本文共 3206 字,大约阅读时间需要 10 分钟。
Elasticsearch 分词器
Elasticsearch 中内置了很多分词器(analyzers),但是 Elasticsearch 提供的分词器都是英文分词器,对于中文检索来说,不太友好,因此先从一个中文分词器(ik-analyzer )入手,来了解Elasticsearch 分词器的使用。
一、分词器介绍
1.1、内置分词器
| 分词器 | 学习指南 | 作用 |
|---|---|---|
| 标准分词器,适用于英文等。支持为英文单字切分将词汇单元转换成小写形式,并去除停用词和标点符号。 | ||
| 简单分词器,基于非字母字符进行分词,单词会被转为小写字母同时会去掉数字类型的字符 | ||
| 空格分词器,按照空格进行切分,对字符没有lowcase化,不支持中文不对生成的词汇单元进行其他的规范化处理。 | ||
| 类似于简单分词器,但是增加了停用词(如the、a等)功能可以根据自己的需求设置常用词,不支持中文 | ||
| Keyword 分词器 | 关键词分词器,输入文字等于输出文本将整个输入作为一个单独词汇单元,方便特殊类型的文本进行索引和检索。针对邮政编码,地址等文本信息使用关键词分词器进行索引项建立非常方便。 | |
| 可以通过正则表达式将文本分成"terms",支持停用词。 | ||
| 用于解析特殊语言文本的analyzer集合 | ||
| Snowball 分词器 | 由Standard tokenizer和Standard\Lowercase\Stop\Snowball 四个filter构成。在Lucene架构中通常是不推荐使用的。 | |
| 指纹分析仪分析器,通过创建标记进行重复检测 |
1.2、常用分词器
| 分词器 | 作用 |
