本文共 4103 字,大约阅读时间需要 13 分钟。
 作者丨CW 来源丨深蓝学院 编辑丨极市平台
作者丨CW 来源丨深蓝学院 编辑丨极市平台 极市导读
本文为大家介绍了BN 的多卡同步,解释了为什么需要进行同步,同步需要的信息,并详细讲解结合基于 Pytorch 实现的代码解析实现过程中的五个关键部分。 >>12月10日(周四)极市直播|汤凯华:利用因果分析解决通用的长尾分布问题
使用多GPU卡训练的情况下Batch Normalization(BN)可能会带来很多问题,目前在很多深度学习框架如 Caffe、MXNet、TensorFlow 和 PyTorch 等,所实现的 BN 都是非同步的(unsynchronized),即归一化操作是基于每个 GPU上的数据独立进行的。
本文会为大家解析 BN 的多卡同步版本,这里简称 SyncBN,首先解释为何需要进行同步,接着为大家揭晓需要同步哪些信息,最后结合基于 Pytorch 实现的代码解析实现过程中的关键部分。
文章结构:
i Why Synchronize BN:为何在多卡训练的情况下需要对BN进行同步?
ii What is Synchronized BN:什么是同步的BN,具体同步哪些东西?
iii How to implement:如何实现多卡同步的BN?
2次同步 vs 1次同步;
介绍torch.nn.DataParallel的前向反馈;
重载torch.nn.DataParallel.replicate方法;
SyncBN 的同步注册机制;
SyncBN 的前向反馈
为何在多卡训练的情况下需要对BN进行同步?
对于视觉分类和目标检测等这类任务,batch size 通常较大,因此在训练时使用 BN 没太大必要进行多卡同步,同步反而会由于GPU之间的通信而导致训练速度减慢;
然而,对于语义分割等这类稠密估计问题而言,分辨率高通常会得到更好的效果,这就需要消耗更多的GPU内存,因此其 batch size 通常较小,那么每张卡计算得到的统计量可能与整体数据样本具有较大差异,这时候使用 BN 就有一定必要性进行多卡同步了。
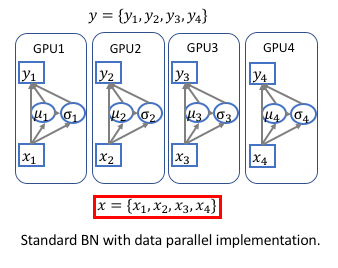
多卡情况下的BN(非同步)
这里再提一点,如果使用pytorch的torch.nn.DataParallel,由于数据被可使用的GPU卡分割(通常是均分),因此每张卡上 BN 层的batch size(批次大小)实际为 ,下文也以torch.nn.DataParallel为背景进行说明。
,下文也以torch.nn.DataParallel为背景进行说明。 什么是同步的BN,具体同步哪些东西?
由开篇至今,CW 一直提到“同步”这两个字眼,那么到底是什么是同步的BN,具体同步的是什么东西呢?
同步是发生在各个GPU之间的,需要同步的东西必然是它们互不相同的东西,那到底是什么呢?或许你会说是它们拿到的数据,嗯,没错,但肯定不能把数据同步成一样的了,不然这就和单卡训练没差别了,浪费了多张卡的资源...
现在,聪明的你肯定已经知道了,需要同步的是每张卡上计算的统计量,即 BN 层用到的 (均值)和
(均值)和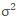 (方差),这样子每张卡对其拿到的数据进行归一化后的效果才能与单卡情况下对一个 batch 的数据归一化后的效果相当。
(方差),这样子每张卡对其拿到的数据进行归一化后的效果才能与单卡情况下对一个 batch 的数据归一化后的效果相当。
因此,同步的 BN,指的就是每张卡上对应的 BN 层,分别计算出相应的统计量和,接着基于每张卡的计算结果计算出统一的 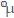 和,然后相互进行同步,最后它们使用的都是同样的
和,然后相互进行同步,最后它们使用的都是同样的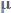 和。
和。
如何实现多卡同步的BN?
