本文共 5313 字,大约阅读时间需要 17 分钟。
相关阅读(点击即可阅读哦~):
Linux0.11写时复制机制详解
LINUX0.11信号机制
Linux0.11共享内存机制
为了提高系统访问块设备的速度,内核在内存中开辟了一块高速缓冲区,将其划分为一个个与磁盘块大小相等的缓冲块来暂存与块设备之间的交换数据,以减少I/O操作的次数,提高系统的性能。缓冲块中保存着最近访问磁盘的数据,内核在读块设备之前先搜索缓冲区,如果数据在缓冲区中就不需要再从磁盘中读,否则向块设备发出度的指令。当内核写块设备时,先将数据写入缓冲区,什么时候将数据同步到块设备视具体情况而定,这样做是为了尽可能久地将数据停留在内存以减少对块设备的操作。
一、缓冲区布局
高速缓冲区位于system模块和主内存区之间(如果没有定义虚拟盘)。system模块是内核代码所在的区域,主内存区则是在内存管理模块的管理下统一分配给进程使用的空间。
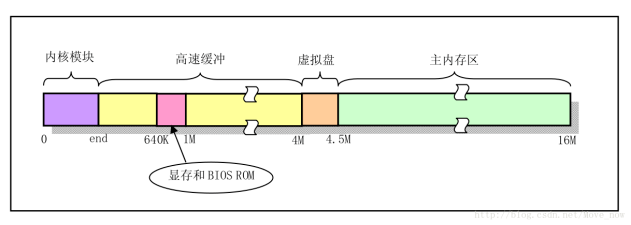
缓冲区的位置
缓冲区是从内核模块的末端end标记变量处开始,end变量由链接程序ld生成system模块时自动生成,表示程序末端。

init/main.c
在main函数中初始化高速缓冲区末端为4MB,然后调用函数buffer_init(buffer_memory_end)把缓冲区划分为一个个缓冲块,完成缓冲区的初始化。
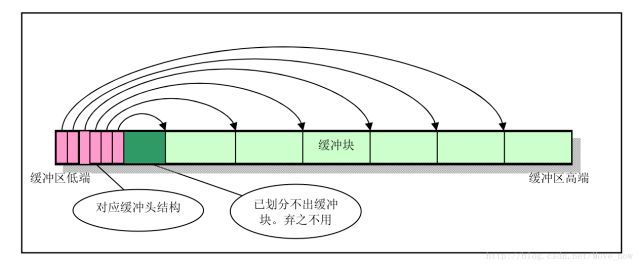
缓冲区结构
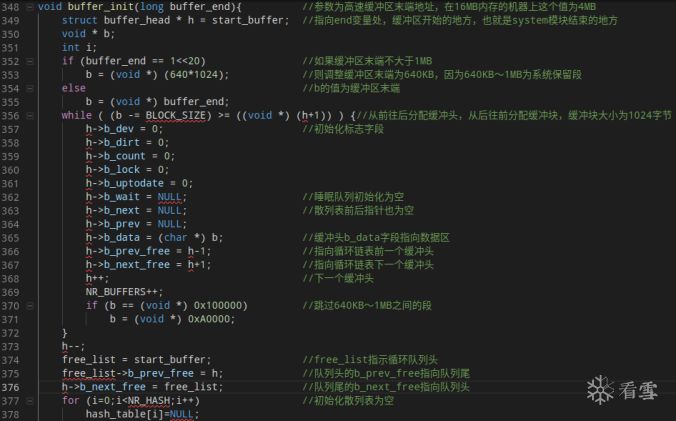
缓冲块由缓冲头区和数据区组成。缓冲头区位于缓冲区的低地址处,数据区位于缓冲区高地址处,每个缓冲头中都有一个指针指向对应的缓冲块。由于640KB~1MB之间为显存和为BIOS预留的空间,所以在初始化的时候要跳过这部分区域。