|---|---|
| Ik-analyzer 分词器是一个开源的、基于Java语言开发的轻量级的中文分词工具包。采用了特有的“正向迭代最细粒度切分算法“,支持细粒度和最大词长两种切分模式;具有83万字/秒(1600KB/S)的高速处理能力。采用了多子处理器分析模式,支持:英文字母、数字、中文词汇等分词处理,兼容韩文、日文字符具有优化的词典存储,更小的内存占用。支持用户词典扩展定义 | |
| 结巴中文分词 | 1、支持三种模式: - 精确模式,试图将句子最精确地切开,适合文本分析; - 全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义; - 搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。同时支持繁体分词和自定义词典 |
| THULAC 分词器 | 规范化分词词典,并去掉一些无用词;重写DAT(双数组Trie树)的构造算法,生成的DAT size减少了8%左右,从而节省了内存优化分词算法,提高了分词速率。 |
| 基于n-Gram+CRF+HMM的中文分词的java实现分词速度达到每秒钟大约200万字左右(mac air下测试),准确率能达到96%以上用户自定义词典,关键字提取,自动摘要,关键字标记等功能 可以应用到自然语言处理等方面,适用于对分词效果要求高的各种项目. | |
| 使用Java开发的一个开源中文分词器,使用流行的mmseg算法实现提供了最高版本的lucene, solr, elasticsearch(New)的分词接口 |
二、中文分词器 ik-analyzer 实战
2.1、安装
2.1.1、下载->安装
安装流程:
-
根据Elasticsearch不同版本,选择下载分词插件
