1、cookie和session
cookie可以单独工作 cookie也可以和session配合来用 每一个浏览器都会有一个cookie:{} 浏览器第一次访问服务器的时候cookie是空的 服务器需要让客户端保存一些数据cookie {"sessionID":"随机字符串"},当下次请求的时候就会带着一些你保存的数据 django_session表里的每一条记录就是一个个用户,类似一个大的字典 session_key:存的是sessionID对应的值 session_data:{"":"","":"",...}存的是一组组键值对 等再次访问的时候就会带着sessionID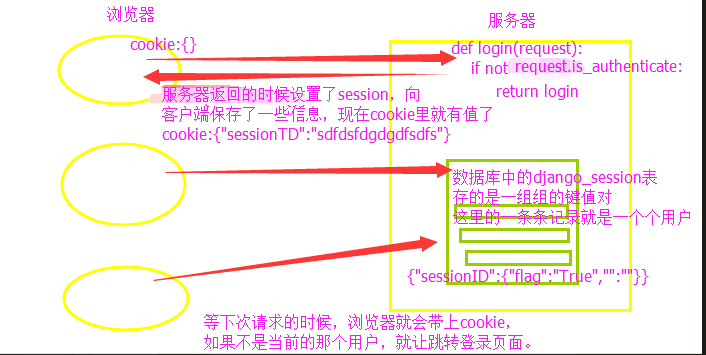 2、登录和注册 - 登录(ajax) - 涉及验证码的实现(可以吧获取的验证码存放在session中,以方便验证的时候判断。每次访问的时候浏览器都会带着你存放在里面的值,用的时候取它就行了) - 登录成功之后设置session,以后每次请求进来的时候浏览器都会带着cookie,就知道是谁进来了。保存了状态。(用auth模块)
2、登录和注册 - 登录(ajax) - 涉及验证码的实现(可以吧获取的验证码存放在session中,以方便验证的时候判断。每次访问的时候浏览器都会带着你存放在里面的值,用的时候取它就行了) - 登录成功之后设置session,以后每次请求进来的时候浏览器都会带着cookie,就知道是谁进来了。保存了状态。(用auth模块) user=auth.authenticate(username=username,password=password)#验证用户名和密码if user:ret["flag"] = Trueauth.login(request,user) #session request.session["flag"]=True #如果认证成功,就让登录,这个login里面包括了session操作和cookie...
如果是当前的用户就做什么操作,如果不是当前的用户就不让他进
- 注册(ajax+Form) - 涉及头像的实现 具体见上篇博客3、系统主页1、设计系统主页(系统主页是用户不管登录不登录都是可以看到的,所以没必要进行验证) - 导航条: - 需要注意的是: - 如果用户是登录进来的,就让显示登录状态;如果用户还没有登录,就在导航条上显示登录,注册(如图)登录状态

没有登录状态
所以具体我们还得判断一下
- 注销
- 修改密码 像是注销,登录,修改密码我们都可以借助auth模块来实现- 具体显示内容可以分三大块
- 左侧菜单系列 - 显示文章系列 - 文章标题: - 作者头像: - 是谁发布的,发布时间,等... - 文章不可能只有一篇,会有好多篇文章,这是还得加上分页 - 右侧可以放一写其他信息2、下面是具体流程,需要注意的知识点
==================================== 当做左侧的时候需要多加两张表 - 多加了一个网站分类表和网站文章分类表(可参考博客园cnblogs.com的系统主页) - 一个网站分类里面又可以对文章分好多类 (建立了一对多的关系) - 文章分类里面又有好多相关的具体文章(建立了一对多的关系) 注意关联字段要写在多的一方class SiteCategory(models.Model): '''网站分类表''' name = models.CharField(max_length=32,verbose_name="分类名") class Meta: verbose_name_plural="网站分类表" def __str__(self): return self.nameclass SiteArticleCategory(models.Model): '''网站文章分类表''' name = models.CharField(max_length=32,verbose_name="分类名") sitecategory = models.ForeignKey(to="SiteCategory",verbose_name="所属网站") class Meta: verbose_name_plural = "网站文章分类表" def __str__(self): return self.name
====================================
- 建立好关系之后就可以实现左侧菜单了 - 左侧菜单需要注意的是你点击菜单的时候的跳转路径,当然有人会想到用模板继承的方式,这种方式是能实现,但是还有一种更机智的办法。我们可以参考博客园的跳转路径,还是继续走index视图, 但是我们得把路径匹配一下,如图url(r'^index/', views.index),url(r'^$', views.index), #根目录下也让走indexurl(r'^cate/(?P.*)/', views.index) #有名分组
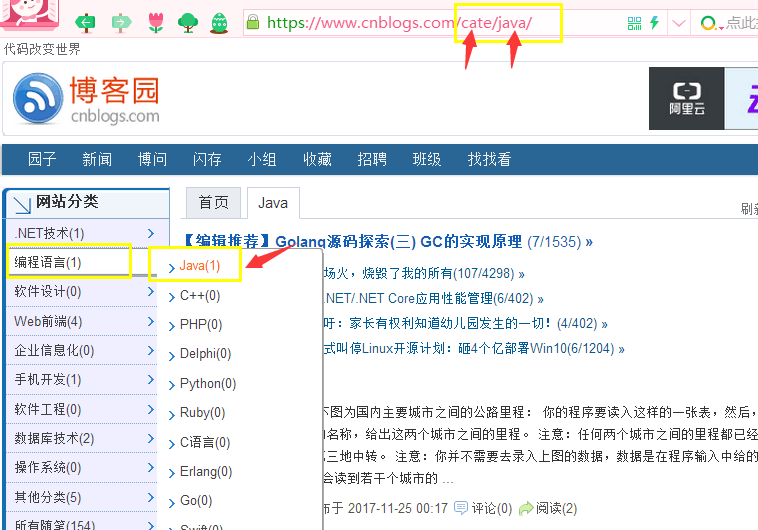
print("-----------",kwargs) #接收到的是一个字典kwargs = kwargs.get("site_article_category")print("=======",kwargs) #得到的是site_article_category对应的值if kwargs: print("xxxxxxxxxxxxxx") article_obj = models.Article.objects.filter(site_article_category__name=kwargs) # article_obj打印的是一个对象 ,如果点击的是左侧的,就让现实左侧的相关文章else: article_obj = models.Article.objects.all()#如果没有点击左侧就查询所有的文章 - 点击头像跳转
注意:
【1】:跳转路径【2】:图片路径有两种方式:
1、我们也可以指定/media/{ {article.user.avatar}}2、直接{ {article.user.avatar.url}} django会自动找到图片对应的位置 - 分页
注意:
【1】:一定要把跳转路径对应好了,不然就混乱了。4、个人主页
设计个人主页的时候,可以仿照博客园的页面设计,当然每个人的个人主页都是不一样的,不过这个也挺简单的,下面会说到 我设计的个人主页:还是分了三大块 - 导航条: - 左侧: - 个人信息 - 我的标签 - 随笔分类 - 日期归档 - 右侧:显示文章 - 涉及到的知识点 1、模板继承 当点击文章标题的时候用到,因为当点击文章标题的时候,就要显示具体的文章内容 这时候需要再走一个路由,专门处理具体的文章内容的操作标题#}
url:这里用到的是路由分发。。。
url(r'^(?P.*)/articles/(?P \d+)/$', views.article_detail),
注意:在admin录入文章内容数据的时候,如果你直接吧随便找的文章粘贴过来,这样粘贴过来的是没有样式的,我们要把html源码粘贴进去
当吧源码粘贴进去的时候会全部都是标签,而不是文章内容,这是由于做了安全机制了,吧标签当成是字符串了,我们得告诉浏览器。 我的代码是安全的,这样才会显示中文。 解决办法:safe <p>{ { article_obj.article_detail.content|safe }}</p> 2、ORM查询 1、查询操作# 查询当前用户下的所有文章current_user = models.UserInfo.objects.filter(username=username).first()models.Article.objects.filter(user=current_user)#查看当前用户的个人博客,(个人博客和用户是一对一的关系,一个用户有一个个人博客)current_user.blog#查询当前用户下的而所有的分类以及文章数models.Classfication.objects.filter(blog=current_blog).annotate(count=Count("article__title")).values_list("title","count")#查询当前用户下的而所有的标签以及文章数models.Tag.objects.all().filter(blog=current_blog).annotate(count=Count("article__id")).values_list("name","count")#查询当前用户下的而所有的年月日期以及文章数models.Article.objects.all().filter(user=current_user).extra(select={ "filter_create_date":"strftime('%%Y/%%m',create_time)"}).values_list("filter_create_date").annotate(Count("title")) 涉及:
基于对象查询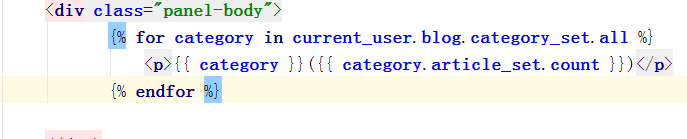
基于双下划线,分组函数 annotate
理解分组:
查日期的时候:extra过滤
3、左侧的标签分类和随笔分类,日期归档,当点击的时候跳转,参照博客园的跳转路径,具体操作和系统主页的类似,不需要模板继承,也不需要跳转到其他的地方,让还在当前页面上跳转
我们可以吧跳转路径匹配一下 url(r'^(?P<username>.*)/(?P<condition>category|tag|data)/(?P<para>.*)/$', views.homesite),在HTML中:
日期归档,随笔分类标签分类
4、每个人都有一套默认的皮肤
1、在static下创建一个存皮肤的文件夹user_home_style a.css 设置a样式 b.css 设置b样式 .... 2、吧homesite里面的你不想用的样式删除了 3、在数据库里吧theme主题修改一下,存成 a.css b.css .... 4、导入:在link的时候{ {current_user.blog.theme}}#这样就每个用户对应的样式就找到了
5、个人主页的文章详细以及点赞和评论
涉及到的知识点:
- ajax - F查询点赞思路:用ajax实现:
发送数据,要对那篇文章点赞,需要发一个article_id 还需要知道当前用户的id,这个我们可以不用ajax发了,直接在后端查出来,用request.user.nid 在后端接收数据 先创建赞示例 models.Article_poll.objects.create(user_id=user_id,article_id=article_id) 然后点赞数+1 models.Article.objects.filter(id=article_id).update(poll_count=F("poll_count")+1) 然后返回给前端,在前端渲染 渲染的时候 1、吧页面上的数字加1,并且显示点赞成功 2、如果已经点过赞了,提示不能重复点赞, 3、如果是用户登录了可以点赞,没有登录提示请先登录,登录做个超链接,链接到login页面6、url:路径斜杠问题 当加/的时候,是从根目录拼接 当没有加/的时候,是从当前路径拼接7、 查看当前用户current_user = models.UserInfo.objects.filter(username=username).first()print("current_user==========",current_user,type(current_user)) print("request.user.username======",request.user.username,type(request.user.username))打印结果 current_user========== haiyan #对象request.user.username====== haiyan #字符串,,可以在页面中渲染
