使用sklearn预测走势_使用python+sklearn实现高斯过程分类(GPC)的概率预测
 ☆☆☆为方便大家查阅,小编已将scikit-learn学习路线专栏文章统一整理到公众号底部菜单栏,同步更新中,关注公众号,点击左下方“系列文章”,如图
☆☆☆为方便大家查阅,小编已将scikit-learn学习路线专栏文章统一整理到公众号底部菜单栏,同步更新中,关注公众号,点击左下方“系列文章”,如图  欢迎大家和我一起沿着scikit-learn文档这条路线,一起巩固机器学习算法基础。(添加微信:mthler,备注:sklearn学习,一起进【sklearn机器学习进步群】开启打怪升级的学习之旅。)
欢迎大家和我一起沿着scikit-learn文档这条路线,一起巩固机器学习算法基础。(添加微信:mthler,备注:sklearn学习,一起进【sklearn机器学习进步群】开启打怪升级的学习之旅。) 
发布日期:2021-06-24 17:30:08
浏览次数:2
分类:技术文章
本文共 3415 字,大约阅读时间需要 11 分钟。
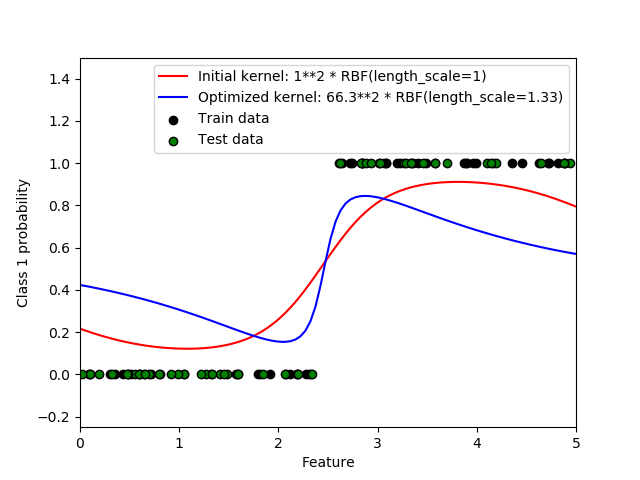
本示例描述了不同超参数下RBF核函数的GPC预测概率。第一个图显示了任意选择超参数和最大log-marginal-likelihood(LML)超参数的GPC预测概率。
通过优化LML选择的超参数具有较大的LML,但从试验数据的对数损失来看,其性能稍差。图中显示,这是因为它们在类边界处显示类概率的急剧变化(这是好的),但预测的概率远离类边界的概率接近0.5(这是坏的),这一不良影响是由GPC内部使用的拉普拉斯近似引起的。
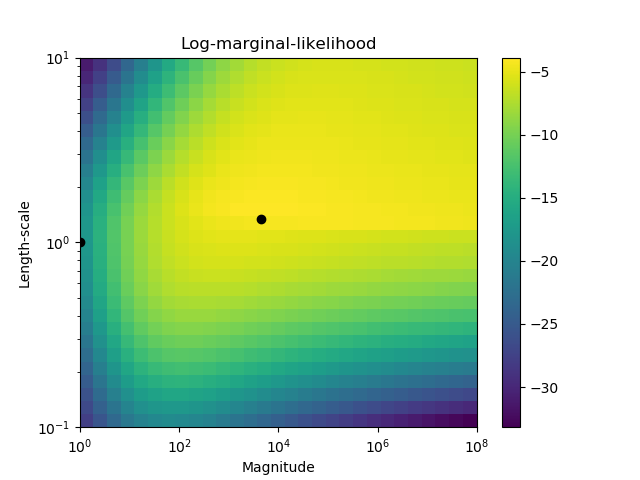
第二个图显示了不同内核超参数选择下的log-marginal-likelihood,并用黑点突出显示了第一个图中使用的两个超参数的选择。
输出:
Log Marginal Likelihood (initial): -17.598 Log Marginal Likelihood (optimized): -3.875 Accuracy: 1.000 (initial) 1.000 (optimized) Log-loss: 0.214 (initial) 0.319 (optimized)
print(__doc__) # 作者: Jan Hendrik Metzen # # 许可证: BSD 3 clause import numpy as np from matplotlib import pyplot as plt from sklearn.metrics import accuracy_score, log_loss from sklearn.gaussian_process import GaussianProcessClassifier from sklearn.gaussian_process.kernels import RBF # 生成数据 train_size = 50 rng = np.random.RandomState(0) X = rng.uniform(0, 5, 100)[:, np.newaxis] y = np.array(X[:, 0] > 2.5, dtype=int) # 用拟合和优化的超参数指定高斯过程 gp_fix = GaussianProcessClassifier(kernel=1.0 * RBF(length_scale=1.0), optimizer=None) gp_fix.fit(X[:train_size], y[:train_size]) gp_opt = GaussianProcessClassifier(kernel=1.0 * RBF(length_scale=1.0)) gp_opt.fit(X[:train_size], y[:train_size]) print("Log Marginal Likelihood (initial): %.3f" % gp_fix.log_marginal_likelihood(gp_fix.kernel_.theta)) print("Log Marginal Likelihood (optimized): %.3f" % gp_opt.log_marginal_likelihood(gp_opt.kernel_.theta)) print("Accuracy: %.3f (initial) %.3f (optimized)" % (accuracy_score(y[:train_size], gp_fix.predict(X[:train_size])), accuracy_score(y[:train_size], gp_opt.predict(X[:train_size])))) print("Log-loss: %.3f (initial) %.3f (optimized)" % (log_loss(y[:train_size], gp_fix.predict_proba(X[:train_size])[:, 1]), log_loss(y[:train_size], gp_opt.predict_proba(X[:train_size])[:, 1]))) # 绘制后验图 plt.figure() plt.scatter(X[:train_size, 