
概述
传统的方法是使用Java MapReduce程序结构化,半结构化和非结构化数据。
针对MapReduce的脚本的方式,使用Pig来处理结构化和半结构化数据。 Hive查询语言(HiveQL或HQL)采用Hive为MapReduce的处理结构化数据。 Hive是Hadoop家族中一款数据仓库产品,Hive最大的特点就是提供了类SQL的语法,封装了底层的MapReduce过程,让有SQL基础的业务人员,也可以直接利用Hadoop进行大数据的操作。 就是这一个点,解决了原数据分析人员对于大数据分析的瓶颈。 Hive与传统关系数据库比较有如下几个特点: 侧重于分析,而非实时在线交易; 无事务机制; 不像关系数据库那样可以随机进行 insert或update; 通过Hadoop的map/reduce进行分布式处理,传统数据库则没有; 传统关系数据库只能拓展最多20个服务器,而Hive可以拓展到上百个服务器。在Hive中可使用Join语法,这是一般NoSQL的弱项,因为根据CAP定律,Join阻碍了分区,但是在Hive中Join的实现有其特殊性:
Hive的Join策略有三种,各有利弊: Shuffle Join洗牌式:这是一种最慢的Join策略,用Map/reduce将Join的key洗牌,然后在reduce时再连接,适合任何大小的数据集。 Broadcast Join广播式:将所有服务器上的表数据加载到内存,Mapper通过一个大表扫描然后进行连接,优点很快,但是内存必须能容纳一个表的所有数据。 Sort- Merge- Bucket Join:对于任何数据大小都很快,缺点是数据需要首先排序或Bucket。Bucket 只是hive 的一种hash partition 的实现,如下图,将表数据预先分区,排桶bucket,倾斜skew: Hive 不是 一个关系数据库 一个设计用于联机事务处理(OLTP) 实时查询和行级更新的语言 Hiver特点 它存储架构在一个数据库中并处理数据到HDFS。 它是专为OLAP设计。 它提供SQL类型语言查询叫HiveQL或HQL。 它是熟知,快速,可扩展和可扩展的。Hive是什么
Hive是基于Hadoop的数据仓库解决方案。由于Hadoop本身在数据存储和计算方面有很好的可扩展性和高容错性,因此使用Hive构建的数据仓库也秉承了这些特性。这是来自官方的解释。简单来说,Hive就是在Hadoop上架了一层SQL接口,可以将SQL翻译成MapReduce去Hadoop上执行,这样就使得数据开发和分析人员很方便的使用SQL来完成海量数据的统计和分析,而不必使用编程语言开发MapReduce那么麻烦。
Hive结构图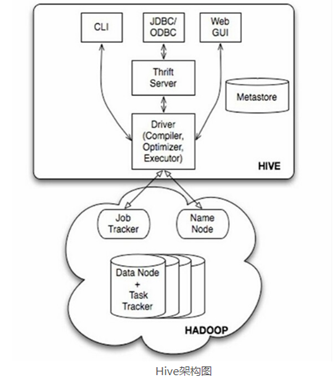
如图中所示,Hive通过给用户提供的一系列交互接口,接收到用户的指令(SQL),使用自己的Driver,结合元数据(MetaStore),将这些指令翻译成MapReduce,提交到Hadoop中执行,最后,将执行返回的结果输出到用户交互接口。在使用过程中,至需要将Hive看做是一个数据库就行,本身Hive也具备了数据库的很多特性和功能。
Hive擅长什么