-
到Elasticsearch的plugins 目录创建文件夹 ik
cd es安装目录-root/plugins/&& mkdir ik
-
解压 ik 分词器插件到该ik文件夹中
unzip elasticsearch-analysis-ik-visionNumber.zip如 unzip elasticsearch-analysis-ik-6.4.3.zip
-
启动(./elasticsearch)elasticsearch (如下),可以看到已经加载了 ik 分词器
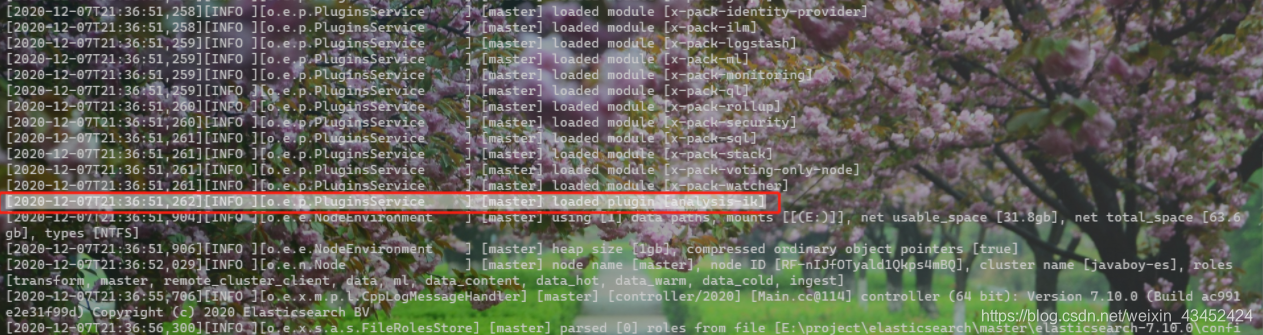
2.1.2、命令行安装(Elasticsearch版本必须大于 5.5.1)
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/vversionNumber/elasticsearch-analysis-ik-versionNumber.zip
例如:
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.3.0/elasticsearch-analysis-ik-6.3.0.zip
重启Elasticsearch 即可
2.2、ik 分词器说明
Ik分词器:
- Ik 有两种分词模式:ik_max_word 和 ik_smart模式
补充说明:
- ik_max_word: 会将文本做最细粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国\中华人民\中华\华人\人民共和国\人民\人\民\共和国\共和\和\国国\国歌”,会穷尽各种可能的组合。如下:


