本文共 5614 字,大约阅读时间需要 18 分钟。
它可能会要求太多的MySQL期望它直接从查询生成格式正确的json。 相反,可以考虑使用CSV(使用INTO OUTFILE '/path/to/output.csv' FIELDS TERMINATED BY ','你已经知道INTO OUTFILE '/path/to/output.csv' FIELDS TERMINATED BY ','片段INTO OUTFILE '/path/to/output.csv' FIELDS TERMINATED BY ','来生成更方便的东西,然后将结果转换成带有内置支持的语言为它,像Python或PHP。
编辑 Python的例子,使用罚款SQLAlchemy:
class Student(object): '''The model, a plain, ol python class''' def __init__(self, name, email, enrolled): self.name = name self.email = email self.enrolled = enrolled def __repr__(self): return "" % (self.name, self.email) def make_dict(self): return {'name': self.name, 'email': self.email} import sqlalchemy metadata = sqlalchemy.MetaData() students_table = sqlalchemy.Table('students', metadata, sqlalchemy.Column('id', sqlalchemy.Integer, primary_key=True), sqlalchemy.Column('name', sqlalchemy.String(100)), sqlalchemy.Column('email', sqlalchemy.String(100)), sqlalchemy.Column('enrolled', sqlalchemy.Date) ) # connect the database. substitute the needed values. engine = sqlalchemy.create_engine('mysql://user:pass@host/database') # if needed, create the table: metadata.create_all(engine) # map the model to the table import sqlalchemy.orm sqlalchemy.orm.mapper(Student, students_table) # now you can issue queries against the database using the mapping: non_students = engine.query(Student).filter_by(enrolled=None) # and lets make some json out of it: import json non_students_dicts = ( student.make_dict() for student in non_students) students_json = json.dumps(non_students_dicts)
如果你有Ruby,你可以安装mysql2xxxx gem(而不是mysql2json gem,这是一个不同的gem):
$ gem install mysql2xxxx
然后运行该命令
$ mysql2json --user=root --password=password --database=database_name --execute "select * from mytable" >mytable.json
该gem还提供了mysql2csv和mysql2xml 。 它不像mysqldump那么快,但也不会受到一些mysqldump怪异的影响(比如只能从与MySQL服务器本身相同的计算机上转储CSV)
另一种可能是使用MySQL Workbench。
在对象浏览器上下文菜单和结果网格菜单上有一个JSON导出选项。
有关MySQL文档的更多信息:数据导出和导入 。
这是应该在应用程序层完成的事情。
例如,在PHP中,它是如此简单
编辑添加了数据库连接的东西。 没有外在的东西需要。
$sql = "select ..."; $db = new PDO ( "mysql:$dbname", $user, $password) ; $stmt = $db->prepare($sql); $stmt->execute(); $result = $stmt->fetchAll(); file_put_contents("output.txt", json_encode($result));
如果您使用的是Ruby,另一个解决scheme是使用ActiveRecord将连接脚本写入数据库。 您将需要先安装它
gem安装activerecord
# ruby ./export-mysql.rb require 'rubygems' require 'active_record' ActiveRecord::Base.establish_connection( :adapter => "mysql", :database => "database_name", :username => "root", :password => "", :host => "localhost" ) class Event < ActiveRecord::Base; end class Person < ActiveRecord::Base; end File.open("events.json", "w") { |f| f.write Event.all.to_json } File.open("people.json", "w") { |f| f.write Person.all.to_json }
如果您想先操作数据或包含或排除某些列,您也可以将方法添加到ActiveRecord类。
Person.all.to_json(:only => [ :id, :name ])
使用ActiveRecord,您不仅限于JSON。 您可以像XML或YAML一样轻松导出
Person.all.to_xml Person.all.to_yaml
你不限于MySQL。 任何由ActiveRecord(Postgres,SQLite3,Oracle …等)支持的数据库。