include/linux/fs.h
b_lock字段表示是否有块设备驱动程序正在操作该缓冲块,“1”表示驱动正在读写该块,“0”表示空闲。主要是kernel/blk_drv/ll_rw_blk.c对缓冲块进行读写操作时不允许进程占用缓冲块,否则会导致数据错误,此时就需要进程主动去睡眠,等待读写完毕唤醒后再去操作缓冲块。
b_count字段表示该缓冲块被多少个进程引用,如果b_lock为1则b_count一定也为1。当b_count为0时表示该块空闲内核才能释放缓冲块。b_dirt为延迟写字段,当缓冲区数据因为修改而与磁盘上数据不同时,b_dirt字段置1,表示在下次需要读写该块时需要先将数据同步到设备,同步到设备后b_dirt置0。
b_uptodate为数据有效位字段,表示缓冲块中数据是否能拿来给进程使用。初始化和释放时置0表示数据无效不能拿来给进程使用;刚从设备读入或者刚同步到设备时置1表示数据有效,进程所需要的数据即是当前盘块的数据。
所有的缓冲头buffer_head都通过b_prev和b_next指针连接成一个双向循环链表结构,这个循环链表也称为“LUR队列”,free_list是一个buffer_head类型的指针,指示了循环链表的头部,也就是最近最少使用的缓冲块(最闲的块),而链表的尾部则是最近刚刚使用的缓冲块(最忙的块)。每次搜索循环链表都从头部“最空闲的块”开始,如果找到了合适的块则将其摘下并链接在循环链表的尾部成为了“最忙的块”。
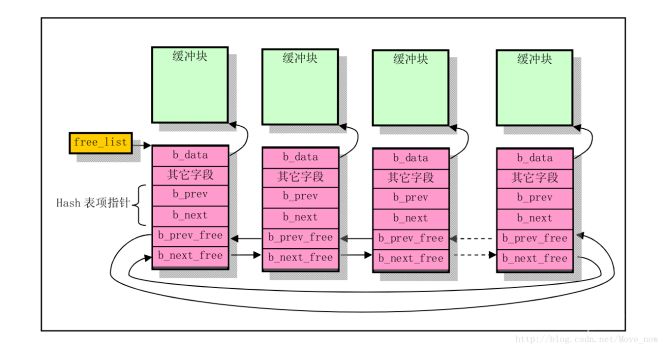
循环双向链表结构
为了快速寻找要请求的数据块是否已经读入了缓冲区,linux0.11使用了有307个缓冲头指针的hash表,散列函数为(b_blocknr ^ b_dev)mod 307。
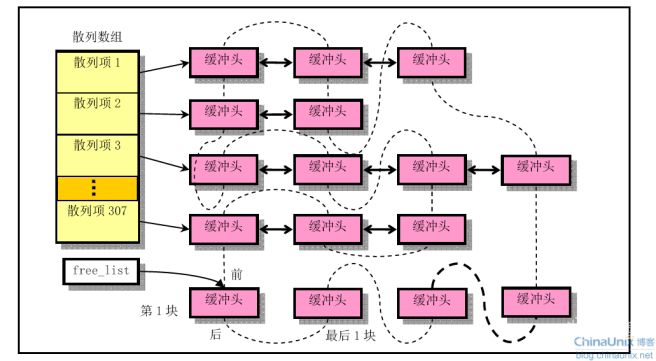
缓冲区散列表结构
每个缓冲块都在free_list指向的双向链表中但可以不在散列表中。缓冲块一旦被使用过就会一直停留在hash表中,直到再次被选中,继续使用之前进程用过的这个盘块数据,或者修改b_blocknr和b_dev字段后重新插入到新的散列项中用于放其他盘块的数据。
fs/buffer.c
二、设计思路
