本文共 4740 字,大约阅读时间需要 15 分钟。
中文分词
对于NLP(自然语言处理)来说,分词是一步重要的工作,市面上也有各种分词库,11款开放中文分词系统比较。
1.基于词典:基于字典、词库匹配的分词方法;(字符串匹配、机械分词法)
2.基于统计:基于词频度统计的分词方法; 3.基于规则:基于知识理解的分词方法。第一类方法应用词典匹配、汉语词法或其它汉语语言知识进行分词,如:最大匹配法、最小分词方法等。这类方法简单、分词效率较高,但汉语语言现象复杂丰富,词典的完备性、规则的一致性等问题使其难以适应开放的大规模文本的分词处理。
第二类基于统计的分词方法则基于字和词的统计信息,如把相邻字间的信息、词频及相应的共现信息等应用于分词,由于这些信息是通过调查真实语料而取得的,因而基于统计的分词方法具有较好的实用性。 jieba分词,完全开源,有集成的python库,简单易用。 jieba分词是基于前缀词典实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图 (DAG),动态规划查找最大概率路径, 找出基于词频的最大切分组合安装jieba
在安装有python3 和 pip 的机子上,安装jieba库很简单,使用pip即可:
pip3 install jieba
jieba分词特性
支持三种分词模式:
精确模式,试图将句子最精确地切开,适合文本分析;
全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义; 搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。主要功能
分词 jieba.cut : 方法接受三个输入参数: 需要分词的字符串;cut_all 参数用来控制是否采用全模式;HMM 参数用来控制是否使用 HMM 模型 jieba.cut_for_search : 方法接受两个参数:需要分词的字符串;是否使用 HMM 模型。该方法适合用于搜索引擎构建倒排索引的分词,粒度比较细 待分词的字符串可以是 unicode 或 UTF-8 字符串、GBK 字符串。注意:不建议直接输入 GBK 字符串,可能无法预料地错误解码成 UTF-8 jieba.cut 以及 jieba.cut_for_search 返回的结构都是一个可迭代的 generator,可以使用 for 循环来获得分词后得到的每一个词语(unicode),或者用jieba.lcut 以及jieba.lcut_for_search 直接返回 list jieba.Tokenizer(dictionary=DEFAULT_DICT) : 新建自定义分词器,可用于同时使用不同词典。jieba.dt 为默认分词器,所有全局分词相关函数都是该分词器的映射。# 官方例程 # encoding=utf-8import jieba seg_list = jieba.cut("我来到北京清华大学", cut_all=True)print("Full Mode: " + "/ ".join(seg_list)) # 全模式 seg_list = jieba.cut("我来到北京清华大学", cut_all=False)print("Default Mode: " + "/ ".join(seg_list)) # 精确模式 seg_list = jieba.cut("他来到了网易杭研大厦") # 默认是精确模式print(", ".join(seg_list)) seg_list = jieba.cut_for_search("小明硕士毕业于中国科学院计算所,后在日本京都大学深造") # 搜索引擎模式print(", ".join(seg_list))【全模式】: 我/ 来到/ 北京/ 清华/ 清华大学/ 华大/ 大学【精确模式】: 我/ 来到/ 北京/ 清华大学【新词识别】:他, 来到, 了, 网易, 杭研, 大厦 (此处,“杭研”并没有在词典中,但是也被Viterbi算法识别出来了)【搜索引擎模式】: 小明, 硕士, 毕业, 于, 中国, 科学, 学院, 科学院, 中国科学院, 计算, 计算所, 后, 在, 日本, 京都, 大学, 日本京都大学, 深造 关键词提取
