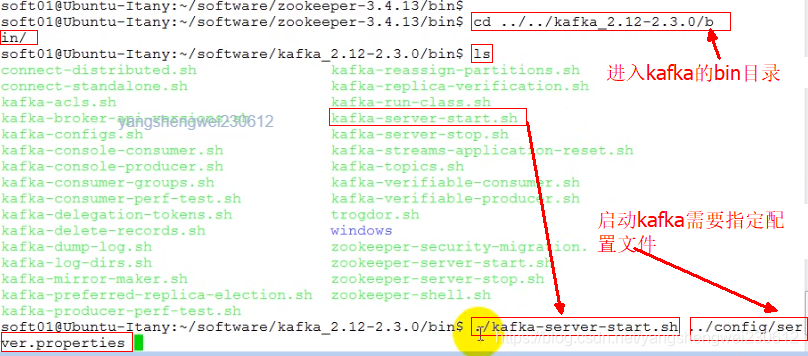
- 用以上方式直接启动kafka会以前台的方式运行,阻塞其他进程的运行,以下两种方式可以实现kafka后运行
- 利用kafka提供后台运行方法

- 利用linux自身提供的方法

- 启动后使用jps 查看进程,jps是jdk提供的用来查看所有java进程的命令

- 依然保持路径在kafka的bin文件下
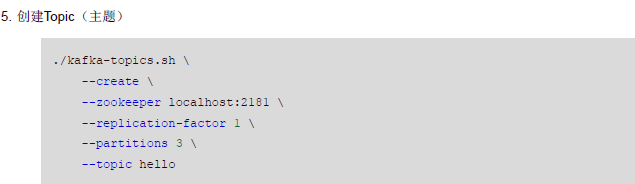
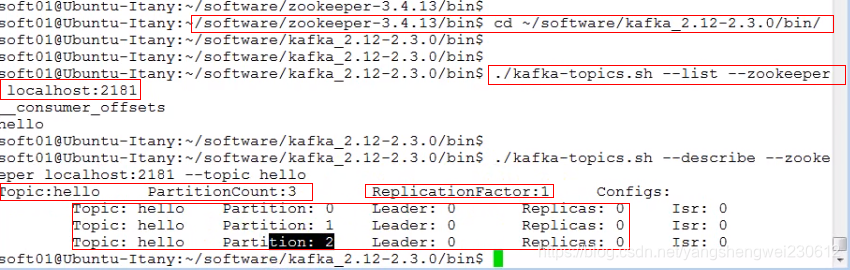
>./kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 3 --topic hellO

./kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 3 --topic hello

./kafka-topics.sh --list --zookeeper localhost:2181./kafka-topics.sh --delete --zookeeper localhost:2181 --topic hello
- 主题创建完成后,生产者就可以往topic放里发布消息了
- kafka为了方便测试,提供了一个模拟的生产者和消费者
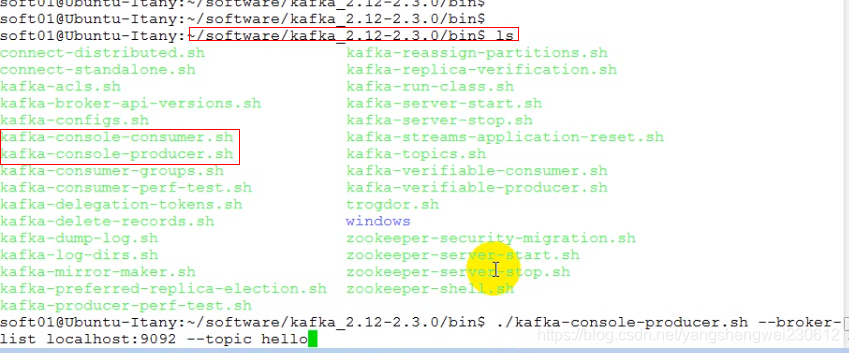

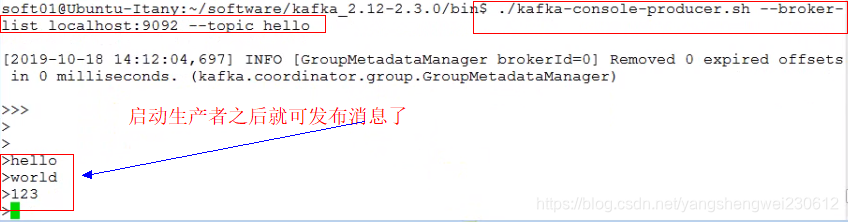
./kafka-console-producer.sh --broker-list localhost:9092 --topic hello
- 使用FinalShell连接服务器,和producer为同一台服务器

