本文共 5006 字,大约阅读时间需要 16 分钟。
这两年学会了跑sql,当时有很多同学帮助我精进了这个技能,现在也写成一个小教程,反馈给大家。
适用对象:工作中能接触到sql查询平台的业务同学(例如有数据查询权限的产品与运营同学)
适用场景:查询hive&mysql上的数据
文档优势:比起各类从零起步的教程教材,理解门槛低,有效信息密度大,可以覆盖高频业务场景。
文末有一些常见的小技巧,希望帮助同学们提升工作效率。
SQL的基础结构:
做一个类比,我们用的“表”,就像是一个账本,每天就是一个“分区”,“字段”就是日记上记的不同的事情,例如支出、收入、物品和价格等;
一般来讲sql有如下结构,意思是从表α.table里面,获取某一天的abc三个字段,后面的讲解都是在这个基础上展开的:
select a,b,c //select后面输入需要查询的字段fromα.table //from后面输入需要查询的表名wheredate='yymmdd' //where后面输入需要卡的条件,例如只看哪天的数据
多个条件同时生效-and和or
and的用法//表示多条件同时生效
select a,b,c //select后面输入需要查询的字段fromα.table //from后面输入需要查询的表名where date='yymmdd' //where后面输入需要卡的条件,例如只看哪天的数据and //表示要看date='yymmdd' 且id='XXX'id=XXX
or的用法//表示有一个条件生效即可
select a,b,c //select后面输入需要查询的字段fromα.table //from后面输入需要查询的表名where date='yymmdd' //where后面输入需要卡的条件,例如只看哪天的数据and (id=XXXor d_id=XXX) //表示要看date='yymmdd' ,且id是xxx或d_id是xxx的数据。如果没有这个括号,表示的是要看date是yymmdd且id是xxx,或者不分日期,d_id是xxx的数据
对指标进行加和//sum
学习到本节时,我们需要明白维度和指标的区别,维度是表示属性的,指标是表示量级的,例如全中国有56个民族,全中国就是一个维度,民族数量就是一个指标
select //select后面输入需要查询的字段a,b,sum(c) //需要加和的c字段(指标)括起来加sum即可,有点像excel那种fromα.table //from后面输入需要查询的表名where date='yymmdd' //where后面输入需要卡的条件,例如只看哪天的数据and (id=XXXor sp_id=XXX) //表示要看date='yymmdd' ,且id是xxx或sp_id是xxx的数据。如果没有这个括号,表示的是要看date是yymmdd且id是xxx,或者不分日期,sp_id是xxx的数据group by a,b //没有被处理的字段(维度),需要在尾部group by 一下
为字段重新命名//as
select //select后面输入需要查询的字段a,b as b1,sum(c) as c1 //需要加和的c字段括起来加sum即可,有点像excel那种;这里用as把b重新命名成了b1,把c重新命名成了c1fromα.table //from后面输入需要查询的表名where date='yymmdd' //where后面输入需要卡的条件,例如只看哪天的数据and (id=XXXor sp_id=XXX) //表示要看date='yymmdd' ,且id是xxx或sp_id是xxx的数据。如果没有这个括号,表示的是要看date是yymmdd且id是xxx,或者不分日期,sp_id是xxx的数据group by a,b //没有被处理的字段,需要在尾部group by 一下;被重新命名的维度字段,group by时仍用as前面的内容
查数据条数,或查询维度的数量//count和distinct
select //select后面输入需要查询的字段a,b,sum(c), //需要加和的c字段括起来加sum即可,有点像excel那种count(distinct d)//去重查询在a,b枚举下,d有几个,例如查ka,la(a)的客户id(b)下,总共有几个广告主(d);不加distinct查询的是所有的广告主(d)总共出现了几次fromα.table //from后面输入需要查询的表名where date='yymmdd' //where后面输入需要卡的条件,例如只看哪天的数据and (id=XXXor sp_id=XXX) //表示要看date='yymmdd' ,且id是xxx或sp_id是xxx的数据。如果没有这个括号,表示的是要看date是yymmdd且id是xxx,或者不分日期,sp_id是xxx的数据group by a,b //没有被处理的字段,需要在尾部group by 一下
对一份数据做多次处理//嵌套结构
如下sql查询了每个人在当天的页面访问频次。3到7行先查询出每个用户id的页面访问频次,然后使用3到7行的结果,查询每个访问频次下,有几个id:SELECT cnt,count(id)FROM(select id,count(*) as cnt //-'*'可以用来查询行数from α.tablewhere date ='20190928' and label='show'group by id) a //-这里写一个'a',用来给3到7行的结果命名,这样外层的sql才能识别括号里面的内容group by cnt
对多份数据做关联处理//join