值得一提的是你可以打开另一个数据库句柄
require 'active_record' ActiveRecord::Base.configurations["mysql"] = { :adapter => 'mysql', :database => 'database_name', :username => 'root', :password => '', :host => 'localhost' } ActiveRecord::Base.configurations["sqlite3"] = { :adapter => 'sqlite3', :database => 'db/development.sqlite3' } class PersonMySQL < ActiveRecord::Base establish_connection "mysql" end class PersonSQLite < ActiveRecord::Base establish_connection "sqlite3" end PersonMySQL.all.each do |person| PersonSQLite.create(person.attributes.except("id")) end
HeidiSQL也允许你这样做。
在“数据”选项卡或查询结果集中突出显示任何数据…然后右键单击并select“导出网格行”选项。 这个选项可以让你将任何数据导出为JSON,直接导入到剪贴板或者直接导入到文件中:
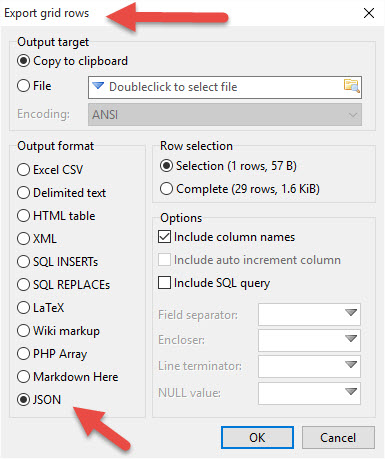
我知道这是旧的,但为了有人寻找答案…
有一个MYSQL的JSON库可以在这里find你需要有根访问你的服务器,并舒适地安装插件(这很简单)。
1)将lib_mysqludf_json.so上传到您的mysql安装的plugins目录中
2)运行lib_mysqludf_json.sql文件(它几乎为你做了所有的工作,如果遇到麻烦,只要删除任何以“DROP FUNCTION …”开头的文件)
3)编码你的查询在这样的东西:
SELECT json_array( group_concat(json_object( name, email)) FROM .... WHERE ...
它会返回类似的东西
[ { "name": "something", "email": "someone@somewhere.net" }, { "name": "someone", "email": "something@someplace.com" } ]
如链接所述,它只返回(如我所述)的15个结果。 (fww,我查了4000个结果,我应该得到的,这15个和4000头的15个一样)
这是因为mysql一旦达到它截断的数量就将group concat返回的数据长度限制在@@ group_concat_max_len中设置的值,并返回到目前为止所得到的值。
您可以用几种不同的方式设置@@ group_concat_max_len。 参考mysql文档…
另外,如果您在应用程序层导出,请不要忘记限制结果。 例如,如果你有10M行,你应该逐个获得结果。
您可以直接从PHPMyAdmin将任何SQL查询导出为JSON
使用下面的ruby代码
require 'mysql2' client = Mysql2::Client.new( :host => 'your_host', `enter code here` :database => 'your_database', :username => 'your_username', :password => 'your_password') table_sql = "show tables" tables = client.query(table_sql, :as => :array) open('_output.json', 'a') { |f| tables.each do |table| sql = "select * from `#{table.first}`" res = client.query(sql, :as => :json) f.puts res.to_a.join(",") + "\n" end }
对于任何想用Python做这个的人来说,并且能够导出所有的表格,而不用预先定义字段名等,我前些天写了一个简短的脚本,希望有人认为它有用:
from contextlib import closing from datetime import datetime import json import MySQLdb DB_NAME = 'x' DB_USER = 'y' DB_PASS = 'z' def get_tables(cursor): cursor.execute('SHOW tables') return [r[0] for r in cursor.fetchall()] def get_rows_as_dicts(cursor, table): cursor.execute('select * from {}'.format(table)) columns = [d[0] for d in cursor.description] return [dict(zip(columns, row)) for row in cursor.fetchall()] def dump_date(thing): if isinstance(thing, datetime): return thing.isoformat() return str(thing) with closing(MySQLdb.connect(user=DB_USER, passwd=DB_PASS, db=DB_NAME)) as conn, closing(conn.cursor()) as cursor: dump = {} for table in get_tables(cursor): dump[table] = get_rows_as_dicts(cursor, table) print(json.dumps(dump, default=dump_date, indent=2))
这可能是一个更利基的答案,但如果你在Windows和MYSQL工作台,你可以select你想要的表,然后在结果网格中单击导出/导入。 这会给你多种格式选项,包括.json
转载地址:https://blog.csdn.net/weixin_34207880/article/details/114796199 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
