本文共 6719 字,大约阅读时间需要 22 分钟。
关于java集合的的汇总,轩成笔记
1 Java集合简介
Java是一门面向对象的语言,就免不了处理对象,为了方便操作多个对象,那么我们就得把这多个对象存储起来,想要存储多个对象(变量),很容易就能想到一个容器(集合)来装载
简单来说集合就是“由若干个确定的元素所构成的整体”。就是Java给我们提供了工具方便我们去操作多个Java对象。
- 1.集合只能存放对象。比如你存入一个int型数据66放入集合中,其实它是自动转换成Integer类后存入的,Java中每一种基本数据类型都有对应的引用类型。
- 2.集合存放的都是对象的引用,而非对象本身。所以我们称集合中的对象就是集合中对象的引用。对象本身还是放在堆内存中。
- 3.集合可以存放不同类型,不限数量的数据类型。
1.1 如何学习集合
首先需要了解集合的分类,以及集合用法(看api),实现类,各有什么功能和不同,这在面试中经常会考到,再一个就是从数据结构层面底层去考虑这些问题,虽然以后在工作中多数人都不会涉及,但是这是考验学习能力的一种方式。
1.2 集合的主要三种类型
- List:一种有序列表的集合,例如,按索引排列的Student的List;
- Set:一种保证没有重复元素的集合,例如,所有无重复名称的Student的Set;
- Map:一种通过键值(key-value)查找的映射表集合,例如,根据Student的name查找对应Student的Map。
1.2 关于使用集合的心得
- 如果是集合类型,有List和Set供我们选择。List的特点是插入有序的,元素是可重复的。Set的特点是插入无序的,元素不可重复的。至于选择哪个实现类来作为我们的存储容器,我们就得看具体的应用场景。是希望可重复的就得用List,选择List下常见的子类。是希望不可重复,选择Set下常见的子类。
- 如果是Key-Value型,那我们会选择Map。如果要保持插入顺序的,我们可以选择LinkedHashMap,如果不需要则选择HashMap,如果要排序则选择TreeMap。
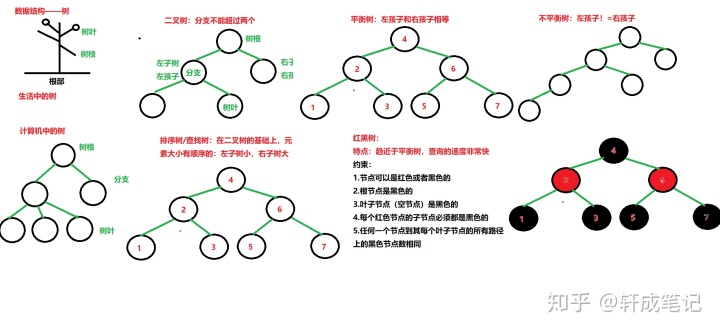
常见的数据结构
数据结构指的是数据的组存储方式,不同的数据结构有不同的特点。
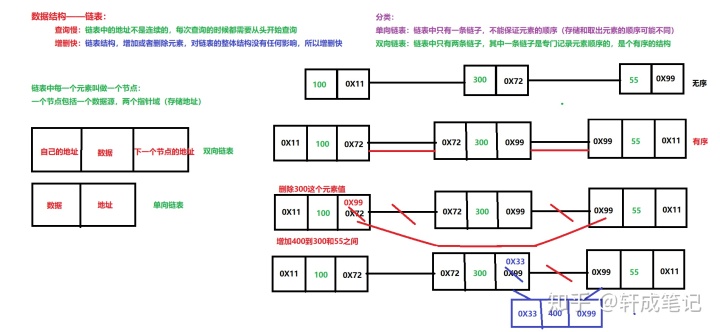
- 数组结构(ArrayList底层结构) 查询快,增删慢
- 链表结构(LinkedList底层结构) 查询慢,增删快
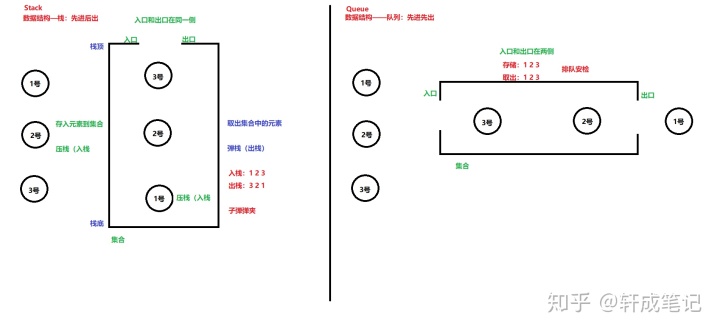
- 栈和队列 栈:先进后出(子弹夹,杯子) 队列:先进先出(排队,管子)
栈和队列
树
链表
2 集合的分类
2.1.常用集合的归纳:
List 接口:元素按进入先后有序保存,可重复
- LinkedList 接口实现类, 链表, 插入删除, 没有同步, 线程不安全
- ArrayList 接口实现类, 数组, 随机访问, 没有同步, 线程不安全
- Vector 接口实现类 数组, 同步, 线程安全(Stack 是Vector类的实现类)
Set 接口: 仅接收一次,不可重复,并做内部排序
- HashSet 使用hash表(数组)存储元素
- LinkedHashSet 链表维护元素的插入次序
- TreeSet 底层实现为二叉树,元素排好序
2.2.最主要是看图:
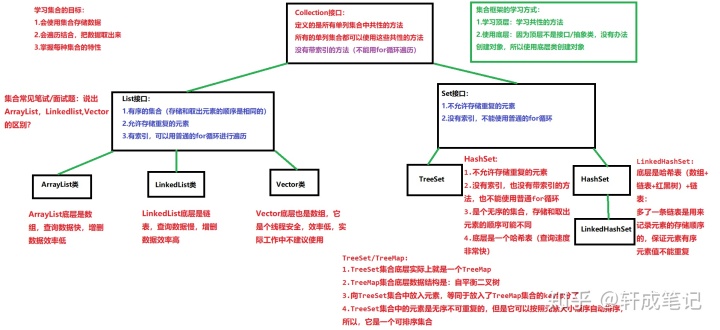
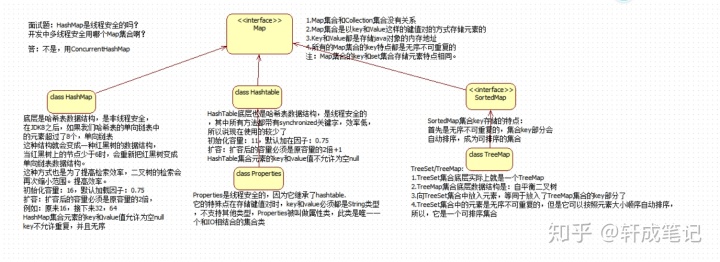
常见面试笔试题:Arraylist,LinkedList,Vector的区别

集合与数组的区别
数组和集合的区别:
- 1:长度的区别
- 数组的长度固定
- 集合的长度可变
- 2:内容不容
- 数组存储的是同一种类型的元素