2次同步 vs 1次同步
我们已经知道,在前向反馈过程中各卡需要同步均值和方差,从而计算出全局的统计量,或许大家第一时间想到的方式是先同步各卡的均值,计算出全局的均值,然后同步给各卡,接着各卡同步计算方差...这种方式当然没错,但是需要进行2次同步,而同步是需要消耗资源并且影响模型训练速度的,那么,是否能够仅用1次同步呢?
全局的均值很容易通过同步计算得出,因此我们来看看方差的计算:
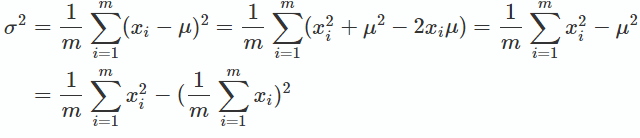
方差的计算,其中m为各GPU卡拿到的数据批次大小()。
由上可知,每张卡计算出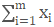 和
和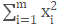 ,然后进行同步求和,即可计算出全局的方差。同时,全局的均值可通过各卡的同步求和得到,这样,仅通过1次同步,便可完成全局均值及方差的计算。
,然后进行同步求和,即可计算出全局的方差。同时,全局的均值可通过各卡的同步求和得到,这样,仅通过1次同步,便可完成全局均值及方差的计算。
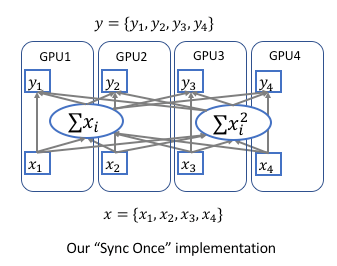
1次同步完成全局统计量的计算
2. 介绍nn.DataParallel的前向反馈
熟悉 pytorch 的朋友们应该知道,在进行GPU多卡训练的场景中,通常会使用nn.DataParallel来包装网络模型,它会将模型在每张卡上面都复制一份,从而实现并行训练。这里我自定义了一个类继承nn.DataParallel,用它来包装SyncBN,并且重载了nn.DataParallel的部分操作,因此需要先简单说明下nn.DataParallel的前向反馈涉及到的一些操作。

nn.DataParallel的使用,其中DEV_IDS是可用的各GPU卡的id,模型会被复制到这些id对应的各个GPU上,DEV是主卡,最终反向传播的梯度会被汇聚到主卡统一计算。