./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic hello --from-beginning
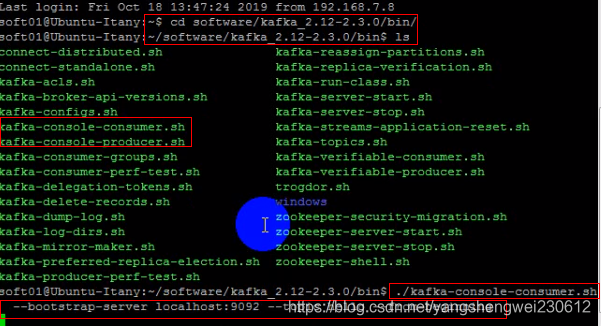
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic hello --from-beginningng
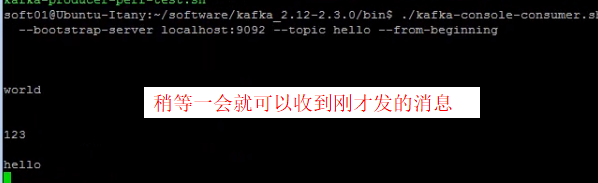
- 现在生产者发布消息,订阅了hello主题的消费者立刻就可以收到,消费者可以有多个

- 查看data数据存放目录:


get /brokers/topics/hello/partitions/0/state - 查看zookeeper中的内容:get /brokers/topics/hello/partitions/0/state