内核搜索合适的缓冲块有两种方法,一种是搜索散列表,另一种是搜索LUR队列。初始时散列表为空,内核分配LUR队列的第一个块,也就是“最空闲”的块,设置其b_blocknr和b_dev字段,根据这两个字段把缓冲头加入到散列表中,同时将其从LUR队列头移到队列尾,表明该块“最忙”。所以缓冲块一旦被使用过,他的缓冲头就会记录在散列表中。
内核搜索缓冲块时,首先根据请求的逻辑块号和设备号对应的散列值搜索散列表,寻找之前是否有进程已经请求过相同的盘块。如果没有则遍历LUR队列,找出最合适的一个块将其从LUR队列和散列队列(如果在散列表中的话)中拆下,接在LUR队列末尾和散列表的合适位置。
内核在请求缓冲块时可能会遇到以下几种情况:
散列表中找到了请求的块,并且该块空闲;
散列表中找到了请求的块,但是已被锁定;
散列表中未找到,搜索LUR队列找到一个空闲且“干净”的块;
散列表中未找到,搜索LUR队列找到一个空闲的合适的块;
散列表中未找到,LUR队列中也没有合适的块。
第一种情况,进程a请求了逻辑块x,x对应的缓冲块x’进入散列表,驱动对x’写数据完毕,x’解锁。此时切换到进程b也需要请求逻辑块x,于是搜索散列表发现x’未锁定,于是直接增加x’的引用数使用x’。
第二种情况,进程a请求了逻辑块x,x对应的缓冲块x’进入散列表,驱动正在对x’写数据,x’上锁。此时切换到进程b也需要请求逻辑块x,于是搜索散列表发现x’已锁定,于是b进入睡眠等待x’解锁。x’解锁后唤醒进程b,此时仅仅是将b设置为就绪态而并未切换到b进程,有可能此时切换到c,c通过搜索LRU队列找到了x’将x’挪作他用,所以进程b被唤醒后还要检查一下是否还是原来的块,如果不是则要重新搜索。
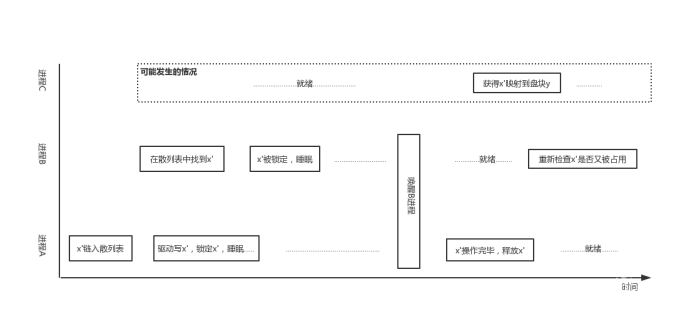
第二种情况
第三种情况,getblk函数首先搜索散列表没有找到需要的块,说明该盘块从未被读写过,或者之前被读写但释放后又被其他进程映射到另外的盘块上。然后搜索LUR队列找到了一个b_count=0且b_dirt=0的块,直接返回缓冲头指针。
第四种情况,getblk函数首先搜索散列表没有找到需要的块,然后搜索LUR队列找到了一个合适的块。合适就是选择的优先级,在b_count=0的前提下,按照下面的优先级选择合适的块:
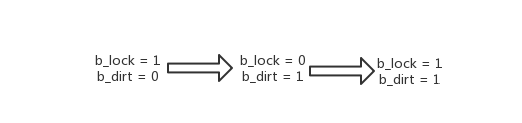
选择优先级
优先选择被锁定但“干净”的块,然后是未锁定但是“脏”的块,最后才是既锁定又“脏”的块。这么做从系统开销的角度看是有道理的,这三种情况的可能的I/O开销是递增的。