- ik_smart: 会做最粗粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国\国歌”。如下:
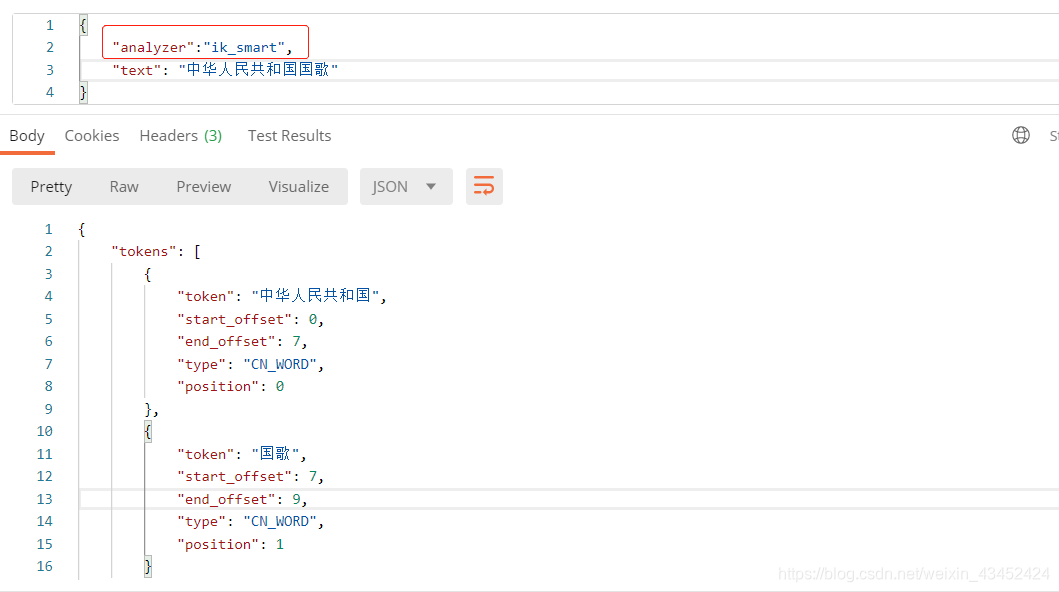
索引时,为了提供索引的覆盖范围,通常会采用ik_max_word分析器,会以最细粒度分词索引,搜索时为了提高搜索准确度,会采用ik_smart分析器,会以粗粒度分词。
2.3、实测
导入ik 分词器 后,重启Elasticsearch,创建索引 index。
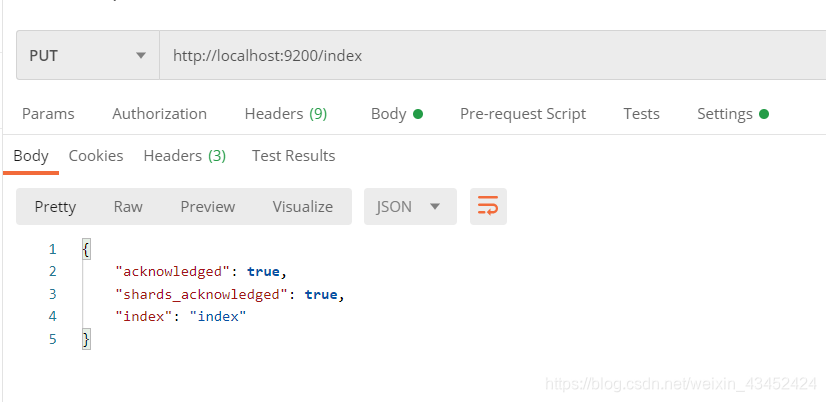
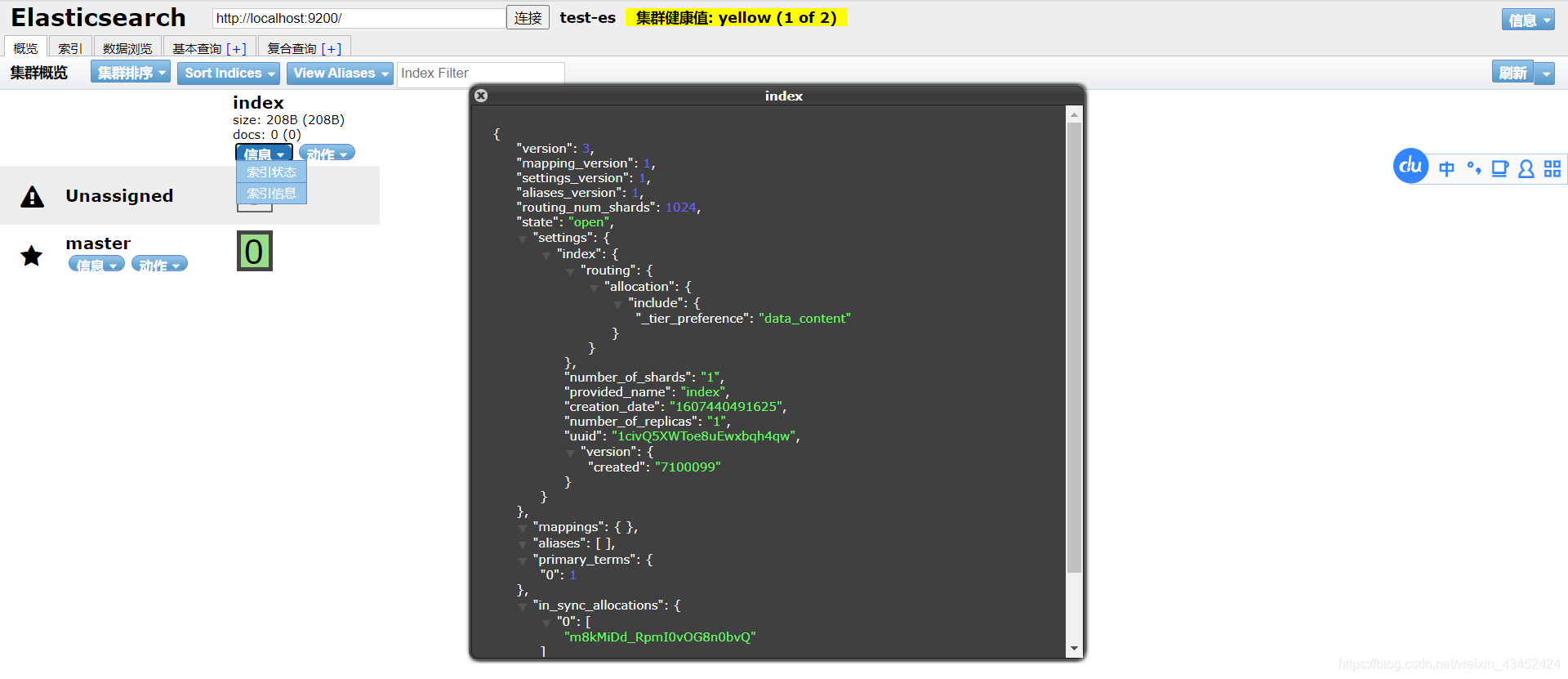
创建索引成功,可在ElasticSearch Head 插件中查看到如下信息索引:
测试 ik 中文分词器:
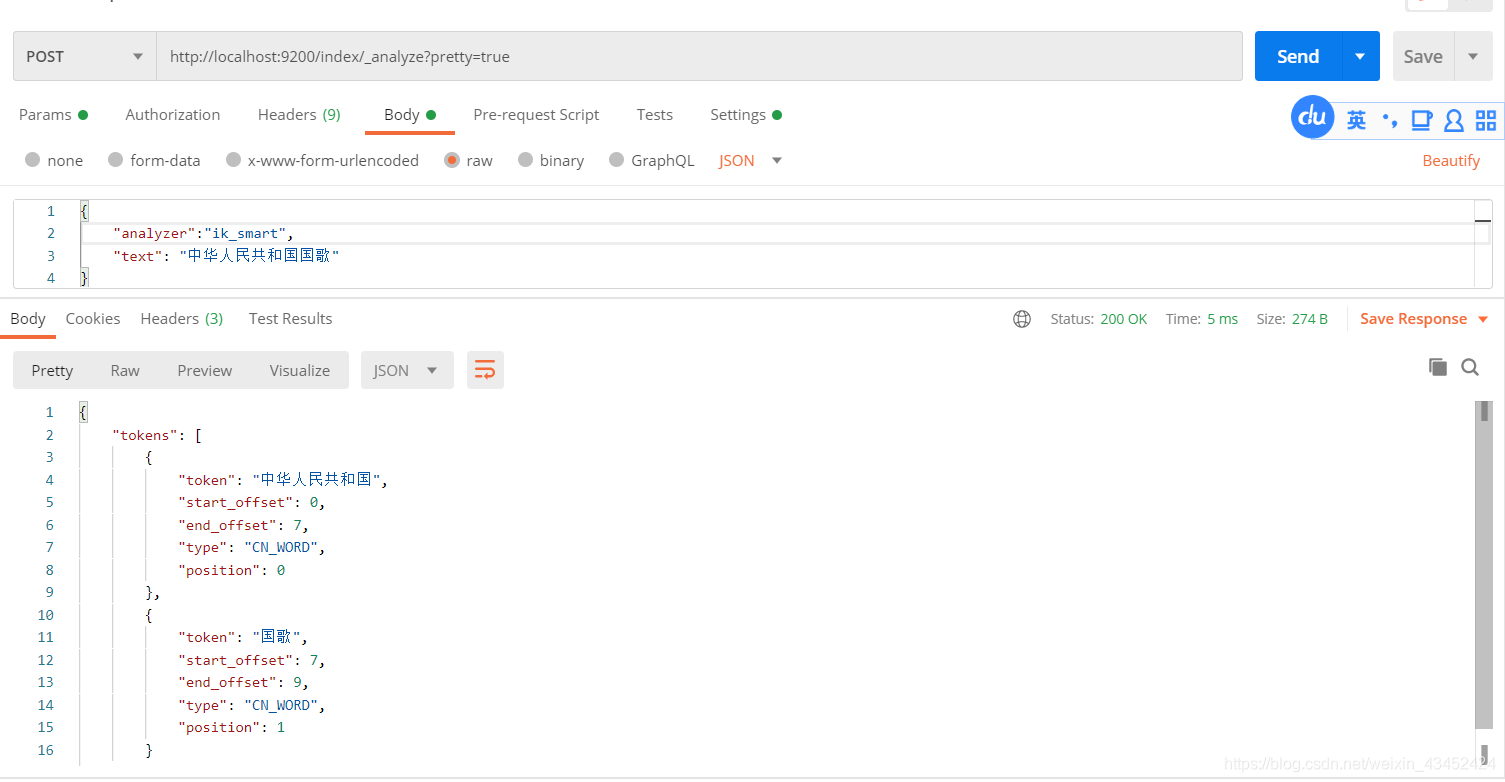
使用Postman 发送POST请求 http://localhost:9200/index/_analyze?pretty=true,同时设置body为:
{ "analyzer":"ik_max_word", "text": "中华人民共和国国歌"}//可通过修改"analyzer",来指定ik 中文分词器的两种分词模式 测试结果如下:
补充:
- 使用 Postman 创建 Elasticsearch 索引时,如果出现如下问题:
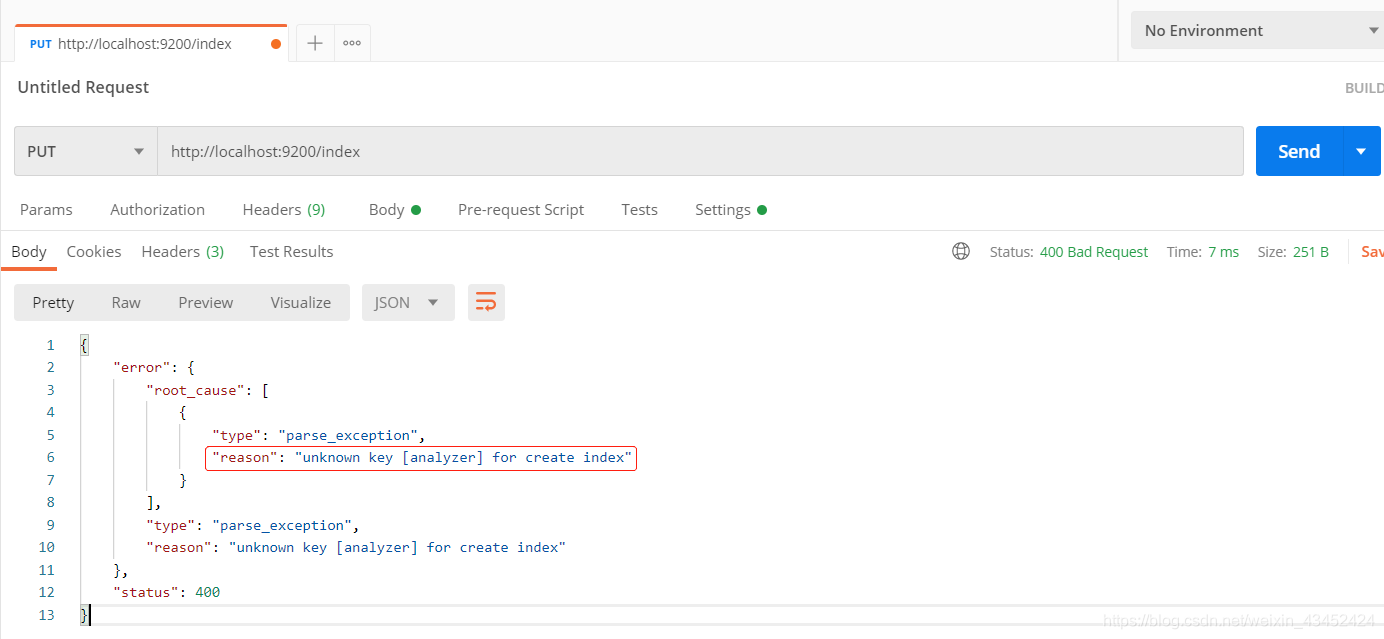 可更改Postman 的 header如下,即可解决:
可更改Postman 的 header如下,即可解决: 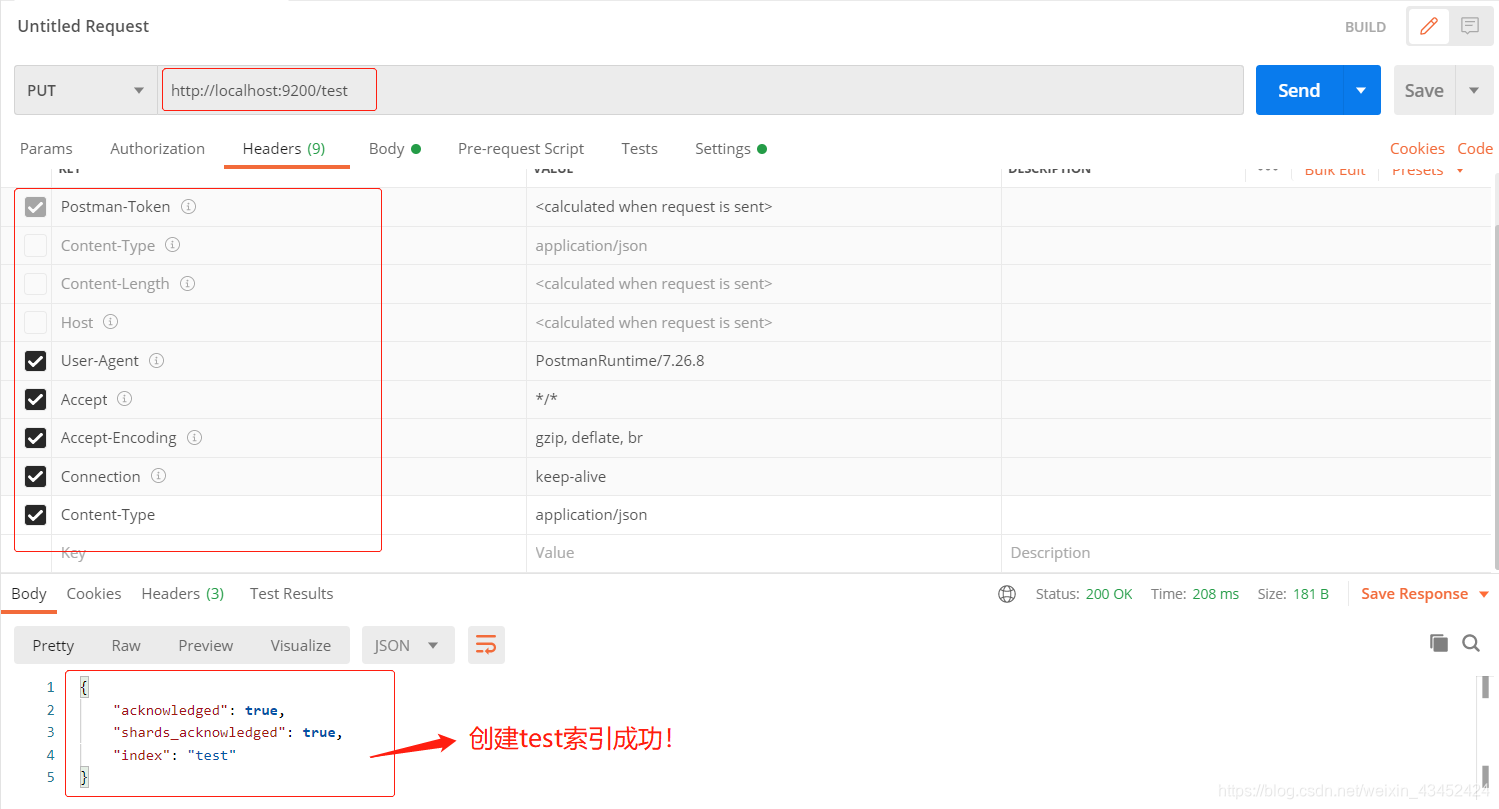 创建索引成功!