先来看看nn.DataParallel的前向反馈方法的源码:
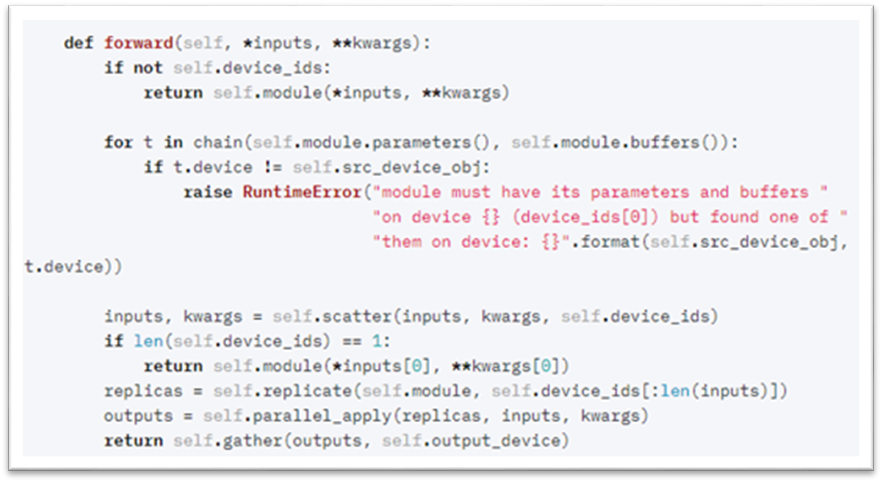
nn.DataParallel.forward
其中,主要涉及调用了以下4个方法:
(1) scatter:将输入数据及参数均分到每张卡上;
(2) replicate:将模型在每张卡上复制一份(注意,卡上必须有scatter分割的数据存在!);
(3) parallel_apply:每张卡并行计算结果,这里会调用被包装的具体模型的前向反馈操作(在我们这里就是会调用 SyncBN 的前向反馈方法);
(4) gather:将每张卡的计算结果统一汇聚到主卡。
注意,我们的关键在于重载replicate方法,原生的该方法只是将模型在每张卡上复制一份,并且没有建立起联系,而我们的 SyncBN 是需要进行同步的,因此需要重载该方法,让各张卡上的SyncBN 通过某种数据结构和同步机制建立起联系。
3. 重载nn.DataParallel.replicate方法
在这里,可以设计一个继承nn.DataParallel的子类DataParallelWithCallBack,重载了replicate方法,子类的该方法先是调用父类的replicate方法,然后调用一个自定义的回调函数(这也是之所以命名为DataParallelWithCallBack的原因),该回调函数用于将各卡对应的 SyncBN 层关联起来,使得它们可以通过某种数据结构进行通信。
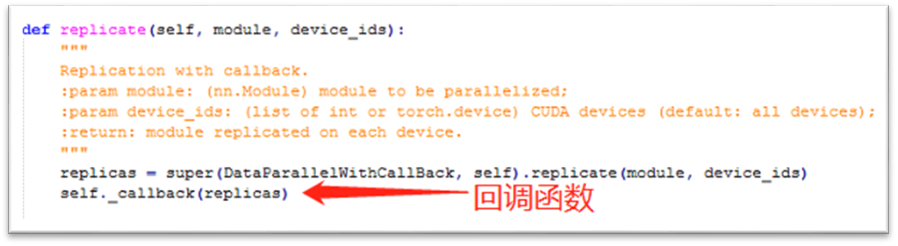
子类重载的replicate方法
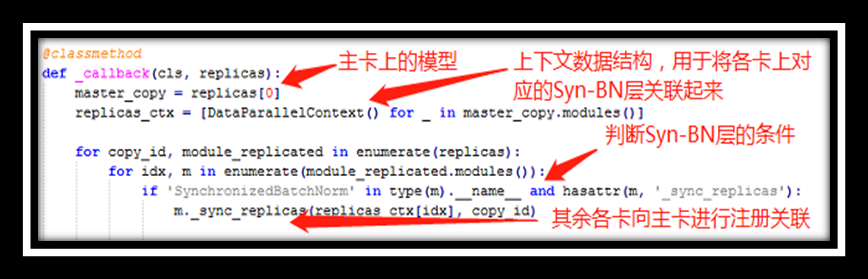
自定义的回调函数,将各卡对应的Syn-BN层进行关联,其中DataParallelContext是一个自定义类,其中没有定义实质性的东西,作为一个上下文数据结构,实例化这个类的对象主要用于将各个卡上对应的Syn-BN层进行关联;_sync_replicas是在Syn-BN中定义的方法,在该方法中其余子卡上的Syn-BN层会向主卡进行注册,使得主卡能够通过某种数据结构和各卡进行通信。