第一种情况I/O开销为0,只需要等待已有的I/O结束解锁缓冲就可以了;第二种情况需要同步块设备,包含了一个完整的I/O操作;第三种情况既需要等待已有I/O结束,又需要同步块设备,系统开销无疑是最大的。然而这三种情况又都需要使当前进程睡眠以等待驱动完成,不可避免又要遇到竞争条件的问题。所以进程唤醒之后都要检查一下所等待的块是否又被其他进程占用,也就是检查b_count是否为0,如果不为0则表示在进程睡眠期间该块被占用,需要重新开始搜索。
这里可能会有疑问,既然b_count=0那么说明此块空闲,怎么还会有b_lock=1的情况呢?其实在getblk函数的调用者bread、breada、bread_page函数中,都是通ll_rw_block向驱动发出读写设备的命令,这里会对缓冲块上锁,发出读写命令后再释放缓冲块。所以这种情况就是异步写,在缓冲同步至设备期间不影响缓冲块的分配,无疑又提高了系统的运行效率。
第五种情况,散列表中未找到,LUR队列中也没有b_count=0的块,说明此时缓冲区已经耗尽,需要加入到等待缓冲区的队列中。如果任何一个进程释放一个缓冲块就会唤醒等待队列。进程A唤醒后需要重新开始搜索。
以上便是getblk要处理的五种情况。每次进程被唤醒都要从散列表开始重新搜索整个缓冲区。因为在进程A被唤醒还处于就绪态的过程中,可能先切换到了进程B,而B进程可能已经将A需要的盘块映射到了缓冲,所以A请求的块可能已经加到了散列表中。
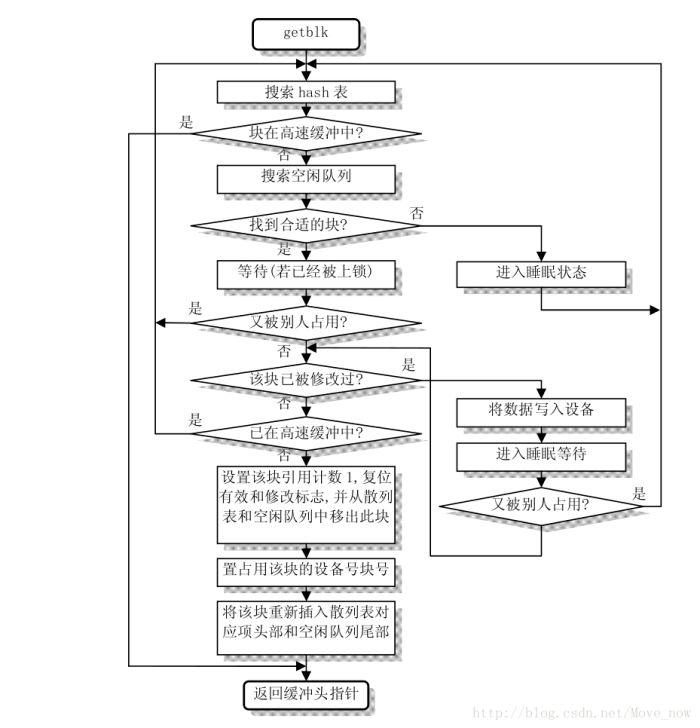
综上所述,当一个缓冲块已经同步至设备、解锁、引用数为0的时候才能分配给进程使用getblk的整个逻辑借用网上其他高手的一副流程图来表示:
三、代码解析
1、getblk
getblk是整个缓冲区机制的核心,它负责从所有缓冲块中找到一个最合适的块分配给进程使用。
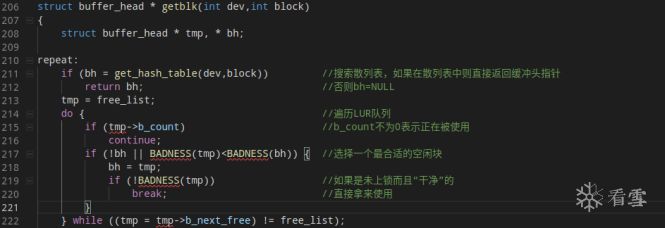
fs/buffer.c
getblk首先在散列表中寻找所需要的块,如果没有找到则到LUR队列中寻找最为合适的块。
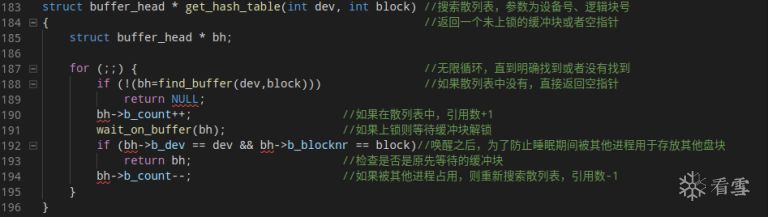
fs/buffer.c
get_hash_table用于在散列表中找到一个没有被锁定的块,如果发现请求的块已被上锁则进入睡眠等待该块解锁。

