介绍
Kafka是一个分布式的、可分区的、可复制的消息系统。它提供了普通消息系统的功能。但具有自己独特的设计。这个独特的设计是什么样的呢?
首先让我们看几个主要的消息系统术语:
- Kafka将消息以topic为单位进行归纳。
- 将向Kafka topic公布消息的程序成为producers.
- 将预订topics并消费消息的程序成为consumer.
- Kafka以集群的方式执行,能够由一个或多个服务组成,每一个服务叫做一个broker.
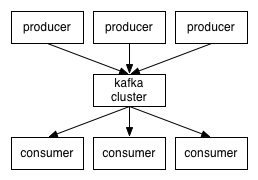
client和服务端通过TCP协议通信。 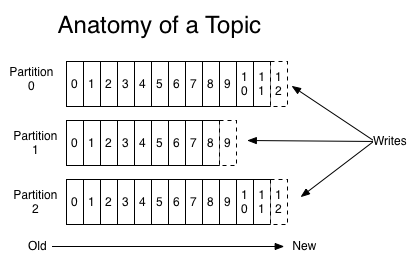
Kafka提供了Javaclient,而且对都提供了支持。
Topics 和Logs
先来看一下Kafka提供的一个抽象概念:topic.
一个topic是对一组消息的归纳。对每一个topic。Kafka 对它的日志进行了分区。例如以下图所看到的:
每一个分区都由一系列有序的、不可变的消息组成,这些消息被连续的追加到分区中。
分区中的每一个消息都有一个连续的序列号叫做offset,用来在分区中唯一的标识这个消息。
在一个可配置的时间段内。Kafka集群保留全部公布的消息,无论这些消息有没有被消费。比方,假设消息的保存策略被设置为2天,那么在一个消息被公布的两天时间内,它都是能够被消费的。之后它将被丢弃以释放空间。Kafka的性能是和数据量无关的常量级的,所以保留太多的数据并非问题。
实际上每一个consumer唯一须要维护的数据是消息在日志中的位置。也就是offset.这个offset有consumer来维护:普通情况下随着consumer不断的读取消息,这offset的值不断添加,但事实上consumer能够以随意的顺序读取消息。比方它能够将offset设置成为一个旧的值来重读之前的消息。
以上特点的结合,使Kafka consumers很的轻量级:它们能够在不正确集群和其它consumer造成影响的情况下读取消息。
你能够使用命令行来"tail"消息而不会对其它正在消费消息的consumer造成影响。
将日志分区能够达到下面目的:首先这使得每一个日志的数量不会太大,能够在单个服务上保存。另外每一个分区能够单独公布和消费。为并发操作topic提供了一种可能。
分布式
每一个分区在Kafka集群的若干服务中都有副本,这样这些持有副本的服务能够共同处理数据和请求,副本数量是能够配置的。副本使Kafka具备了容错能力。 每一个分区都由一个server作为“leader”,零或若干server作为“followers”,leader负责处理消息的读和写。followers则去复制leader.假设leader down了,followers中的一台则会自己主动成为leader。集群中的每一个服务都会同一时候扮演两个角色:作为它所持有的一部分分区的leader,同一时候作为其它分区的followers。这样集群就会据有较好的负载均衡。
Producers
Producer将消息公布到它指定的topic中,并负责决定公布到哪个分区。通常简单的由负载均衡机制随机选择分区,但也能够通过特定的分区函数选择分区。使用的很多其它的是另外一种。
Consumers
公布消息通常有两种模式:队列模式()和公布-订阅模式()。
队列模式中,consumers能够同一时候从服务端读取消息,每一个消息仅仅被当中一个consumer读到;公布-订阅模式中消息被广播到全部的consumer中。
Consumers能够增加一个consumer 组。共同竞争一个topic。topic中的消息将被分发到组中的一个成员中。同一组中的consumer能够在不同的程序中,也能够在不同的机器上。假设全部的consumer都在一个组中。这就成为了传统的队列模式,在各consumer中实现负载均衡。
假设全部的consumer都不在不同的组中,这就成为了公布-订阅模式。全部的消息都被分发到全部的consumer中。
更常见的是。每一个topic都有若干数量的consumer组,每一个组都是一个逻辑上的“订阅者”。为了容错和更好的稳定性,每一个组由若干consumer组成。这事实上就是一个公布-订阅模式,仅仅只是订阅者是个组而不是单个consumer。
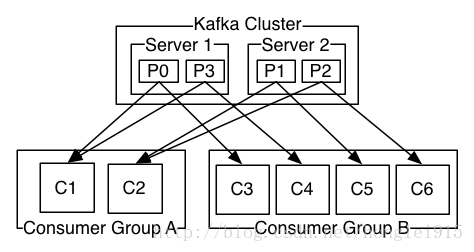
由两个机器组成的集群拥有4个分区 (P0-P3) 2个consumer组. A组有两个consumerB组有4个
相比传统的消息系统,Kafka能够非常好的保证有序性。
传统的队列在server上保存有序的消息,假设多个consumers同一时候从这个server消费消息,server就会以消息存储的顺序向consumer分发消息。尽管server按顺序公布消息。可是消息是被异步的分发到各consumer上。所以当消息到达时可能已经失去了原来的顺序,这意味着并发消费将导致顺序错乱。为了避免故障,这种消息系统通常使用“专用consumer”的概念,事实上就是仅仅同意一个消费者消费消息,当然这就意味着失去了并发性。
在这方面Kafka做的更好,通过分区的概念,Kafka能够在多个consumer组并发的情况下提供较好的有序性和负载均衡。将每一个分区分仅仅分发给一个consumer组。这样一个分区就仅仅被这个组的一个consumer消费,就能够顺序的消费这个分区的消息。由于有多个分区,依旧能够在多个consumer组之间进行负载均衡。注意consumer组的数量不能多于分区的数量。也就是有多少分区就同意多少并发消费。
Kafka仅仅能保证一个分区之内消息的有序性,在不同的分区之间是不能够的,这已经能够满足大部分应用的需求。
假设须要topic中订购的所有消息。然后,只需让这种topic只有一个分区,当然,它只有一个consumer集团消费它。