创建索引成功! 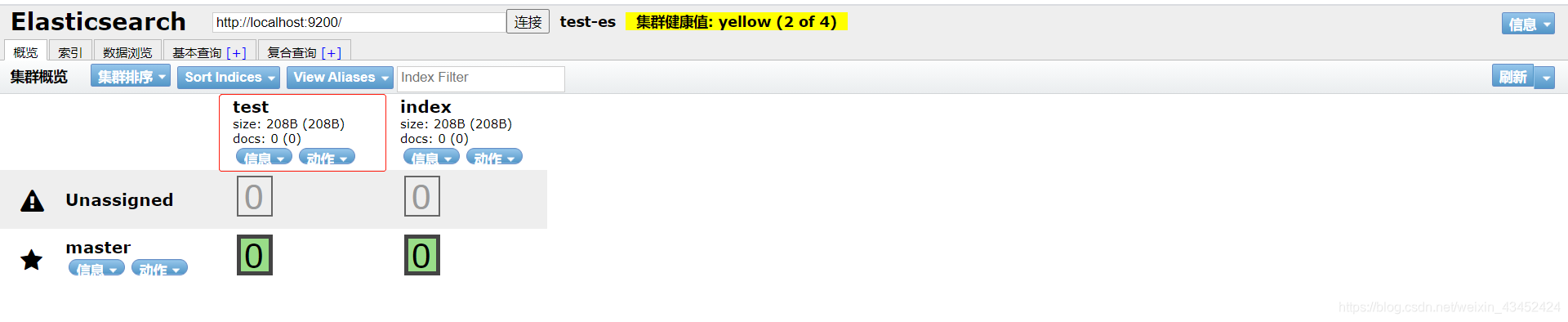
- 当使用Postman 测试 Elasticsearch 分词器时,出现如下问题:
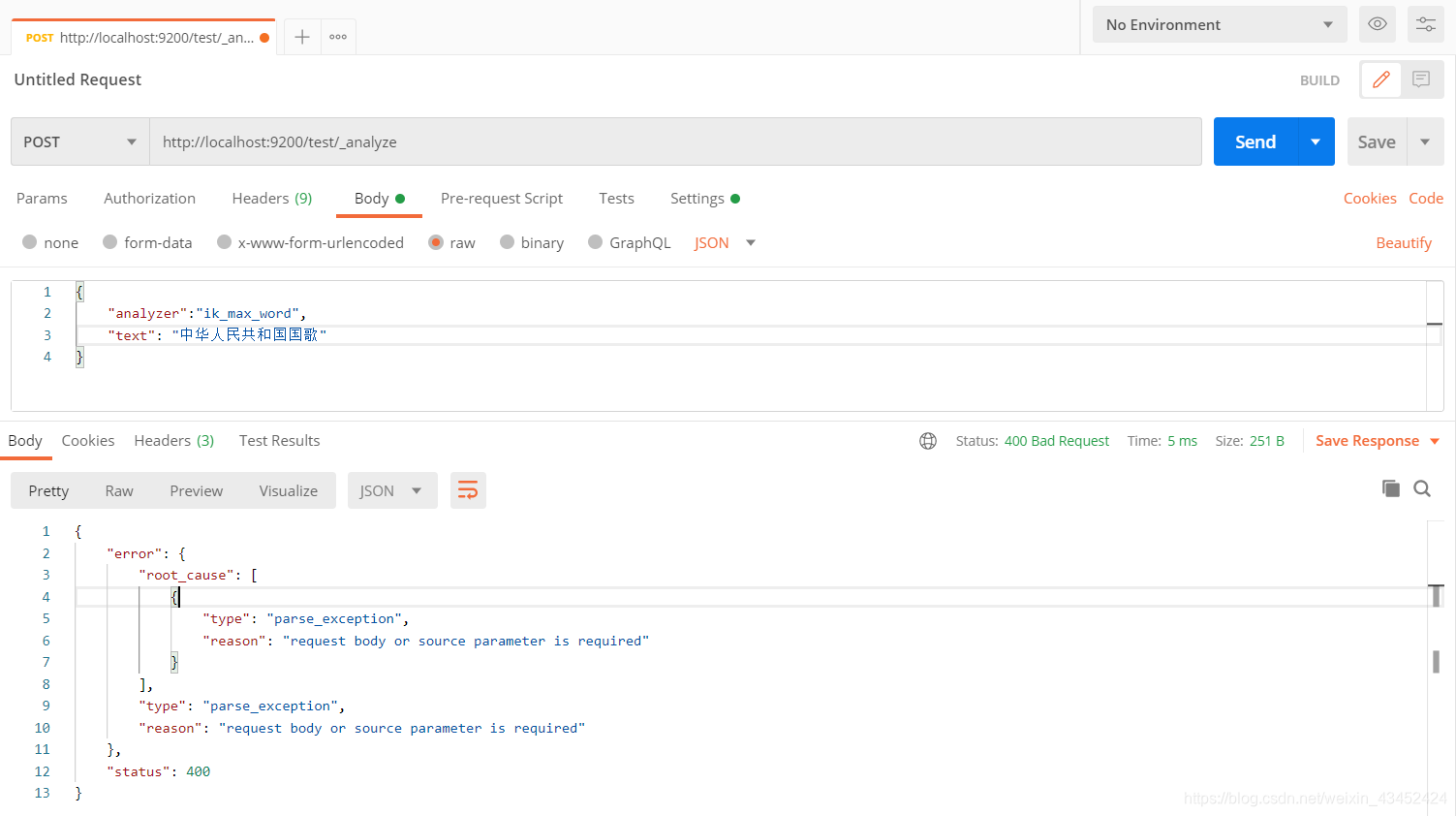 修改Postman 的header为如下,即可解决
修改Postman 的header为如下,即可解决 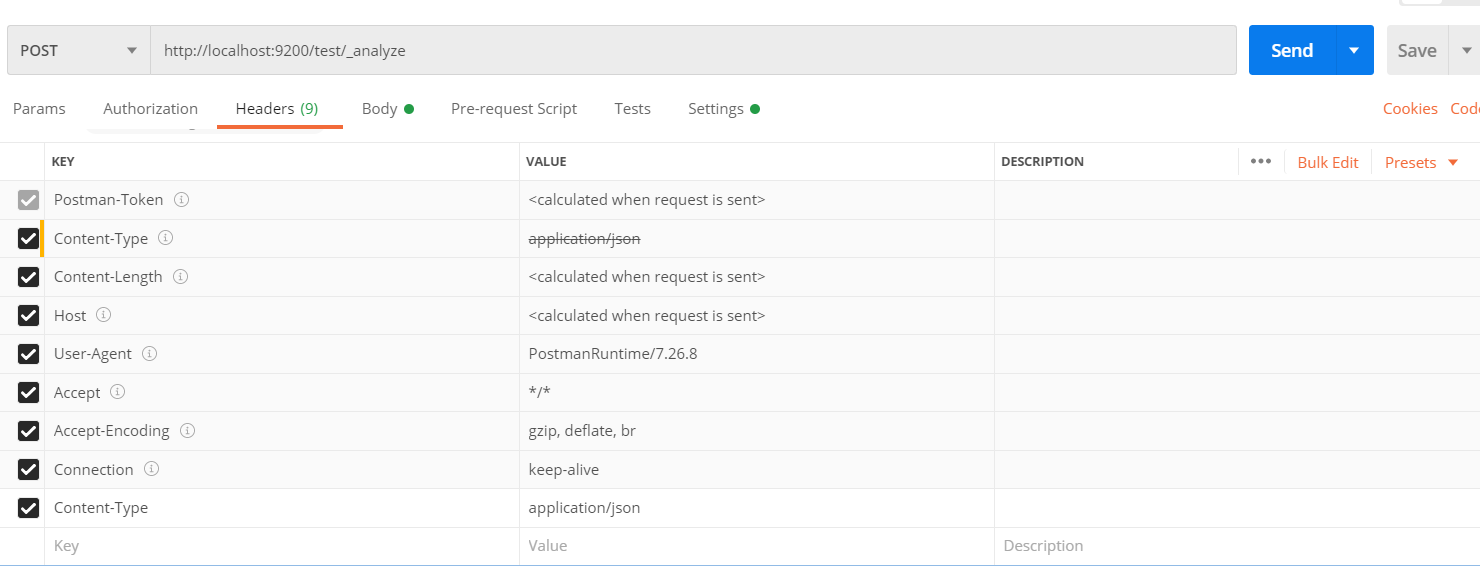
2.4、自定义扩展词库
2.4.1、本地自定义
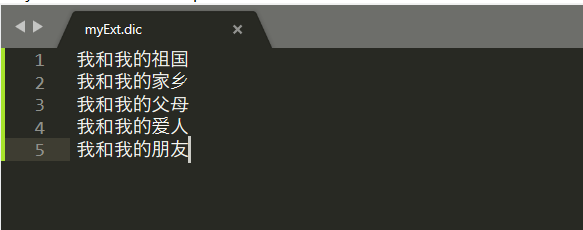