- 一般不通过登录zookeeper来查看元数据,而是使用kafka提供的一些工具命令

- 在配置文件中修改添加topic删除功能

#是否可以删除topic,默认为falsedelete.topic.enable=true
- 启动后会给出topic删除功能开启提示日志

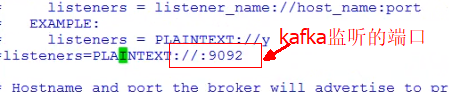
Kafka配置文件
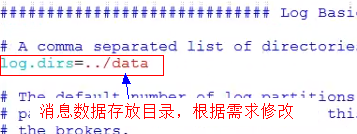
############################# Server Basics ############################## broker的id,值为整数,且必须唯一,在一个集群中不能重复broker.id=0############################# Socket Server Settings ############################## kafka默认监听的端口为9092#listeners=PLAINTEXT://:9092# 处理网络请求的线程数量,默认为3个num.network.threads=3# 执行磁盘IO操作的线程数量,默认为8个num.io.threads=8# socket服务发送数据的缓冲区大小,默认100KBsocket.send.buffer.bytes=102400# socket服务接受数据的缓冲区大小,默认100KBsocket.receive.buffer.bytes=102400# socket服务所能接受的一个请求的最大大小,默认为100Msocket.request.max.bytes=104857600############################# Log Basics ############################## kafka存储消息数据的目录log.dirs=../data# 每个topic默认的partition数量num.partitions=1# 在启动时恢复数据和关闭时刷新数据时每个数据目录的线程数量num.recovery.threads.per.data.dir=1############################# Log Flush Policy ############################## 消息刷新到磁盘中的消息条数阈值#log.flush.interval.messages=10000# 消息刷新到磁盘中的最大时间间隔#log.flush.interval.ms=1000############################# Log Retention Policy ############################## 日志保留小时数,超时会自动删除,默认为7天log.retention.hours=168# 日志保留大小,超出大小会自动删除,默认为1G#log.retention.bytes=1073741824# 日志分片策略,单个日志文件的大小最大为1G,超出后则创建一个新的日志文件log.segment.bytes=1073741824# 每隔多长时间检测数据是否达到删除条件log.retention.check.interval.ms=300000############################# Zookeeper ############################## Zookeeper连接信息,如果是zookeeper集群,则以逗号隔开zookeeper.connect=localhost:2181# 连接zookeeper的超时时间zookeeper.connection.timeout.ms=6000## Kafka集群## SpringBoot集成Kafka# 是否可以删除topic,默认为falsedelete.topic.enable=true
kafka集群搭建
- 如果只有一台电脑,我们可以模拟搭建集群服务器:可以在一台主机上启动多个zk服务,配置使用不同的端口即可。
1. 搭建zk集群
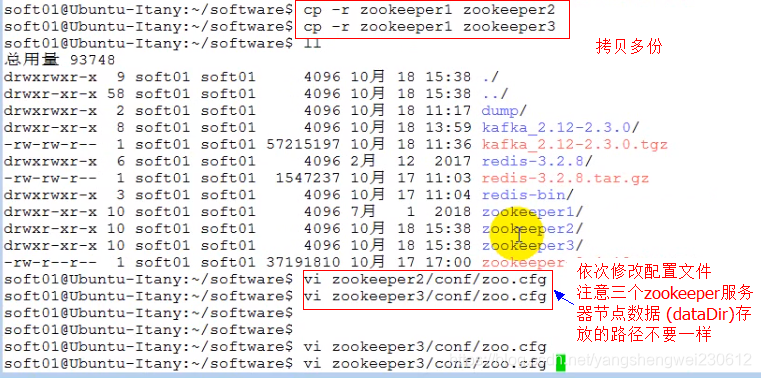
- 搭建zk集群 在一台主机上启动多个zk服务,配置使用不同的端口 步骤: 1). 拷贝多个zk目录 zookeeper1、zookeeper2、zookeeper3 2). 分别配置每个zk
- 修改zookeeper配置文件
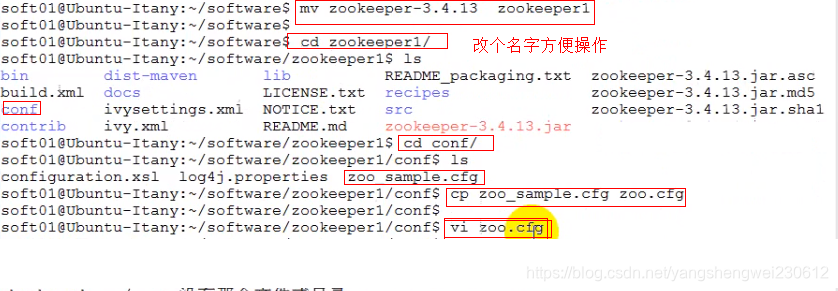
- 修改zookeeper配置文件
vi zookeeper1/conf/zoo.cfgclientPort=2181server.1=192.168.2.153:6661:7771server.2=192.168.2.153:6662:7772server.3=192.168.2.153:6663:7773echo 1 > zookeeper1/data/myidvi zookeeper2/conf/zoo.cfgclientPort=2182server.1=192.168.2.153:6661:7771server.2=192.168.2.153:6662:7772server.3=192.168.2.153:6663:7773echo 2 > zookeeper2/data/myidvi zookeeper3/conf/zoo.cfgclientPort=2183server.1=192.168.2.153:6661:7771server.2=192.168.2.153:6662:7772server.3=192.168.2.153:6663:7773echo 3 > zookeeper3/data/myid

3). 启动zk集群
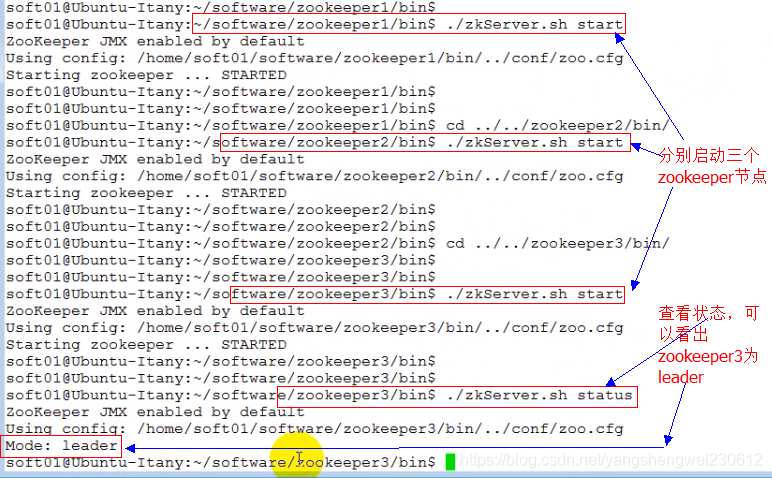
2. 搭建Kafka集群
步骤: 1). 拷贝多个kafka目录 kafka1、kafka2、kafka3 2). 分别配置每个kafka)
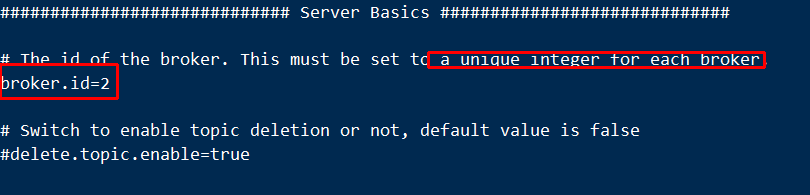
- 复制kafka2和kafka3