- 集合可以存储不同类型的元素(但是一般我们不这样干..)
- 3:元素的数据类型
- 数组可以存储基本数据类型,也可以存储引用类型
- 集合只能存储引用类型(你存储的是简单的int,它会自动装箱成Integer)
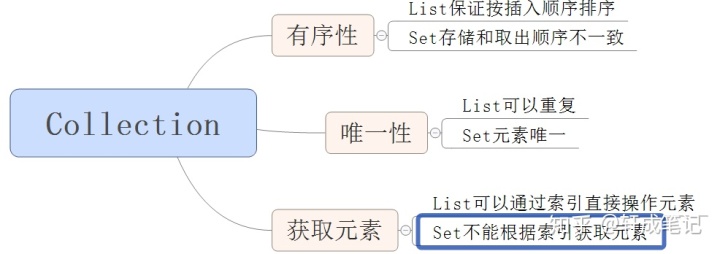
3.Collection
Collection常见方法
- 添加功能 boolean add(E e) 添加一个元素 boolean addAll(Collection c)添加一批元素
- 删除功能 boolean remove(Object o) 删除一个元素
- 判断功能 boolean contains(Object o) 判断集合是否包含指定的元素 boolean isEmpty()判断集合是否为空(集合中没有元素)
- 获取功能 int size()获取集合的长度
- 转换功能 Object[] toArray() 把集合转换为数组
Collection:使用技巧
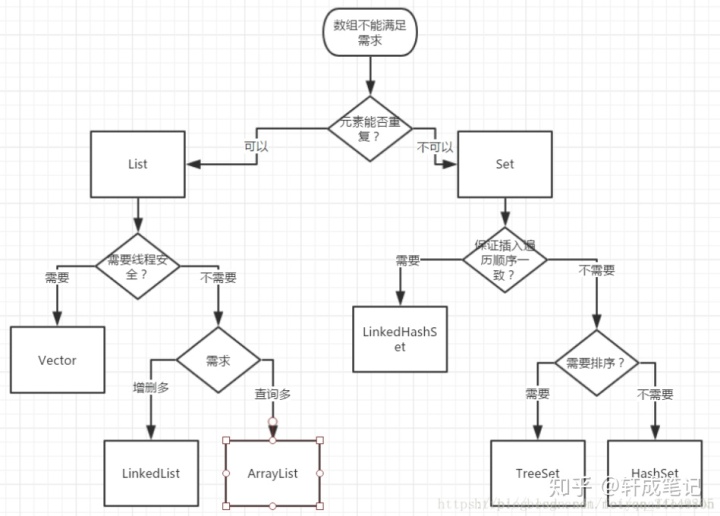
3.1 list和set的区别:
3.2 list
- ArrayList:底层数据结构是数组,查询快,增删慢,线程不安全,效率高,可以存储重复元素
- LinkedList 底层数据结构是链表,查询慢,增删快,线程不安全,效率高,可以存储重复元素
- Vector:底层数据结构是数组,查询快,增删慢,线程安全,效率低,可以存储重复元素
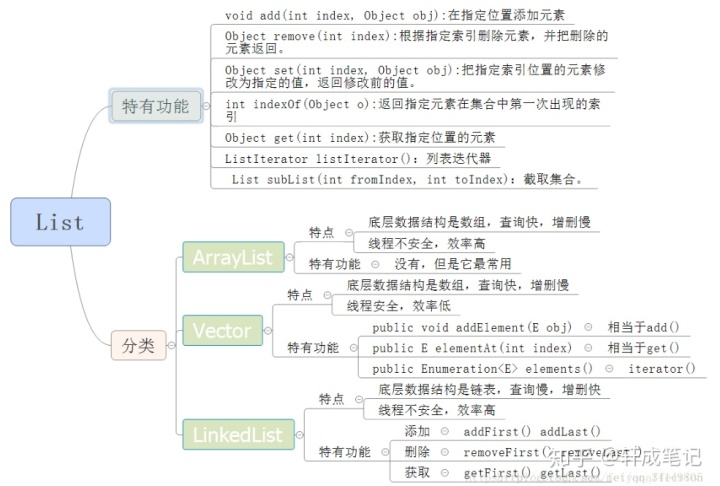
list常见方法
1.add(int index, Object ele)
2.boolean addAll(int index, Collection eles)
3.Object get(int index)
http://4.int indexOf(Object obj)
http://5.int lastIndexOf(Object obj)
6.Object remove(int index)
7.Object set(int index, Object ele)
8.List subList(int fromIndex, int toIndex)
3.3 set集合
Set集合的特点是:元素不可重复
- HashSet集合
- 底层数据结构是哈希表(是一个元素为链表的数组)
- 不能保证元素的顺序。
- HashSet不是线程同步的,如果多线程操作HashSet集合,则应通过代码来保证其同步。
- 集合元素值可以是null。
- 影响哈希冲突的条件,首先看哈希值是否相等,然后判断equals是否相等(内容是否相等)
- TreeSet集合
- A:底层数据结构是红黑树(是一个自平衡的二叉树)
- B:保证元素的排序方式(自然排序),实现Comparable接口
- LinkedHashSet集合
- A::底层数据结构由哈希表和链表组成。
- 原来存储是什么顺序,就是什么顺序
各Set实现类的性能分析
- HashSet的性能比TreeSet的性能好(特别是添加,查询元素时),因为TreeSet需要额外的红黑树算法维护元素的次序,如果需要一个保持排序的Set时才用TreeSet,否则应该使用HashSet。
- LinkedHashSet是HashSet的子类,由于需要链表维护元素的顺序,所以插入和删除操作比HashSet要慢,但遍历比HashSet快。
- EnumSet是所有Set实现类中性能最好的,但它只能 保存同一个枚举类的枚举值作为集合元素。
- 以上几个Set实现类都是线程不安全的,如果多线程访问,必须手动保证集合的同步性,这在后面的章节中会讲到。
3.4遍历Collection集合的方式
1.普通的for循环【必须要有索引,可以修改元素】
- 注意set集合是无序的不能使用普通for循环遍历,只能使用增强for或者迭代器遍历
