【Python】爬虫:微博找人页面爬虫(一)
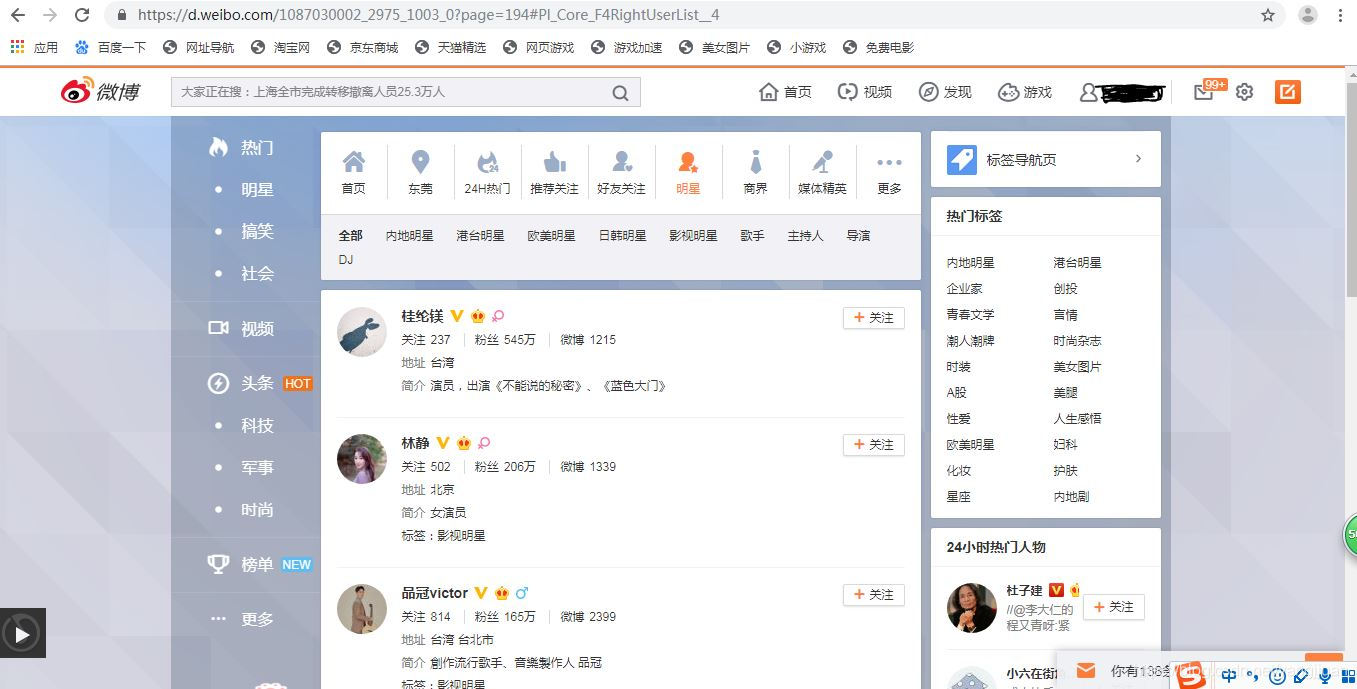 上面有许多分类,所以想爬取从明星后的所有分类,共有50个大类,每个大类下有各自的小类,这次就按大类进行爬取。
上面有许多分类,所以想爬取从明星后的所有分类,共有50个大类,每个大类下有各自的小类,这次就按大类进行爬取。 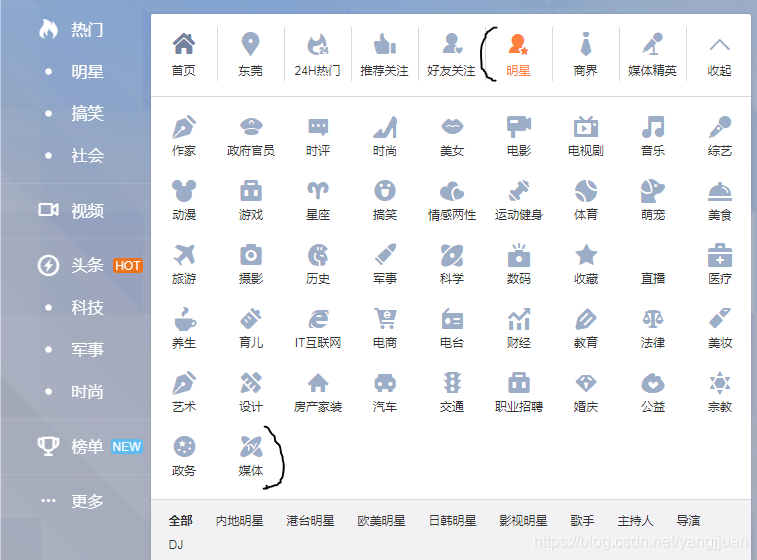 每种大类下面,都包含一定数量的列表页,有的分类下面是空的,不过也不影响。
每种大类下面,都包含一定数量的列表页,有的分类下面是空的,不过也不影响。 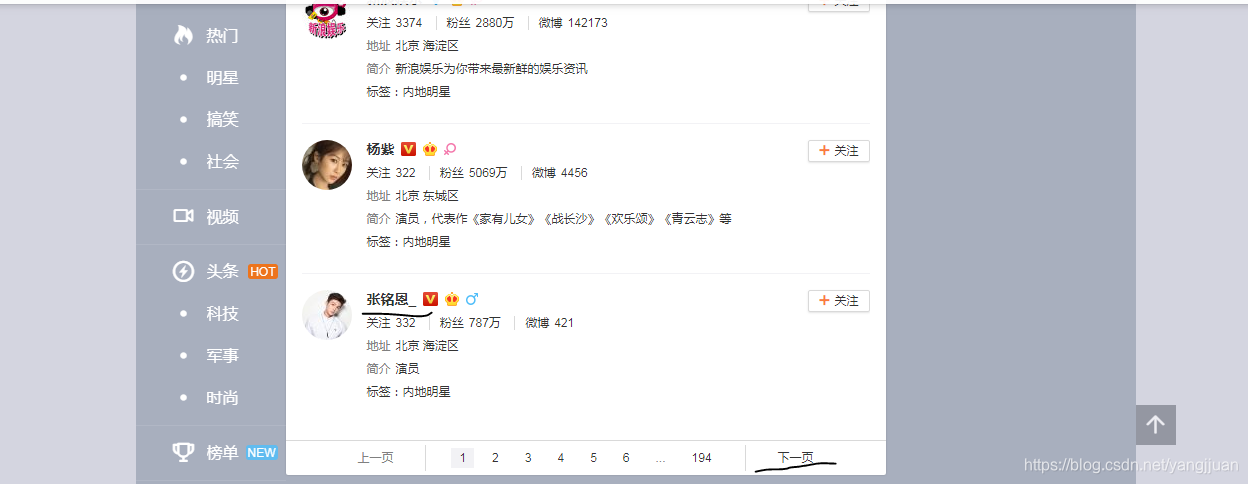 文章页:
文章页: 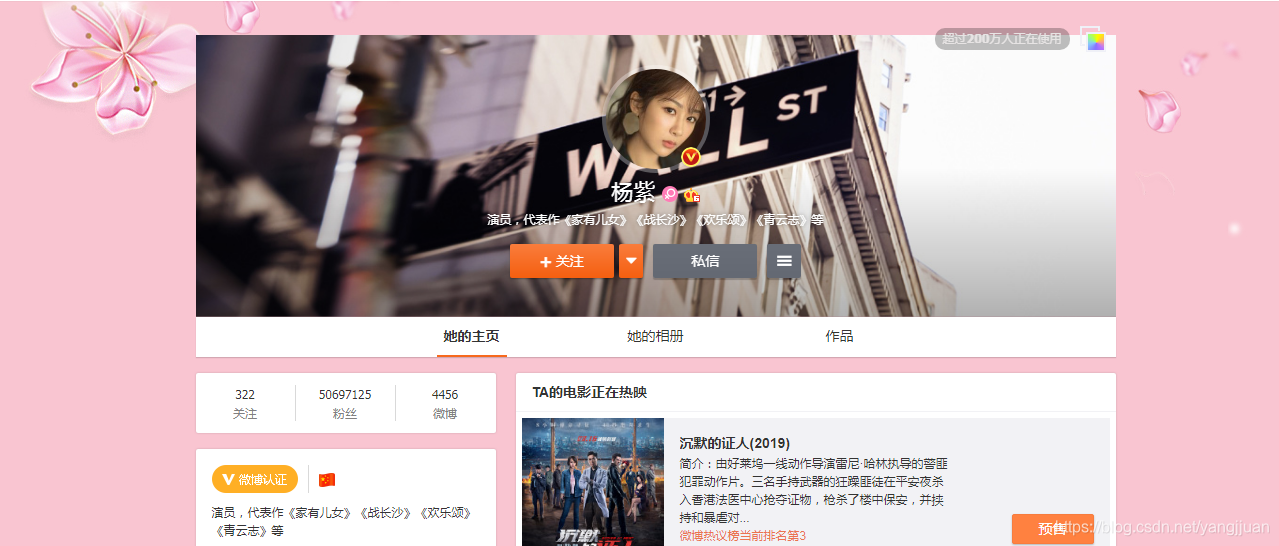 爬取思路:先爬取列表页,再爬取文章页 这里需要维护两个队列(后面会讲到),一个高优先级队highlevel,列用于存储列表页url,一个低优先级队列lowlevel用于存储文章页,两个队列都是FIFO模式。 1,往highlevel中插入起始的列表页url。 2,从highlevel取出url,爬取到当前列表页的下一页url,并存入highlevel,爬取当前列表页中文章页的url,并存入lowlevel中。 3,重复步骤2,直到highlevel中无列表页的url。 4,在步骤3后,就可以从lowlevel中取文章页url,下载页面,解析后存入数据库中。
爬取思路:先爬取列表页,再爬取文章页 这里需要维护两个队列(后面会讲到),一个高优先级队highlevel,列用于存储列表页url,一个低优先级队列lowlevel用于存储文章页,两个队列都是FIFO模式。 1,往highlevel中插入起始的列表页url。 2,从highlevel取出url,爬取到当前列表页的下一页url,并存入highlevel,爬取当前列表页中文章页的url,并存入lowlevel中。 3,重复步骤2,直到highlevel中无列表页的url。 4,在步骤3后,就可以从lowlevel中取文章页url,下载页面,解析后存入数据库中。