- 进入文件目录 【elasticsearch安装目录/plugins/ik/config】,建立文件 【文件名.dic】 ,自定义本地扩展词库,多个词的话,换行即可。如下:
-
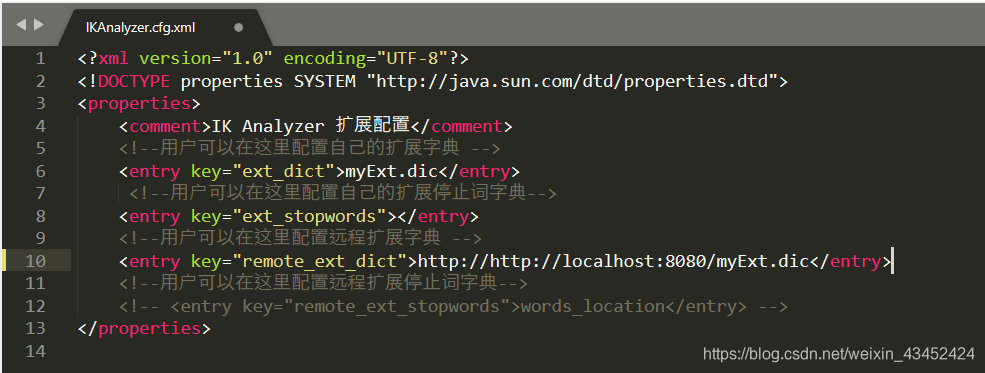
在【elasticsearch安装目录/plugins/ik/config/IKAnalyzer.cfg.xml】 中配置扩展词典的位置
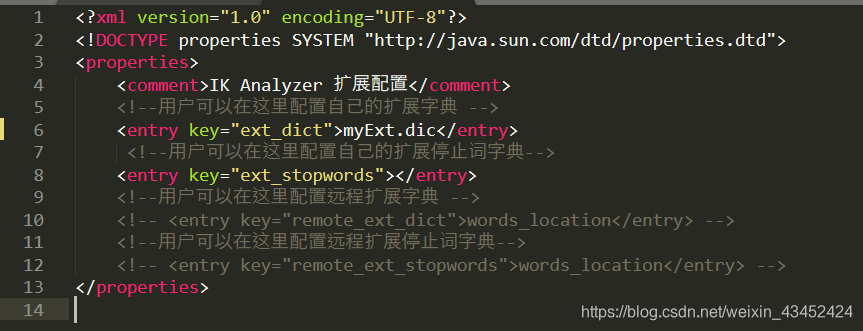 重启Elasticsearch ,测试结果如下:
重启Elasticsearch ,测试结果如下: { "analyzer":"ik_smart", "text": "我和我的祖国我和我的家乡我和我的爱人我和我的父母"}

{ "analyzer":"ik_max_word", "text": "我和我的祖国"} 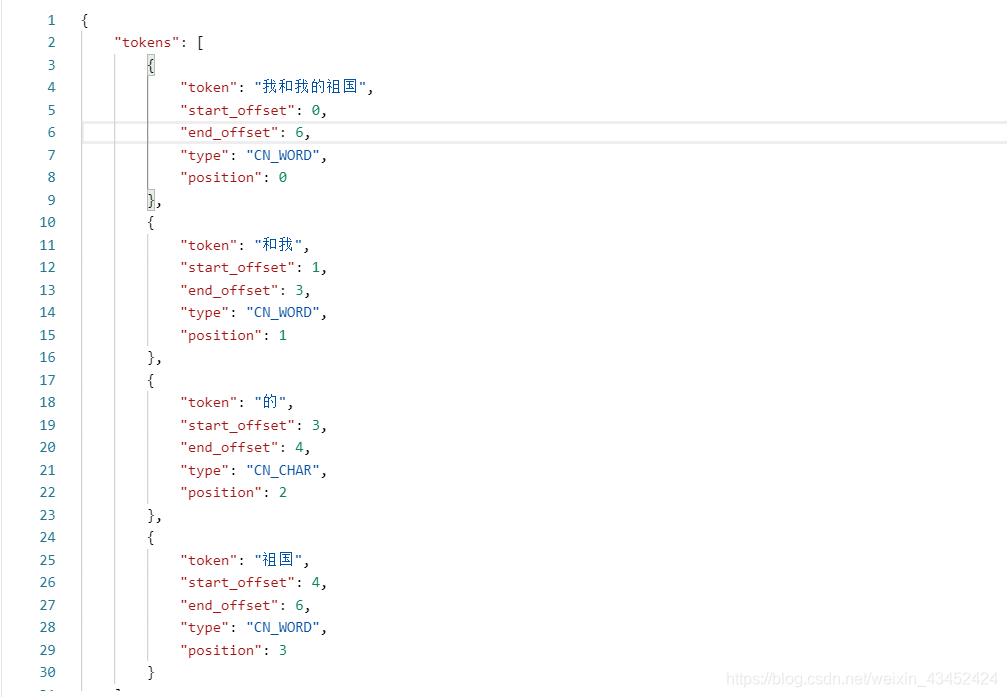
2.4.2、远程词库
- 搭建Springboot 项目
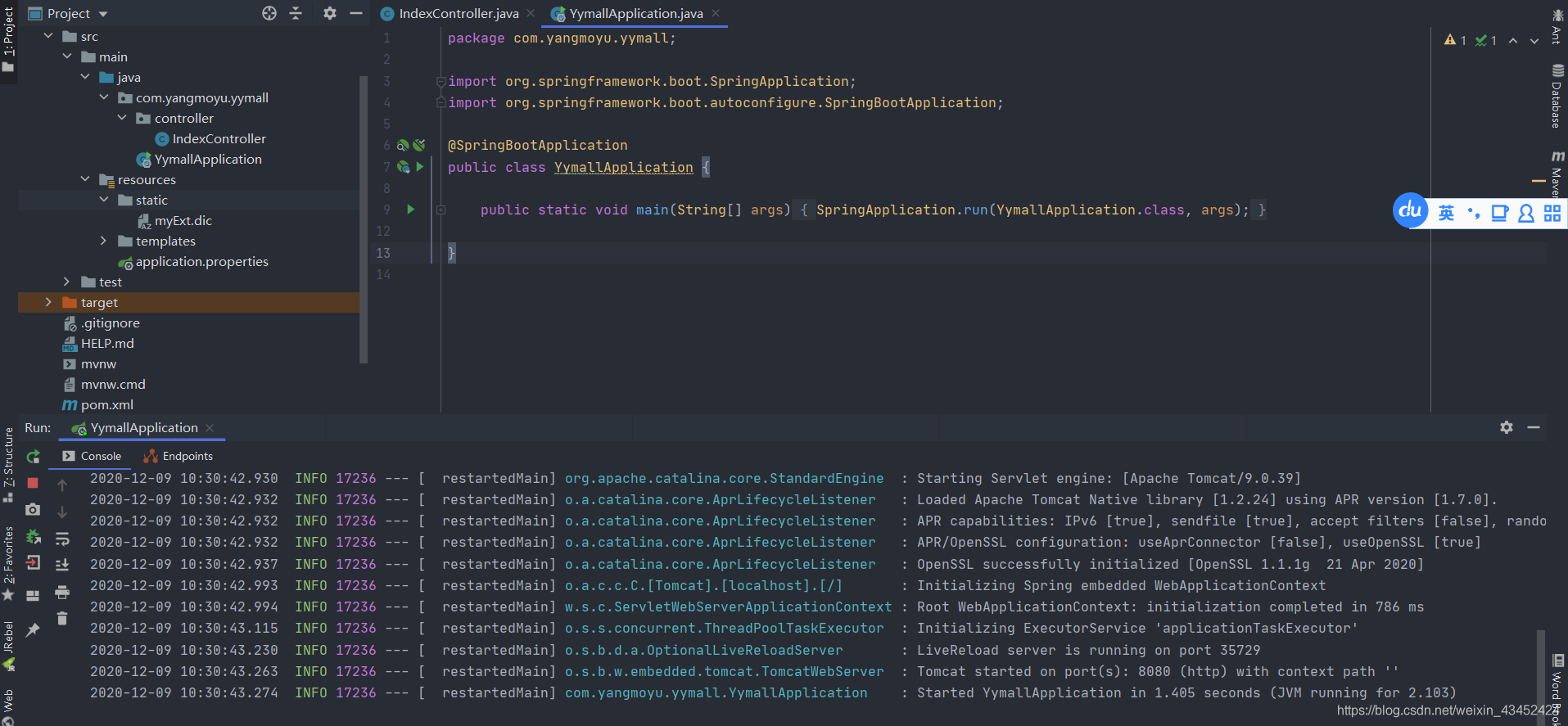
- 测试结果如下:(远程词库支持热部署,等待时间有点长),重启 Elasticsearch 如下