import java.util.*;public class test{ public static void main(String[] args) { ArrayList list = new ArrayList (); list.add("Hello"); list.add("Java"); list.add("World"); list.add("轩成笔记"); for (int i = 0; i < list.size(); i++){ String s = (String) list.get(i); System.out.println(s); } }} 2.迭代器遍历【任何集合都可以遍历,只能获取元素】
- 只要是Collection集合都适合
- 它是Java集合的顶层接口(不包括map系列的集合,Map接口是map系列集合的顶层接口)
1. Object next():返回迭代器刚越过的元素的引用,返回值是Object,需要强制转换成自己需要的类型。
2. boolean hasNext():判断容器内是否还有可供访问的元素。
3. void remove():删除迭代器刚越过的元素。
- 所以除了map系列的集合,我么都能通过迭代器来对集合中的元素进行遍历。
- 注意:我们可以在源码中追溯到集合的顶层接口,比如Collection接口,可以看到它继承的是类Iterable
import java.util.*;public class test{ public static void main(String[] args) { Collection c = new ArrayList (); c.add("Hello"); c.add("Java"); c.add("World"); c.add("轩成笔记"); //获取迭代器对象 Iterator it = c.iterator(); //hasNext()判断是否有下一个元素,如果有就用next()获取 while(it.hasNext()){ //获取下一个元素 String s = it.next(); System.out.println(s); } }} 3.高级for循环【就是迭代器的简化方式】
import java.util.*;public class test{ public static void main(String[] args) { Collection c = new HashSet (); c.add("Hello"); c.add("Java"); c.add("World"); c.add("轩成笔记"); //高级for遍历集合 for (String s : c){ System.out.println(s); } int[] arr = {1, 2, 3, 4, 5}; //高级for遍历数组 for (int a : arr){ System.out.println(a); } }} 4.1 Map详解:
- Map用于保存具有映射关系的数据,Map里保存着两组数据:key和value,它们都可以使任何引用类型的数据,但key不能重复。所以通过指定的key就可以取出对应的value
- Collection中的集合,元素是孤立存在的(理解为单身),向集合中存储元素采用一个个元素的方式存储。 Map中的集合,元素是成对存在的(理解为夫妻)。每个元素由键与值两部分组成,通过键可以找对所对应的 值。
- Collection中的集合称为单列集合,Map 中的集合称为双列集合。需要注意的是,Map中的集合不能包含重复的键,值可以重复;每个键只能对应一个值。
map图解
4.2 map主要方法

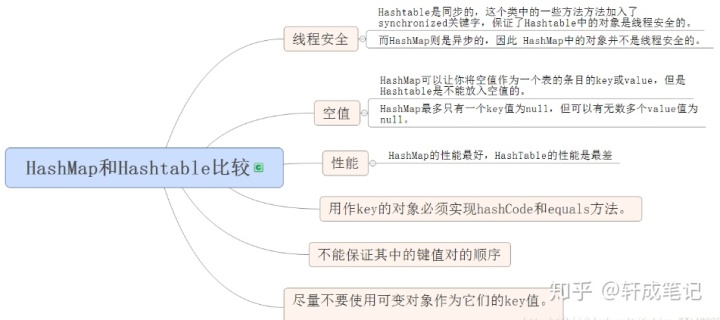
4.3 HashMap和HashTable的比较:
4.4 TreeMap