fs/buffer.c
wait_on_buffer等待指定缓冲块解锁。在进入睡眠之前首先要把中断关掉,这样当处理睡眠队列时就不会出现竞争条件的情况。这里需要注意的是关闭中断并不会影响到其他进程对中断的响应,因为每个进程都有自己的EFLAGS标志都保存在本进程的TSS结构中,进程切换时会将TSS中的寄存器值恢复。有可能从进程被唤醒到运行这之间缓冲块会再次被其他进程上锁,所以这里用了while循环,一旦再次被上锁就继续睡眠。

fs/buffer.c
BADNESS得到的是缓冲块的相对使用开销,数值上等于b_lock+b_dirt×2,值越小表示使用该块的系统开销越小,优先选择该块。可见是否标记“延迟写”对BADNES的计算结果有很大影响。如果块既未锁定又是“干净的”,则可以使用直接退出循环。

fs/buffer.c
我们再次回到getblk中。bh为空则说明散列表和LUR队列都找不到可以使用的缓冲块,说明此时每个块都被使用,缓冲区已经耗尽。这时候就要把进程加入到等待缓冲区的睡眠队列中,全局变量buffer_wait指示了睡眠队列头。如果某个进程释放了一个缓冲块则唤醒进程进入到就绪态,一旦切换回来就要重新搜索缓冲区。

fs/buffer.c
如果从LUR队列中找到的块被上锁,则睡眠等待该块被解锁;如果唤醒后发现该块又被其他进程占用,则重新开始搜索;如果被标记为“延迟写”,则将缓冲区内容同步至设备,同时进程进入睡眠等待同步过程的完成;唤醒后发现该块又被占用则重新开始搜索。

fs/buffer.c
经过前面的几次睡眠、唤醒之后可能有其他进程已经请求过所需要的块,因此需要最后一次搜索散列表,如果在散列表中找到了需要的块,则跳到get_hash_table中,直接从散列表中返回一个缓冲头指针,否则就设置缓冲头的字段,将缓冲头从LUR队列的头卸下、从散列表中卸下,重新插入到LUR队列尾和散列表的合适的位置。