Hive可以使用HQL(Hive SQL)很方便的完成对海量数据的统计汇总,即席查询和分析,除了很多内置的函数,还支持开发人员使用其他编程语言和脚本语言来自定义函数。但是,由于Hadoop本身是一个批处理,高延迟的计算框架,Hive使用Hadoop作为执行引擎,自然也就有了批处理,高延迟的特点,在数据量很小的时候,Hive执行也需要消耗较长时间来完成,这时候,就显示不出它与Oracle,Mysql等传统数据库的优势。此外,Hive对事物的支持不够好,原因是HDFS本身就设计为一次写入,多次读取的分布式存储系统,因此,不能使用Hive来完成诸如DELETE、UPDATE等在线事务处理的需求。因此,Hive擅长的是非实时的、离线的、对响应及时性要求不高的海量数据批量计算,即席查询,统计分析。
Hive架构
下面的组件图描绘了Hive的结构:
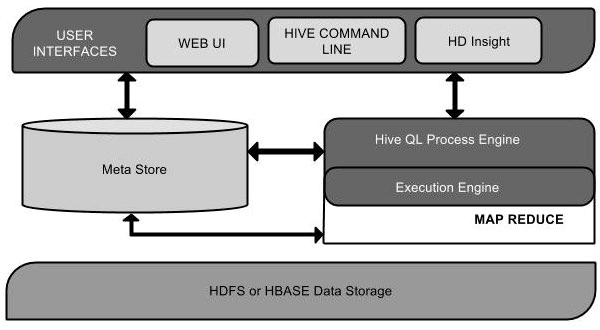
用户接口/界面 Hive是一个数据仓库基础工具软件,可以创建用户和HDFS之间互动。用户界面,Hive支持是Hive的Web UI,Hive命令行,HiveHD洞察(在Windows服务器)。
元存储 Hive选择各自的数据库服务器,用以储存表,数据库,列模式或元数据表,它们的数据类型和HDFS映射。 HiveQL处理引擎 HiveQL类似于SQL的查询上Metastore模式信息。这是传统的方式进行MapReduce程序的替代品之一。相反,使用Java编写的MapReduce程序,可以编写为 MapReduce工作,并处理它的查询。 执行引擎 HiveQL处理引擎和MapReduce的结合部分是由Hive执行引擎。执行引擎处理查询并产生结果和MapReduce的结果一样。它采用MapReduce方法。 HDFS 或 HBASE Hadoop的分布式文件系统或者HBASE数据存储技术是用于将数据存储到文件系统。Hive工作原理
下图描述了Hive 和Hadoop之间的工作流程
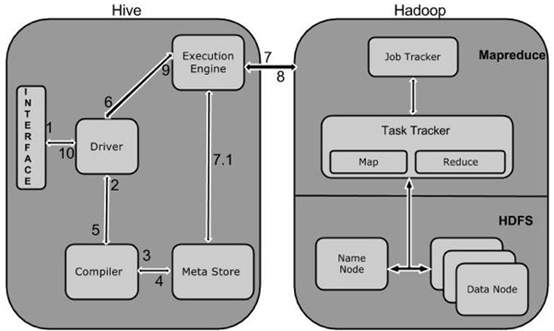
下表定义Hive和Hadoop框架的交互方式:
1 Execute Query Hive接口,如命令行或Web UI发送查询驱动程序(任何数据库驱动程序,如JDBC,ODBC等)来执行。 2 Get Plan 在驱动程序帮助下查询编译器,分析查询检查语法和查询计划或查询的要求。 3 Get Metadata 编译器发送元数据请求到Metastore(任何数据库)。 4 Send Metadata Metastore发送元数据,以编译器的响应。 5 Send Plan 编译器检查要求,并重新发送计划给驱动程序。到此为止,查询解析和编译完成。 6 Execute Plan 驱动程序发送的执行计划到执行引擎。 7 Execute Job 在内部,执行作业的过程是一个MapReduce工作。执行引擎发送作业给JobTracker,在名称节点并把它分配作业到TaskTracker,这是在数据节 点。在这里,查询执行MapReduce工作。 7.1Metadata Ops 与此同时,在执行时,执行引擎可以通过Metastore执行元数据操作。 8 Fetch Result 执行引擎接收来自数据节点的结果。 9 Send Results 执行引擎发送这些结果值给驱动程序。 10 Send Results 驱动程序将结果发送给Hive接口。