本文共 5746 字,大约阅读时间需要 19 分钟。
最近因为疫情的原因,偷了好长时间的懒,现在终于开始继续看Flink 的SQL 了
————————————————
电脑上的Flink 项目早就升级到了 1.10了,最近还在看官网新的文档,趁着周末,体验一下新版本的SQL API(踩一下坑)。
直接从之前的 云邪大佬的Flink 的 SQL 样例开始(pom 已经提前整理好了)。
简单回忆一下内容,就是从kafka 接收 用户行为,根据时间分组,求PV 和UV ,然后输出到 mysql 中。
先看下加的 依赖:
org.apache.flinkgroupId> flink-tableartifactId> ${flink.version}version> pomtype>dependency> org.apache.flinkgroupId> flink-table-api-java-bridge_2.11artifactId> ${flink.version}version>dependency> org.apache.flinkgroupId> flink-table-api-scala-bridge_2.11artifactId> ${flink.version}version>dependency> org.apache.flinkgroupId> flink-table-commonartifactId> ${flink.version}version>dependency> org.apache.flinkgroupId> flink-table-api-javaartifactId> ${flink.version}version>dependency> org.apache.flinkgroupId> flink-table-api-scala_${scala.binary.version}artifactId> ${flink.version}version>dependency> org.apache.flinkgroupId> flink-table-planner-blink_2.11artifactId> ${flink.version}version>dependency> org.apache.flinkgroupId> flink-table-planner_2.11artifactId> ${flink.version}version>dependency> org.apache.flinkgroupId> flink-jdbc_2.11artifactId> ${flink.version}version>dependency> org.apache.flinkgroupId> flink-csvartifactId> ${flink.version}version>dependency>
table 相关的有这些,注意几个新的依赖,如:flink-jdbc_2.11-1.10.0.jar
看下对应的sql文件:
--sourceTableCREATE TABLE user_log ( user_id VARCHAR, item_id VARCHAR, category_id VARCHAR, behavior VARCHAR, ts TIMESTAMP(3)) WITH ( 'connector.type' = 'kafka', 'connector.version' = 'universal', 'connector.topic' = 'user_behavior', 'connector.startup-mode' = 'earliest-offset', 'connector.properties.0.key' = 'zookeeper.connect', 'connector.properties.0.value' = 'venn:2181', 'connector.properties.1.key' = 'bootstrap.servers', 'connector.properties.1.value' = 'venn:9092', 'update-mode' = 'append', 'format.type' = 'json', 'format.derive-schema' = 'true');--sinkTableCREATE TABLE pvuv_sink ( dt VARCHAR, pv BIGINT, uv BIGINT) WITH ( 'connector.type' = 'jdbc', 'connector.url' = 'jdbc:mysql://venn:3306/venn', 'connector.table' = 'pvuv_sink', 'connector.username' = 'root', 'connector.password' = '123456', 'connector.write.flush.max-rows' = '1');--insertINSERT INTO pvuv_sink(dt, pv, uv)SELECT DATE_FORMAT(ts, 'yyyy-MM-dd HH:00') dt, COUNT(*) AS pv, COUNT(DISTINCT user_id) AS uvFROM user_logGROUP BY DATE_FORMAT(ts, 'yyyy-MM-dd HH:00');
执行
遇到的第一个问题就是:"Type TIMESTAMP(6) of table field 'ts' does not match with the physical type TIMESTAMP(3) of the 'ts' field of the TableSource return type"
看起来 TIMESTAMP 默认的是 TIMESTAMP(6) ,与 source 中的 TIMESTAMP("ts": "2017-11-26T01:00:01Z")不匹配,直接将 ts 的数据类型改为 :TIMESTAMP(3),搞定。
好像没有其他坑了,直接可以执行,数据也输出到myql 中了
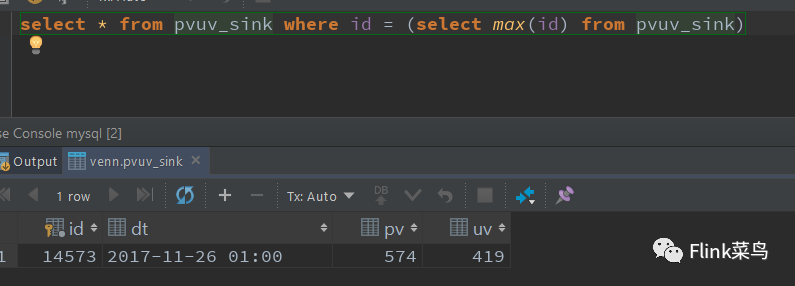
之后,从sql 的 connector 开始,先看了下 kafak的,Flink 1.10 SQL 中,kafka 只支持 csv、json 和 avro 三种类型。(试了下 json 和 csv)
两个sql程序,包含读写 json、csn。
直接将上面的table sink 的sql 修改成写kafak:
--sinkTableCREATE TABLE user_log_sink ( dt VARCHAR, pv BIGINT, uv BIGINT) WITH ( 'connector.type' = 'kafka', 'connector.version' = 'universal', 'connector.topic' = 'user_behavior_sink', 'connector.properties.zookeeper.connect' = 'venn:2181', 'connector.properties.bootstrap.servers' = 'venn:9092', 'update-mode' = 'append', 'format.type' = 'json');
然而,并不能执行。
报了如下的错:
AppendStreamTableSink requires that Table has only insert changes.