0], y[:train_size], c='k', label="Train data", edgecolors=(0, 0, 0)) plt.scatter(X[train_size:, 0], y[train_size:], c='g', label="Test data", edgecolors=(0, 0, 0)) X_ = np.linspace(0, 5, 100) plt.plot(X_, gp_fix.predict_proba(X_[:, np.newaxis])[:, 1], 'r', label="Initial kernel: %s" % gp_fix.kernel_) plt.plot(X_, gp_opt.predict_proba(X_[:, np.newaxis])[:, 1], 'b', label="Optimized kernel: %s" % gp_opt.kernel_) plt.xlabel("Feature") plt.ylabel("Class 1 probability") plt.xlim(0, 5) plt.ylim(-0.25, 1.5) plt.legend(loc="best") # 绘制 LML 图示 plt.figure() theta0 = np.logspace(0, 8, 30) theta1 = np.logspace(-1, 1, 29) Theta0, Theta1 = np.meshgrid(theta0, theta1) LML = [[gp_opt.log_marginal_likelihood(np.log([Theta0[i, j], Theta1[i, j]])) for i in range(Theta0.shape[0])] for j in range(Theta0.shape[1])] LML = np.array(LML).T plt.plot(np.exp(gp_fix.kernel_.theta)[0], np.exp(gp_fix.kernel_.theta)[1], 'ko', zorder=10) plt.plot(np.exp(gp_opt.kernel_.theta)[0], np.exp(gp_opt.kernel_.theta)[1], 'ko', zorder=10) plt.pcolor(Theta0, Theta1, LML) plt.xscale("log") plt.yscale("log") plt.colorbar() plt.xlabel("Magnitude") plt.ylabel("Length-scale") plt.title("Log-marginal-likelihood") plt.show() 脚本的总运行时间: ( 0 分 2.692 秒)
估计的内存使用量: 8 MB
下载python源代码: plot_gpc.py 下载Jupyter notebook源代码: plot_gpc.ipynb 由Sphinx-Gallery生成的画廊 ☆☆☆为方便大家查阅,小编已将scikit-learn学习路线专栏文章统一整理到公众号底部菜单栏,同步更新中,关注公众号,点击左下方“系列文章”,如图 欢迎大家和我一起沿着scikit-learn文档这条路线,一起巩固机器学习算法基础。(添加微信:mthler,备注:sklearn学习,一起进【sklearn机器学习进步群】开启打怪升级的学习之旅。)
转载地址:https://blog.csdn.net/weixin_34164146/article/details/112784774 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
很好
[***.229.124.182]2024年04月14日 14时27分08秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
Ubertooth one“蓝牙扫描嗅探”使用教程
2019-04-28
Nmap绕过防火墙扫描
2019-04-28
Nmap端口扫描+Nmap脚本扫描漏洞(学习笔记)
2019-04-28
9.4. 社会工程学
2019-04-28
9.7. 近源渗透
2019-04-28
9.8. Web持久化
2019-04-28
“不一样的视角“剖析linux反弹shell
2019-04-28
9.11. 防御
2019-04-28
9.12. 运维
2019-04-28
9.13. 其他
2019-04-28
10. 手册速查
2019-04-28
10.1. 爆破工具
2019-04-28
10.4. 嗅探工具
2019-04-28
10.5. SQLMap使用
2019-04-28
11. 其他(目录)
2019-04-28
11.1. 代码审计
2019-04-28
11.4. 拒绝服务攻击
2019-04-28
11.6. APT
2019-04-28
11.7. 近源渗透
2019-04-28
python做词云图
2019-04-28
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 308876310 位访客
访问时间: 2024-04-29 07:15:08
访问IP: 13.59.195.118
Copyright © 2020 - 2023 blog.css8.cn 京ICP备2021015314号-1
手机版