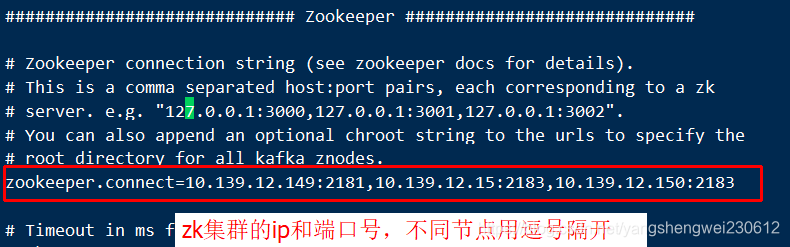
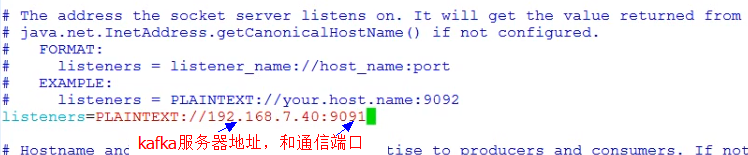
vi kafka1/config/server.propertiesbroker.id=1listeners=PLAINTEXT://192.168.2.153:9091zookeeper.connect=192.168.2.153:2181,192.168.2.153:2182,192.168.2.153:2183vi kafka2/config/server.propertiesbroker.id=2listeners=PLAINTEXT://192.168.2.153:9092zookeeper.connect=192.168.2.153:2181,192.168.2.153:2182,192.168.2.153:2183vi kafka3/config/server.propertiesbroker.id=3listeners=PLAINTEXT://192.168.2.153:9093zookeeper.connect=192.168.2.153:2181,192.168.2.153:2182,192.168.2.153:2183
3). 启动kafka集群
- 进入kafka1的bin目录启动kafka1

- 进入kafka2的bin目录启动kafka2

- 进入kafka3的bin目录启动kafka3

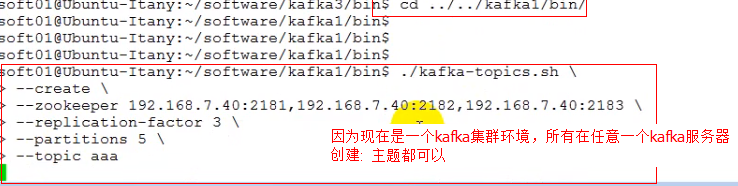
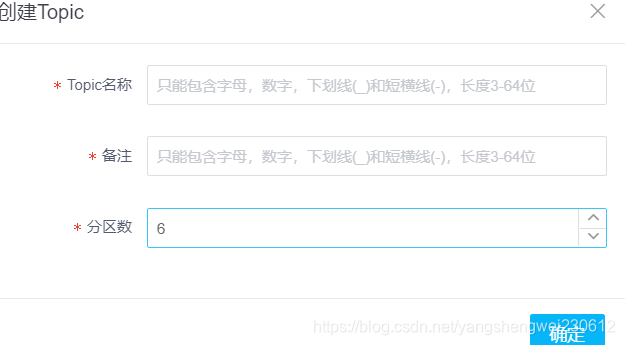
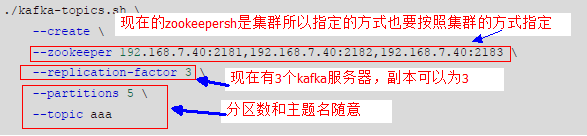
 4). 创建Topic
4). 创建Topic
./kafkatopics.sh \--create\--zookeeper 192.168.7.40:2181,192.168.7.40:2182,192.168.7.40:2183 \--replicationfactor 3 \--partitions 5 \--topic aaa
5). 生成数据/发布消息 - 创建主题后就可以生产数据/消费数据了
./kafkaconsoleproducer.sh --brokerlist 192.168.7.40:9091,192.168.7.40:9092,192.168.7.40:9093 --topic aaa