基于 TF-IDF(term frequency–inverse document frequency) 算法的关键词抽取
import jieba.analysejieba.analyse.extract_tags(sentence, topK=20, withWeight=False, allowPOS=())sentence :为待提取的文本topK: 为返回几个 TF/IDF 权重最大的关键词,默认值为 20withWeight : 为是否一并返回关键词权重值,默认值为 FalseallowPOS : 仅包括指定词性的词,默认值为空,即不筛选# 基于TF-IDF算法的关键词抽取 import jiebaimport jieba.analyse sentence = '全国港澳研究会会长徐泽在会上发言指出,学习系列重要讲话要深刻领会 主席关于香港回归后的宪制基础和宪制秩序的论述,这是过去20年特别是中共十八大以来"一国两制"在香港实践取得成功的根本经验。首先,要在夯实 香港的宪制基础、巩固香港的宪制秩序上着力。只有牢牢确立起"一国两制"的宪制秩序,才能保证"一国两制"实践不走样 、不变形。其次,要在完善基本法实施的制度和机制上用功。中央直接行使的权力和特区高度自治权的结合是特区宪制秩 序不可或缺的两个方面,同时必须切实建立以行政长官为核心的行政主导体制。第三,要切实加强香港社会特别是针对公 职人员和青少年的宪法、基本法宣传,牢固树立"一国"意识,坚守"一国"原则。第四,要努力在全社会形成聚焦发展、抵 制泛政治化的氛围和势能,全面准确理解和落实基本法有关经济事务的规定,使香港继续在国家发展中发挥独特作用并由 此让最广大民众获得更实在的利益。' keywords = jieba.analyse.extract_tags(sentence, topK=20, withWeight=True, allowPOS=('n','nr','ns')) # print(type(keywords))# for item in keywords: print(item[0],item[1]) 运行结果:
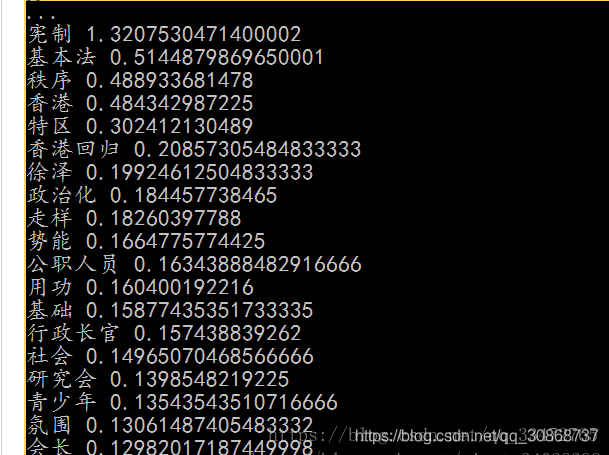
基于 TextRank 算法的关键词抽取
jieba.analyse.textrank(sentence, topK=20, withWeight=False, allowPOS=(‘ns’, ‘n’, ‘vn’, ‘v’)) 直接使用,接口相同,注意默认过滤词性。
jieba.analyse.TextRank() 新建自定义 TextRank 实例 基本思想:将待抽取关键词的文本进行分词
以固定窗口大小(默认为5,通过span属性调整),词之间的共现关系,构建图 计算图中节点的PageRank,注意是无向带权图# 基于TextRank算法的关键词抽取 keywords = jieba.analyse.extract_tags(sentence, topK=20, withWeight=True, allowPOS=('n','nr','ns')) # type(keywords)# for item in keywords: print(item[0],item[1]) 运行结果:
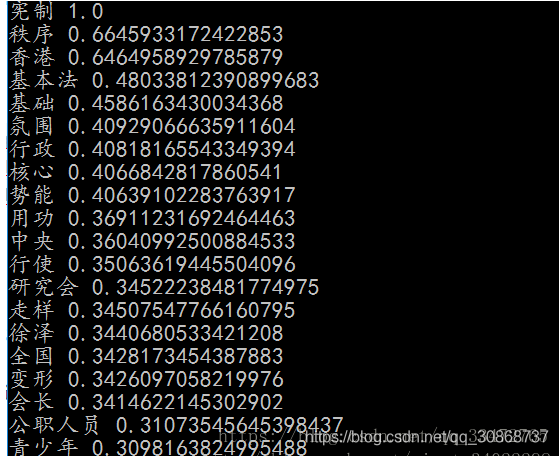
词性标注