{ "analyzer":"ik_max_word", "text": "我在北京等你"} 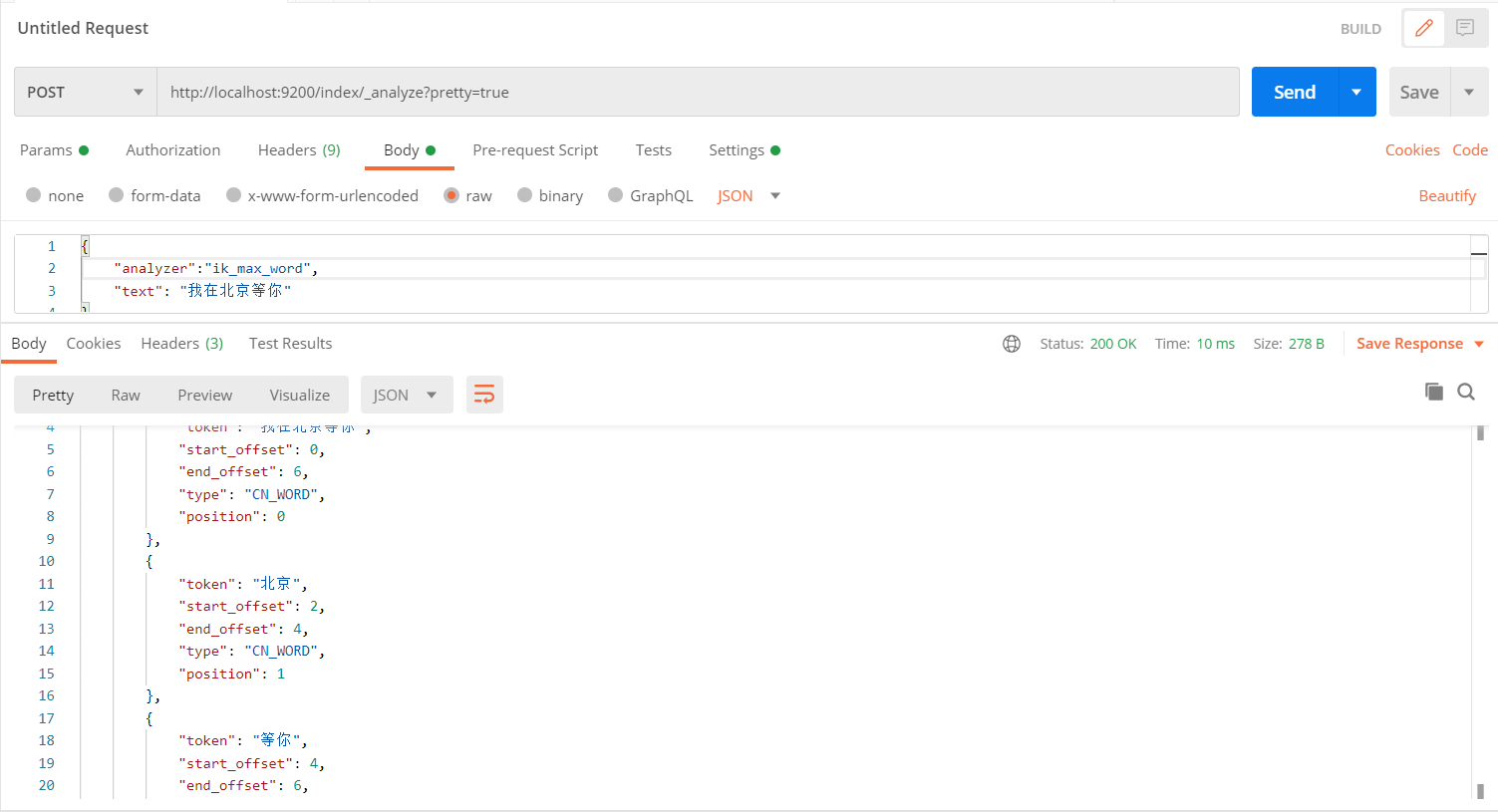
{ "analyzer":"ik_smart", "text": "我在北京等你"} 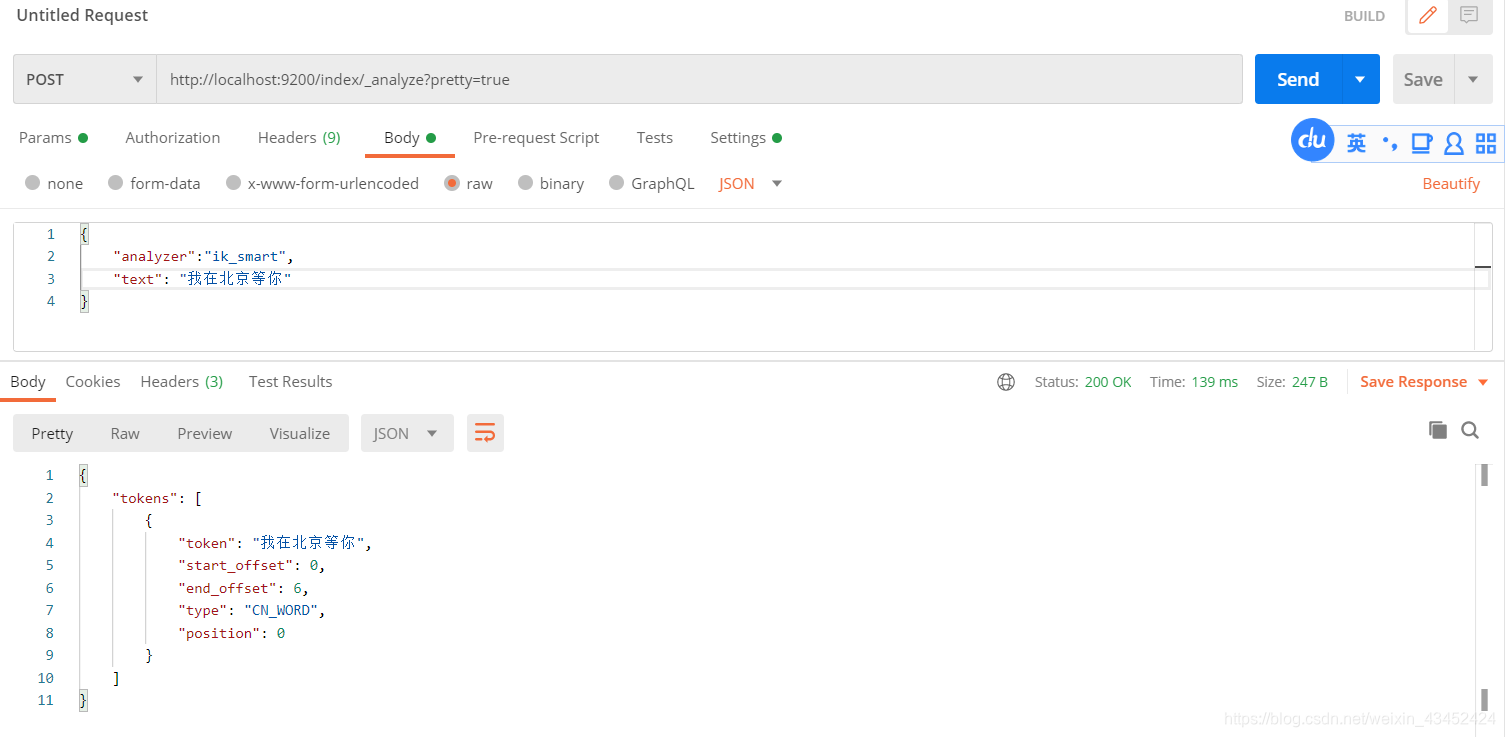
转载地址:https://blog.csdn.net/weixin_43452424/article/details/110939869 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
