【Python】正则表达式总结
发布日期:2021-06-28 20:46:59
浏览次数:2
分类:技术文章
本文共 3282 字,大约阅读时间需要 10 分钟。
【Python】正则表达式总结
一,re模块
1,过程
re模块的一般过程如下
expression - > pattern object -> match object -> result 对应的代码如下:import repa = re.compile('some_express')ma = pa.match(str1)ma.group() 2,常用方法
常用方法有:
match() search() findall() sub() split() 前三种方法容易弄混,他们之间存在着差异,import remo_by_match = re.match(r'\d{3}','ab123x12122sa')mo_by_search = re.search(r'\d{3}', 'ab123x12122sa')mo_by_findall = re.findall(r'\d{3}', 'ab123x12122sa')mo_by_findall2 = re.findall(r'(\d{3})(.)', 'ab123x12122sa')print(mo_by_match)print(mo_by_search)print(mo_by_findall)print(mo_by_findall2) 结果:
None #未匹配 <_sre.SRE_Match object; span=(2, 5), match=‘123’> # 返回第一个匹配字符串 [‘123’, ‘121’] #字符串列表 [(‘123’, ‘x’), (‘121’, ‘2’)] #元组列表 (1)match和search都是测试正则表达式与字符串是否匹配,不同的是,match要求字符串的第一个字符就能匹配上正则表达示,也就是说match()只有在0位置匹配成功的话才有返回,如果不是开始位置匹配成功的话,match()就返回none。而search则不同,如果字符串开头不能匹配,即会继续往后匹配,直接匹配成功或者到字符串结束。 (2)search和findall都是扫描整个字符串,search返回一个match对象,包含匹配到的“第一个”字符串,而findall返回一个所有匹配字符串组成的列表,并不是返回match对象。 (3)findall还有另一个特殊用法,如果调用一个有“()”进行分组的正则表达式时,会返回一个元祖列表,每一个元组都是匹配的结果。 (4)sub()传入三个参数pattern, repl, string,pattern为表达式,string为被替换的字符串,repl是用于替换,“repl can be either a string or a callable; If it is a callable, it’s passed the match object and must return a replacement string to be used.” 举个例子str1 = 'I am 23 years old'def add_age(match): age = int(match.group()) age = age + 1 return str(age)new_age = re.sub(r'\d+',add_age,str1)print(new_age)
sub中已经将match对象传入add_age中,match对象是re.match(r’\d+’,str1)的返回,计算出结果返回,再进行替换str1中数字,至于match对象是如何让传递的,我也没弄明白,只能根据代码注释猜测下,
(5)re模块split()是str.split()的升级版, 举个简单粗暴的例子:str2 = 'Split:the source string,by the occurrences#of the pattern' result = re.split(r':| |,|#',str2)print(result)
[‘Split’, ‘the’, ‘source’, ‘string’, ‘by’, ‘the’, ‘occurrences’, ‘of’, ‘the’, ‘pattern’]
如果用str.split()就没法对str2进行切分,但是使用re.split()可以应对,虽然粗暴些。二,正则表达式语法
1,匹配单个字符
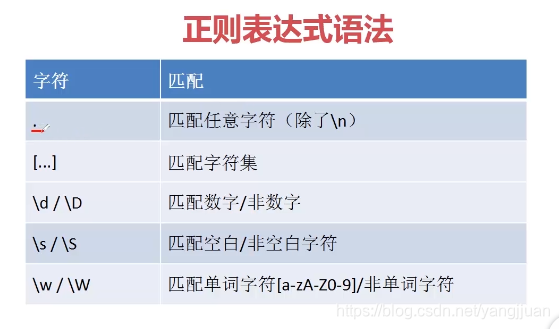