WTF,上面的 'update-mode' 明明写的是 'append'
然后,我就开始了一段,并没有什么鸟用的操作:看官网文档、修改sql 的配置。。
---------------此处花了不少时间-----------------
直到最后,突发奇想,直接将source 的内容输出呢,不做任何转换:
--insertINSERT INTO user_log_sink(dt, pv, uv)SELECT user_id, item_id, category_id, behavior, tsFROM user_log;
sink 部分也随之修改:
--sinkTableCREATE TABLE user_log_sink ( user_id VARCHAR, item_id VARCHAR, category_id VARCHAR, behavior VARCHAR, ts TIMESTAMP(3)) WITH ( 'connector.type' = 'kafka', 'connector.version' = 'universal', 'connector.topic' = 'user_behavior_sink_1', 'connector.properties.zookeeper.connect' = 'venn:2181', 'connector.properties.bootstrap.servers' = 'venn:9092', 'update-mode' = 'append', 'format.type' = 'json');
就好了,好了,了。。
哎,等官网文档,看完了,应该就知道是为什么了(注:等知道后,来加上)
然后就开始了最后一个坑。
在写csv 的时候,遇到了最后一个坑,之前的版本里,“flink-shaded-jackso”我一直用的 “2.7.9-3.0”,但是里面并没有 CsvSchame,所以又有了这个报错:
Caused by: java.lang.ClassNotFoundException: org.apache.flink.shaded.jackson2.com.fasterxml.jackson.dataformat.csv.CsvSchema$Builder
将 flink-shaded-jackso 的版本换成了flink 代码里的版本 “2.9.8-7.0”
基本上,就顺畅的完成了kafka connector 读写 json 和 csv 了。
最后贴上完整的SQL:
--sourceTableCREATE TABLE user_log( user_id VARCHAR, item_id VARCHAR, category_id VARCHAR, behavior VARCHAR, ts TIMESTAMP(3)) WITH ( 'connector.type' = 'kafka', 'connector.version' = 'universal', 'connector.topic' = 'user_behavior', 'connector.properties.zookeeper.connect' = 'venn:2181', 'connector.properties.bootstrap.servers' = 'venn:9092', 'connector.startup-mode' = 'earliest-offset', 'format.type' = 'json'# 'format.type' = 'csv');--sinkTableCREATE TABLE user_log_sink ( user_id VARCHAR, item_id VARCHAR, category_id VARCHAR, behavior VARCHAR, ts TIMESTAMP(3)) WITH ( 'connector.type' = 'kafka', 'connector.version' = 'universal', 'connector.topic' = 'user_behavior_sink', 'connector.properties.zookeeper.connect' = 'venn:2181', 'connector.properties.bootstrap.servers' = 'venn:9092', 'update-mode' = 'append',# 'format.type' = 'json' 'format.type' = 'csv');--insertINSERT INTO user_log_sink(dt, pv, uv)SELECT user_id, item_id, category_id, behavior, tsFROM user_log;
相关的SQL文件上传到github 上了: flink-rookic ,pom.xml 内的依赖也有更新。
好久没写了,最近会简单尝试一遍SQL 的 kafak/mysql/hbase/es/file/hdfs 等 connector,然后再尝试 SQL 的其他内容
转载地址:https://blog.csdn.net/weixin_32541663/article/details/112154158 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