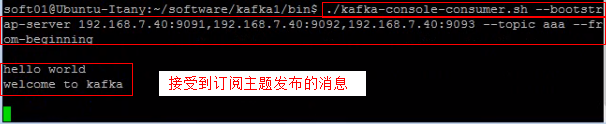
- Ctrl+c 可以退出发不消息 6). 消费数据/订阅消息
- 另开一个控制台窗口
./kafkaconsoleconsumer.sh --bootstrapserver 192.168.7.40:9091,192.168.7.40:9092,192.168.7.40:9093 --topic aaa --from-beginning
-
通过zookeeper查看客户端(kafka集群)的元数据,因为zookeeper也是一个集群所以去任意一个zookeeper服务器查看都可以。
-
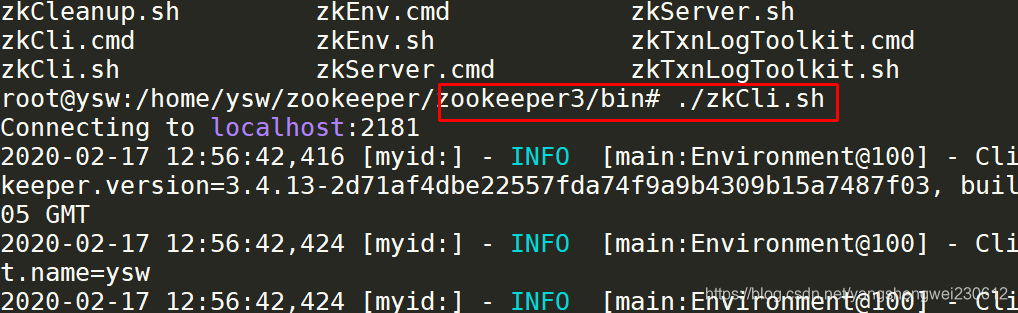