4.4 map小结
- HashMap 非线程安全
- HashMap:基于哈希表实现。使用HashMap要求添加的键类明确定义了hashCode()和equals()[可以重写hashCode()和equals()],为了优化HashMap空间的使用,您可以调优初始容量和负载因子。
- TreeMap:非线程安全基于红黑树实现。TreeMap没有调优选项,因为该树总处于平衡状态。
4.5 map各类实用场景
HashMap和HashTable:HashMap去掉了HashTable的contains方法,但是加上了containsValue()和containsKey()方法。HashTable同步的,而HashMap是非同步的,效率上比HashTable要高。HashMap允许空键值,而HashTable不允许。
HashMap:适用于Map中插入、删除和定位元素。 Treemap:适用于按自然顺序或自定义顺序遍历键(key)。
map的两种遍历方式KeySet、entrySet
1. Map集合的第一 种遍历方式:通过键找值的方式
方法: Set keySet() 返回此地图中包含的键的Set视图。 实现步骤:
- 使用keySet() ,把Map集合中的所有的key取出来,存入到一-个Set集合中
- 遍历set集合,获取到Map集合中的每一 个key
- 通过Map集合中的V get(0bject key), 获取到所有的Value值,输出
public class MapTest02 { public static void main(String[] args) { Map map = new HashMap<>(); map. put( "赵丽颖", 168); map. put("杨颖" ,165); map. put("林志颖" ,155); Set Set = map.keySet();//返回的是一个set集合 for (String key : Set) { Integer value = map.get(key); System.out.println(key+" "+value); } }} 2.Map集合的第二种遍历方式: 使用Entry 对象遍历
- Entry:键值对(key-value)
- 方法:
- Map接口:
- Set<Map. Entry<K, V>> entrySet() 返回此地图中包含的映射的Set视图。
- java. util Interface Map. Entry<K, V>:
- K getKey()返回与此条目相对应的键。
- V getValue() 返回与此条目相对应的值。
- 实现步骤:
- 使用Map集合中的entrySet()方法,把集合中多个Entry对象取出来,存储到一个Set 集合中
- 遍历Set集合,获取到每一个Entry
- 调用Entry中的getKey()和IgetValue()方法获取键和值
public class MapTest03 { public static void main(String[] args) { Map map = new HashMap<>(); map. put( "赵丽颖", 168); map. put("杨颖" ,165); map. put("林志颖" ,155); Set > set = map.entrySet(); for (Map.Entry entry : set) { System.out.println(entry.getKey()+entry.getValue()); } }} 制作者:轩成笔记
转载地址:https://blog.csdn.net/weixin_33362096/article/details/112122678 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