4. Syn-BN的同步注册机制
由上可知,我们需要在 SyncBN 中实现一个用于同步的注册方法,SyncBN 中还需要设置一个用于管理同步的对象(下图中的 _sync_master),这个对象有一个注册方法,可将子卡注册到其主卡。
在 SyncBN 的方法中,若是主卡,则将上下文管理器的 sync_master 属性设置为这个管理同步的对象(_sync_master);否则,则调用上下文对象的同步管理对象的注册方法,将该卡向其主卡进行注册。
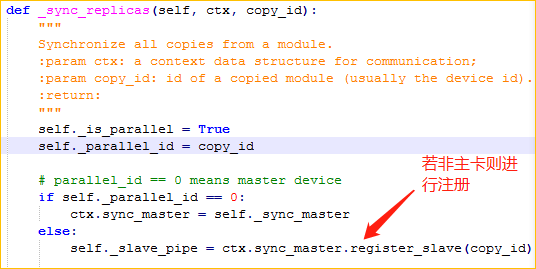
Syn-BN的同步注册机制
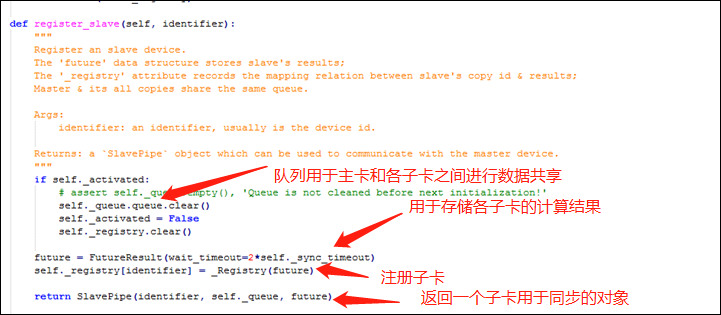
主卡进行同步管理的类中注册子卡的方法
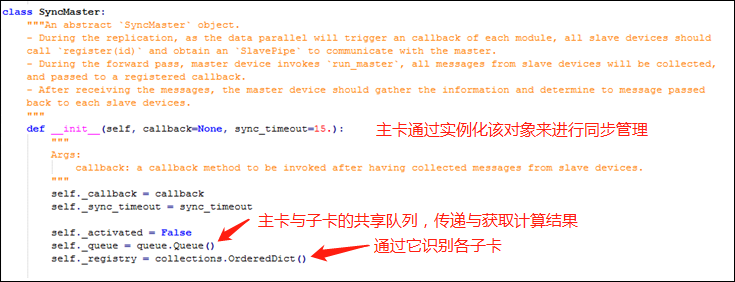
主卡进行同步管理的类

子卡进行同步操作的类
5. Syn-BN的前向反馈
如果你认真看完了以上部分,相信这部分你也知道大致是怎样一个流程了。
首先,每张卡上的 SyncBN 各自计算出 mini-batch 的和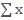 以及平方和
以及平方和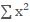 ,然后主卡上的 SyncBN 收集来自各个子卡的计算结果,从而计算出全局的均值和方差,接着发放回各个子卡,最后各子卡的 SyncBN 收到来自主卡返回的计算结果各自进行归一化(和缩放平移)操作。当然,主卡上的 SyncBN 计算出全局统计量后就可以进行它的归一化(和缩放平移)操作了。