2,匹配多个字符
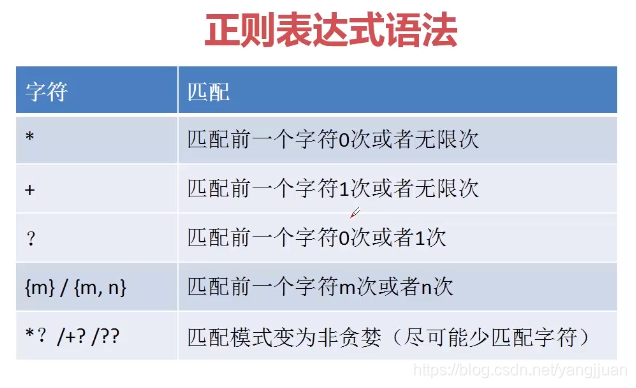
ma = re.match(r'(.)+','Split:the source string,by the occurrences#of the patter')print(ma.group())
结果:Split:the source string,by the occurrences#of the patter
通过在末尾添加“?”,可以采用“非贪心”模式,尽可能匹配最短的字符串,举个例子ma = re.match(r'(.)+?','Split:the source string,by the occurrences#of the patter')print(ma.group())
结果:S
"+"匹配1次或者无限次,这里只匹配一次。3,边界匹配

4,分组匹配
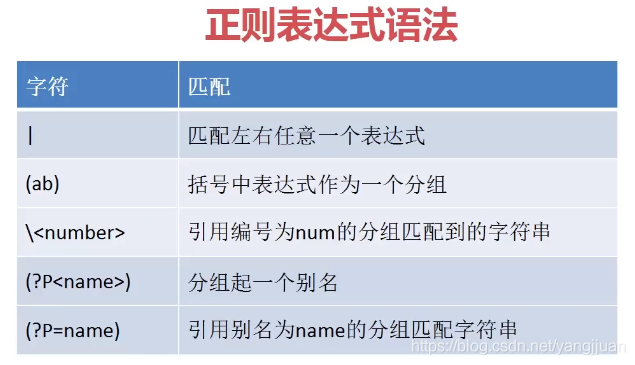
[\w]{6,10}@(163|126|qq).com (2)引用编号的分组,举个例子
ma = re.search(r'<([\w]+>)([\w]+) Python')print(ma.group()) #Python
\1代表第一个分组:[\w]+>,表达式等价于<([\w]+>)([\w]+)</[\w]+>,只是有点冗长。
(3)分组起别名,可以看成是赋值给一个变量,然后就可以使用这个变量,ma = re.search(r'<(?P[\w]+>)([\w]+) Python
')print(ma.group()) #Python
分组:[\w]+>赋给h1,然后在后面使用h1这个变量,?P是大写P,不是小写
5,高阶正则表达式
除了前面的语法,正则还有些高级些的语法,比如(?:…),(?=…),(?<=…),(?!..),(?<!..),个人觉得这些不太好理解,需要实际遇到后,结合实际问题再去理解会好些,把前面的基本语法弄懂,并结合实际问题使用熟练就够了。有几篇详细的博文可以参考
参考:
《Python编程快速上手》转载地址:https://blog.csdn.net/yangjjuan/article/details/88856769 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关注你微信了!
[***.104.42.241]2024年04月21日 23时26分52秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
Android中为什么需要Handler?高级面试题+解析
2019-04-29
Android开发前景怎么样?覆盖所有面试知识点,大厂面经合集
2019-04-29
Android开发岗还不会这些问题,面试建议
2019-04-29
CTFSHOW WEB入门 命令执行做题笔记(持续更新)
2019-04-29
应急响应流程
2019-04-29
Vulhub Flask SSTI漏洞复现
2019-04-29
CTFSHOW 文件包含
2019-04-29
Apache HTTPD 换行解析漏洞
2019-04-29
Vulhub Apache HTTPD 多后缀解析漏洞
2019-04-29
CTFshow 反序列化
2019-04-29
java中调用js函数的方法
2019-04-29
可落地的云游戏解决方案
2019-04-29
Http协议原理分析
2019-04-29
HTTP协议工作原理、工作过程
2019-04-29
抖音视频批量去水印,抖音视频批量解析下载方法 - 2020年6月最新有效
2019-04-29
linux下redis安装遇到的问题及解决办法
2019-04-29
历史数据解决方案
2019-04-29
【基础+实战】JVM原理及优化系列之一:JVM体系结构
2019-04-29
【基础+实战】JVM原理及优化系列之二:JVM内存管理
2019-04-29
【基础+实战】JVM原理及优化系列之三:JVM垃圾收集器
2019-04-29
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 309260595 位访客
访问时间: 2024-04-30 06:10:04
访问IP: 3.15.25.32
Copyright © 2020 - 2023 blog.css8.cn 京ICP备2021015314号-1
手机版