fs/buffer.c
2、brelse
brelse用于释放正在使用的缓冲块,将b_count字段-1并且唤醒因为缓冲耗尽而进入睡眠的进程。

fs/buffer.c
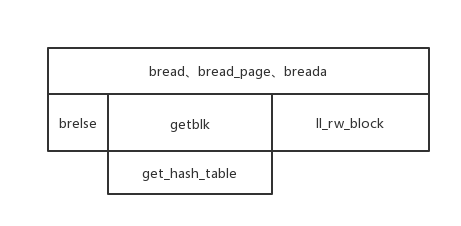
3、bread系列函数
bread系列共有bread、bread_page、breada三个函数。
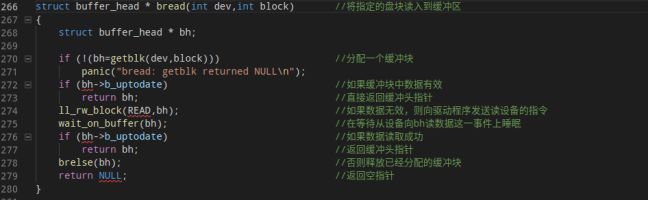
fs/buffer.c
bread函数用于将指定盘块读入到缓冲块中。首先调用getblk从缓冲区分配一个缓冲块,如果缓冲块中的数据有效则直接返回缓冲头指针,否则向驱动发送读指令,同时进程进入睡眠。如果读取数据成功则b_uptodate=1,返回bh。否则释放分配到的缓冲块,返回空指针。

bread执行逻辑
bread_page一次从块设备读入4KB的内容,主要是缺页异常处理需要用到这个函数。输入参数为address:缺页地址,dev:逻辑设备号,b[4]:四个连续的盘块号。主要过程与bread类似不再解读。
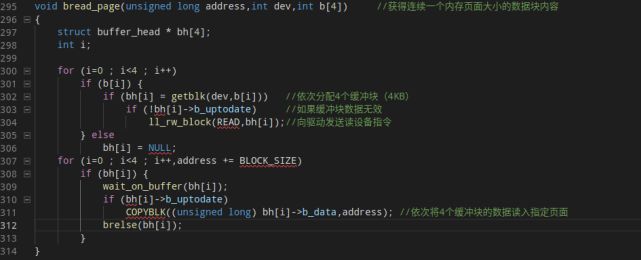
fs/buffer.c
breada参数是可变的,它读取并返回一个指定的块(dev,first),同时预读取若干个其他块,这些块由可变参量指定。这里需要注意的是,进程只在驱动读取(dev,first)的时候睡眠,驱动进行预读取的时候不进行睡眠。而且可以看到预读取块的引用数在执行完ll_rw_block就会-1,与getblk中的+1相对应,表示没有任何一个进程正在使用这些预读取块,但是预读取步骤加快了下次getblk的速度,因为这已经把下次可能需要的块读到了缓冲区。
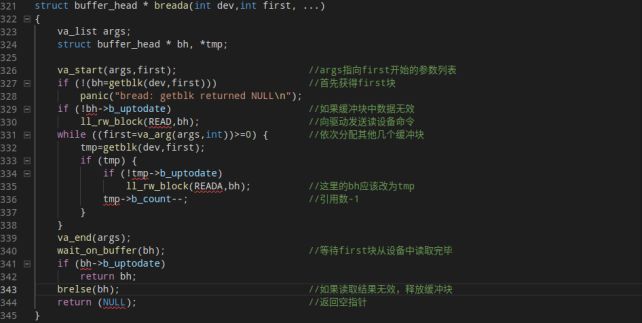
fs/buffer.c
四、主要函数之间的关系
getblk是文件系统的核心,任何的设备与内存的交互都离不开getblk分配缓冲块,理解了缓冲区机制再去看文件系统就会很轻松了。

- End -

看雪ID:极目楚天舒
https://bbs.pediy.com/user-741085.htm
本文由看雪论坛 极目楚天舒 原创
转载请注明来自看雪社区

热门图书推荐:
戳 立即购买!
立即购买! 
征题正在火热进行中!
(晋级赛Q1即将于3月10日开启,敬请期待!)
热门文章阅读
1、逆向分析LOL网吧特权原理,全英雄+全皮肤400余种!
2、尝试着实现了一个 ART Hook
3、使用模拟器进行x64驱动的Safengine脱壳+导入表修复
4、FPS网络游戏自动瞄准漏洞分析以及实现
热门课程推荐



公众号ID:ikanxue
官方微博:看雪安全
商务合作:wsc@kanxue.com
↙ 点击下方“阅读原文”转载地址:https://blog.csdn.net/weixin_33001305/article/details/112102279 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