-
查看id为1的broker信息,查看id为3的broker的 信息

-
查看主题(Topic)的分区
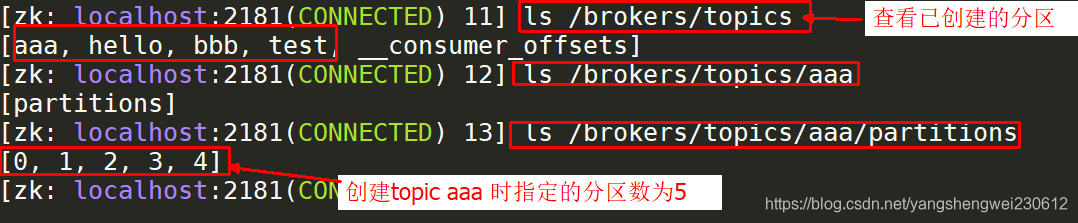
五、SpringBoot集成Kafka
-
- 简介 SpringBoot提供了一个名为springkafka的starter,用于在Spring项目里快速集成kafka
-
- 用法 步骤:
- 创建SpringBoot项目 勾选Spring Web Starter和Spring for Apache Kafka
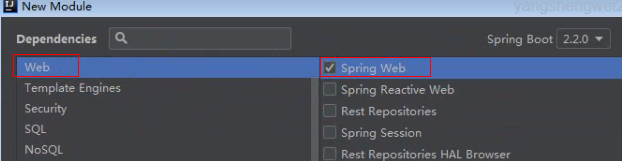
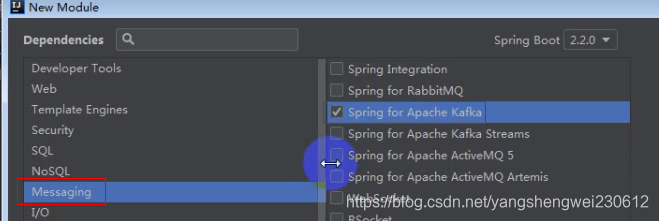
- 创建SpringBoot项目 勾选Spring Web Starter和Spring for Apache Kafka
- 用法 步骤:
-
项目结构
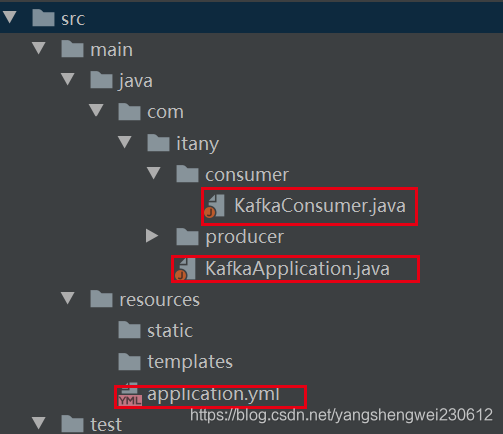
2. 配置kafka,编辑application.yml文件
spring: kafka: # kafka服务器地址(可以多个) bootstrap-servers: 192.168.7.40:9091,192.168.7.40:9092,192.168.7.40:9093 producer: # 每次批量发送消息的数量 batch-size: 65536 buffer-memory: 524288 # key/value的序列化 key-serializer: org.apache.kafka.common.serialization.StringSerializer value-serializer: org.apache.kafka.common.serialization.StringSerializer consumer: # 指定一个默认的组名 group-id: test # key/value的反序列化 key-deserializer: org.apache.kafka.common.serialization.StringDeserializer value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
-
- 创建生产者 import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication;
@RestControllerpublic class KafkaProducer { @Autowired private KafkaTemplate template; /** * 发送消息到Kafka * @param topic 主题,如果主题不存在,会自动创建主题 * @param message 消息 * @return */ @RequestMapping("/sendMsg") public String sendMsg(String topic, String message){ template.send(topic,message);//消息就被发送到kafka服务器上存起来了 return "success"; }} -
- 创建消费者 import org.apache.kafka.clients.consumer.ConsumerRecord; import org.springframework.kafka.annotation.KafkaListener; import org.springframework.stereotype.Component;
@Componentpublic class KafkaConsumer { /** * 订阅指定主题的消息 * @param record 消息记录 */ //通过topics指定订阅的主题 //@KafkaListener(topics = {"aaa","ccc"}) @KafkaListener(topics = { "aaa"}) //加了 @KafkaListener这个注解的方法,可以通过ConsumerRecord获取订阅主题的消息 public void listen(ConsumerRecord record){ // System.out.println(record); System.out.println(record.topic()+":"+record.value()); }} -
- 测试 访问http://localhost:8080/sendMsg?topic=aaa&message=welcome 生产者在aaa主题发布了消息,订阅了aaa主题的消费者就收到了消息
- 在控制中查看 System.out.println(record);

- 只看主题和发送的数据 System.out.println(record.topic()+":"+record.value());

- 访问http://localhost:8080/sendMsg?topic=ccc&message=welcome @KafkaListener(topics = {“aaa”,“ccc”}) 如果ccc主题不存在,kafka服务器会自动创建ccc主题
- 可以在kafka服务器查看相关信息

转载地址:https://blog.csdn.net/yangshengwei230612/article/details/104279935 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
路过按个爪印,很不错,赞一个!
[***.219.124.196]2024年04月13日 17时00分13秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
el-table表格超出部分显示省略号,去掉鼠标悬浮显示
2019-04-29
使用el-table组件加上分页后,多选翻页和查询后仍保持选中状态及回显
2019-04-29
VUE 事件里写了retrun后,后面代码却还是在执行
2019-04-29
微信小程序之去除点击元素出现高亮背景的解决方案
2019-04-29
微信小程序 页面传参数跳转页面
2019-04-29
微信小程序自定义多选
2019-04-29
微信小程序scroll-view底部内容无法完全显示
2019-04-29
微信小程序-在button添加icon和去除button点击时的默认背景色
2019-04-29
微信小程序——自定义组件
2019-04-29
js数组原型方法
2019-04-29
JavaScrip实现点击切换验证码及校验
2019-04-29
Java图形化绘制
2019-04-29
输入/输出流和文件操作
2019-04-29
Java数据库简介
2019-04-29
Java线程简介
2019-04-29
Java网络通信简介
2019-04-29
URL编程简介
2019-04-29
Java集合简介
2019-04-29
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 309231729 位访客
访问时间: 2024-04-30 04:17:01
访问IP: 18.117.81.240
Copyright © 2020 - 2023 blog.css8.cn 京ICP备2021015314号-1
手机版