jieba.posseg.POSTokenizer(tokenizer=None) 新建自定义分词器,tokenizer 参数可指定内部使用的 jieba.Tokenizer 分词器。jieba.posseg.dt 为默认词性标注分词器。
标注句子分词后每个词的词性,采用和 ictclas 兼容的标记法。# 官方例程import jieba.posseg as pseg words = pseg.cut("我爱北京天安门")# words类别为:generator for word, flag in words: print('%s %s' % (word, flag)) 运行结果:
我 r
爱 v 北京 ns 天安门 ns词性对照表
名词 (1个一类,7个二类,5个三类)
名词分为以下子类: n 名词 nr 人名 nr1 汉语姓氏 nr2 汉语名字 nrj 日语人名 nrf 音译人名 ns 地名 nsf 音译地名 nt 机构团体名 nz 其它专名 nl 名词性惯用语 ng 名词性语素 时间词(1个一类,1个二类) t 时间词 tg 时间词性语素 处所词(1个一类) s 处所词 方位词(1个一类) f 方位词 动词(1个一类,9个二类) v 动词 vd 副动词 vn 名动词 vshi 动词“是” vyou 动词“有” vf 趋向动词 vx 形式动词 vi 不及物动词(内动词) vl 动词性惯用语 vg 动词性语素 形容词(1个一类,4个二类) a 形容词 ad 副形词 an 名形词 ag 形容词性语素 al 形容词性惯用语 区别词(1个一类,2个二类) b 区别词 bl 区别词性惯用语 状态词(1个一类) z 状态词 代词(1个一类,4个二类,6个三类) r 代词 rr 人称代词 rz 指示代词 rzt 时间指示代词 rzs 处所指示代词 rzv 谓词性指示代词 ry 疑问代词 ryt 时间疑问代词 rys 处所疑问代词 ryv 谓词性疑问代词 rg 代词性语素 数词(1个一类,1个二类) m 数词 mq 数量词 量词(1个一类,2个二类) q 量词 qv 动量词 qt 时量词 副词(1个一类) d 副词 介词(1个一类,2个二类) p 介词 pba 介词“把” pbei 介词“被” 连词(1个一类,1个二类) c 连词 cc 并列连词 助词(1个一类,15个二类) u 助词 uzhe 着 ule 了 喽 uguo 过 ude1 的 底 ude2 地 ude3 得 usuo 所 udeng 等 等等 云云 uyy 一样 一般 似的 般 udh 的话 uls 来讲 来说 而言 说来 uzhi 之 ulian 连 (“连小学生都会”) 叹词(1个一类) e 叹词 语气词(1个一类) y 语气词(delete yg) 拟声词(1个一类) o 拟声词 前缀(1个一类) h 前缀 后缀(1个一类) k 后缀 字符串(1个一类,2个二类) x 字符串 xx 非语素字 xu 网址URL 标点符号(1个一类,16个二类) w 标点符号 wkz 左括号,全角:( 〔 [ { 《 【 〖 〈 半角:( [ { < wky 右括号,全角:) 〕 ] } 》 】 〗 〉 半角: ) ] { > wyz 左引号,全角:“ ‘ 『 wyy 右引号,全角:” ’ 』 wj 句号,全角:。 ww 问号,全角:? 半角:? wt 叹号,全角:! 半角:! wd 逗号,全角:, 半角:, wf 分号,全角:; 半角: ; wn 顿号,全角:、 wm 冒号,全角:: 半角: : ws 省略号,全角:…… … wp 破折号,全角:—— -- ——- 半角:— —- wb 百分号千分号,全角:% ‰ 半角:% wh 单位符号,全角:¥ $ £ ° ℃ 半角:$转载地址:https://blog.csdn.net/qq_30868737/article/details/107792443 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