发布日期:2021-06-28 20:47:05
浏览次数:2
分类:技术文章
本文共 626 字,大约阅读时间需要 2 分钟。
【Python】爬虫:微博找人页面爬虫(一)
最近想通过爬去微博上大V信息来做爬虫练手,于是,在微博-找人页面,看到有许多分类,并且里面都是些大V,页面:
上面有许多分类,所以想爬取从明星后的所有分类,共有50个大类,每个大类下有各自的小类,这次就按大类进行爬取。 每种大类下面,都包含一定数量的列表页,有的分类下面是空的,不过也不影响。 爬取思路
将爬取的页面分为两类,列表页和文章页,列表页中包含每个文章页的链接,以及列表页的下一页链接。文章页就是每个博主的页面了。
列表页: 文章页: 爬取思路:先爬取列表页,再爬取文章页 这里需要维护两个队列(后面会讲到),一个高优先级队highlevel,列用于存储列表页url,一个低优先级队列lowlevel用于存储文章页,两个队列都是FIFO模式。 1,往highlevel中插入起始的列表页url。 2,从highlevel取出url,爬取到当前列表页的下一页url,并存入highlevel,爬取当前列表页中文章页的url,并存入lowlevel中。 3,重复步骤2,直到highlevel中无列表页的url。 4,在步骤3后,就可以从lowlevel中取文章页url,下载页面,解析后存入数据库中。 需要解决问题
1,模拟登陆,找人页面需要登录微博账号后才可以访问。 2,两个url队列如何维护? 3,文章页面下载,解析,存储?未完待续,后面的博客会有解决上述问题的方法,欢迎大家评论讨论!!!
转载地址:https://blog.csdn.net/yangjjuan/article/details/99171729 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
做的很好,不错不错
[***.243.131.199]2024年04月11日 17时32分40秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
Gulp常用的一些插件
2019-04-29
Docker:基础知识
2019-04-29
mysql知识总结
2019-04-29
C#连接ACCESS
2019-04-29
linux安装VMtools
2019-04-29
移动硬盘插入win10检测到却不显示盘符解决方法
2019-04-29
怎么查看本机S/N序列号和BIOS版本
2019-04-29
ThinkPad X1 Carbon安装win7.
2019-04-29
使用diskgenius将GPT转MBR问题
2019-04-29
Windows账号类型区别
2019-04-29
论文管理工具梳理
2019-04-29
机场净空区
2019-04-29
Civil3D
2019-04-29
ceisum加载shp格式的城市白模建筑数据
2019-04-29
PuTTY使用方法
2019-04-29
Ubuntu中apache的使用
2019-04-29
WinSCP使用
2019-04-29
MeteoEarth全球天气
2019-04-29
OruxMaps
2019-04-29
mbtiles server 使用错误记录
2019-04-29
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 309264981 位访客
访问时间: 2024-04-30 06:30:16
访问IP: 3.133.149.168
Copyright © 2020 - 2023 blog.css8.cn 京ICP备2021015314号-1
手机版