最常用的场景:假设表A上有门店id是a,收入是b,表B上有门店id是a,门店名称c,如果需要获取门店id,收入,门店名称的关系,可以这么写:
SELECT a,b,cFROM(select a,sum (b) from A group by a) cost //-为3到6行的sql命名为costleft join ( //-这里使用左连接select a,cfrom B group by a,c )text //-为8到10行的sql命名为texton cost.a=text.a //-这里需要写清连接两段sql的字段
放下这张图,形象的表达了各种join方法,获取的数据范围。想获取对应数据时,替换上边第7行就可以用:
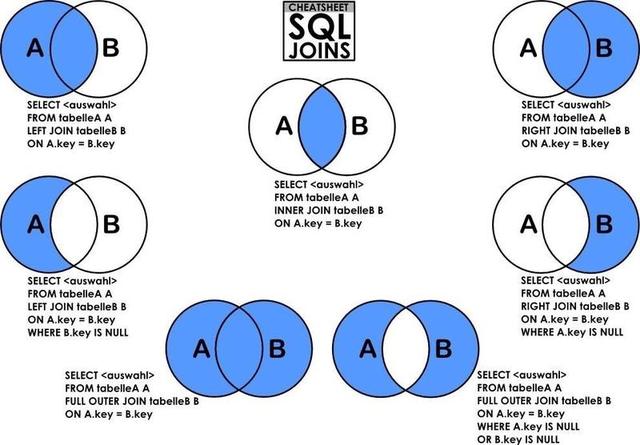
(图片来源于网络,侵删)
条件判断,对同一个字段做区分计算//if 和case when
判断一次是否//if
select a,sum (b),if (label = 'show_over', duration, 0) //这一句的意思是,当这一行数据的label是show_over的时候,取duration这个字段里的值,label不是show_over的时候,取0from A group by a
判断一次或多次是否//case when
多加判断的方式见4和5两行:
select a,sum (b),case when label = 'pv' then durationwhenlabel='play' then mockdurationelse 0end, //2到4行的意思是,当这一行数据的label是pv的时候,取duration这个字段里的值,如果label是play的时候,取duration这个字段里的值,如果还没有,就取0from A group by a
除法取整//floor
select a,floor (X/100) //-把X按100分档,0档表示X在[0,100)之间,1档表示X在[100,200)之间,以此类推from A group by a
筛选字段为空/不为空的方法//null
select a,sum (b)from A where type is not null //找出type 不是null的情况,不加"not",就是找出type 是null的情况group by a
各种常见类型字段、指定值的查询方法:
- string:加单引号即可,例如一个字段type是string,就可以写:
select a,sum (b)from A where type='1' //-string加单引号group by a
- bigint:后面加一个L,例如一个字段type是bigint,就可以写:
select a,sum (b)from A where type=1L //- bigint后加Lgroup by a
- array:XXX代表数组内的字段类型,需要根据此类型的方式取数,假设model字段的类型是array:
select a,sum (b)from A where array_contains(model,123L)group by a
- json:json经常会出现字段包字段的情况,例如常用的data是个json字段,里面会有a字段,a字段里面还会有b字段,如果想取出b,我们应该这么写:
select get_json_object(data,'$.a.b') from A
扩展阅读
一些提升效率的方法
- 时间分区有多种存储方式,查询where条件的时候需要注意:有的表是‘yymmdd’,有的表是‘yy-mm-dd’;字段名也不固定,有的表是p_date,有的表是date,但是对于单个表,分区字段一般是固定的,例如你经常查a.bcde这个表,上次他的时间分区格式是date=‘yymmdd’,下次查的时候它还会是date=‘yymmdd’;
- 有时表中的时间戳不是常见的yymmdd,而是一串数字,如果where条件里需要卡时间戳,却不知道日期对应的一串数字是什么,可使用时间戳转换器转换:https://tool.lu/timestamp/
- sql没数、跑错怎么办:有时解析功能没有发现问题,但是数据直观感觉不对,可以用如下方式自查:
- 检查相关表的分区,和你取的分区一致不一致,例如日期有多种格式,例如yymmdd,yy-mm-dd,yy-mm-dd 00:00:00等等;
- 如果sql包含多个部分,比如有join,可以把其他部分的sql注释掉,分别看每个部分的sql哪里有问题;(注释方式:代码前加“//” 例如 //select ...)
- 需要研究单个json字段的逻辑:可以用这个网址整理json字段,方便阅读:https://www.json.cn/
- 同时编辑多行,可以按住shift+alt/option,鼠标点击起始行和结束行,就能同时编辑多行了,例如批量
常用概念的解释
- 全量表和增量表
增量表:每天存下来的数据,是当天产生的所有数据,例如日记,每日走路的步数,银行每天的收支信息等;
全量表:每天存下来的数据,是从有表开始所有的数据,相当于每天抄一份历史上所有的日记,再写今天的日记,例如银行账户的余额;
- 不同数据库的区别
mysql等实时查询的数据库:一般没有分区概念,存储的数据比较少,但是响应快;
hive等离线查询数据库:有分区概念,可以较低成本的存储海量数据,支持各种复杂处理,查询速度一般比mysql慢。
转载地址:https://blog.csdn.net/weixin_34007963/article/details/113320629 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