,然后主卡上的 SyncBN 收集来自各个子卡的计算结果,从而计算出全局的均值和方差,接着发放回各个子卡,最后各子卡的 SyncBN 收到来自主卡返回的计算结果各自进行归一化(和缩放平移)操作。当然,主卡上的 SyncBN 计算出全局统计量后就可以进行它的归一化(和缩放平移)操作了。
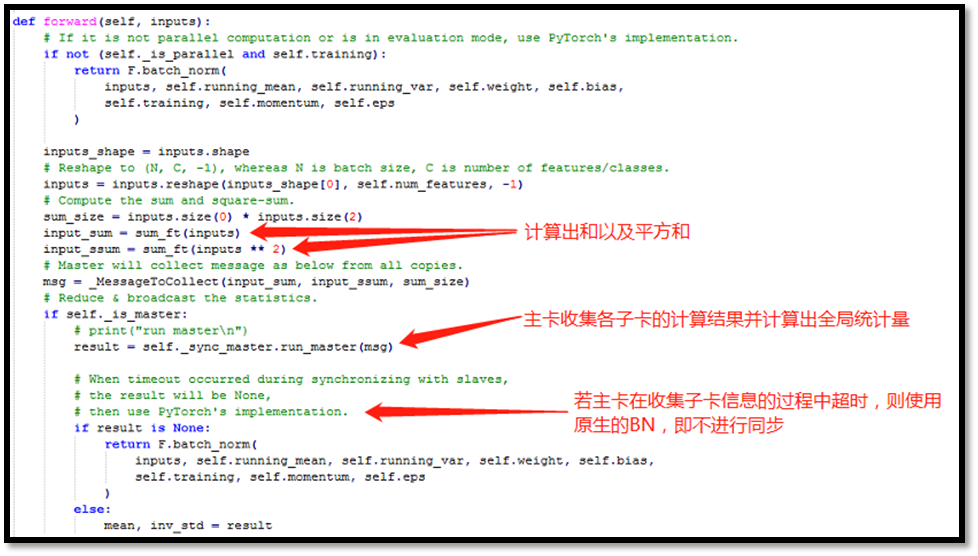
Syn-BN前向反馈(主卡)
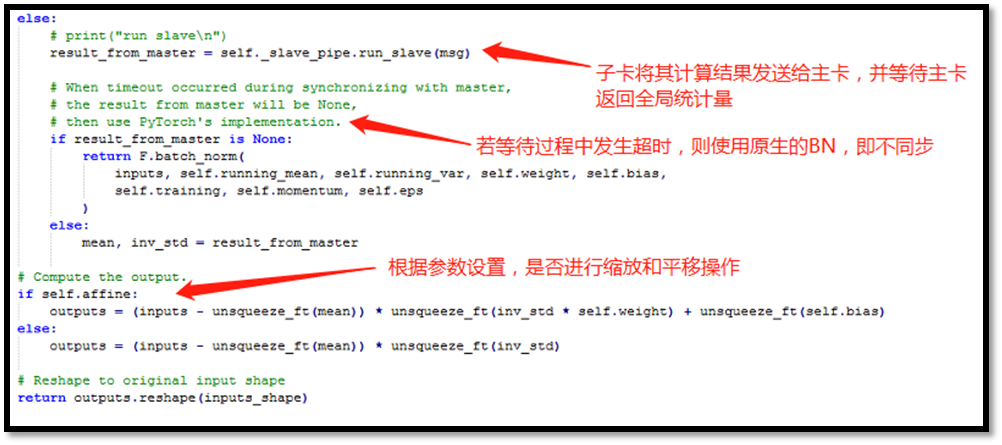
Syn-BN前向反馈(子卡)
总结
在同步过程中,还涉及线程和条件对象的使用,这里就不展开叙述了,感兴趣的朋友可以到SyncBN源码链接:
https://github.com/chrisway613/Synchronized-BatchNormalization
另外,在信息同步这部分,还可以设计其它方式进行优化,如果你有更好的意见,还请积极反馈,CW热烈欢迎!
作者介绍:CW,广东深圳人,毕业于中山大学(SYSU)数据科学与计算机学院,毕业后就业于腾讯计算机系统有限公司技术工程与事业群(TEG)从事Devops工作,期间在AI LAB实习过,实操过道路交通元素与医疗病例图像分割、视频实时人脸检测与表情识别、OCR等项目。目前也有在一些自媒体平台上参与外包项目的研发工作,项目专注于CV领域(传统图像处理与深度学习方向均有)。
推荐阅读
Batch Normalization的诅咒
在“内卷”、“红海”的2020 年,开垦计算机视觉领域的知识荒原:BatchNorm
深入探讨:为什么要做特征归一化/标准化?

 △长按添加极市小助手
△长按添加极市小助手  △长按关注极市平台,获取 最新CV干货 觉得有用麻烦给个在看啦~
△长按关注极市平台,获取 最新CV干货 觉得有用麻烦给个在看啦~ 
转载地址:https://blog.csdn.net/weixin_33865450/article/details/112571966 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
