(面试经典问题)HDFS下载文件(读)流程
发布日期:2023-01-18 09:09:18
浏览次数:124
分类:技术文章
本文共 472 字,大约阅读时间需要 1 分钟。
读流程详述
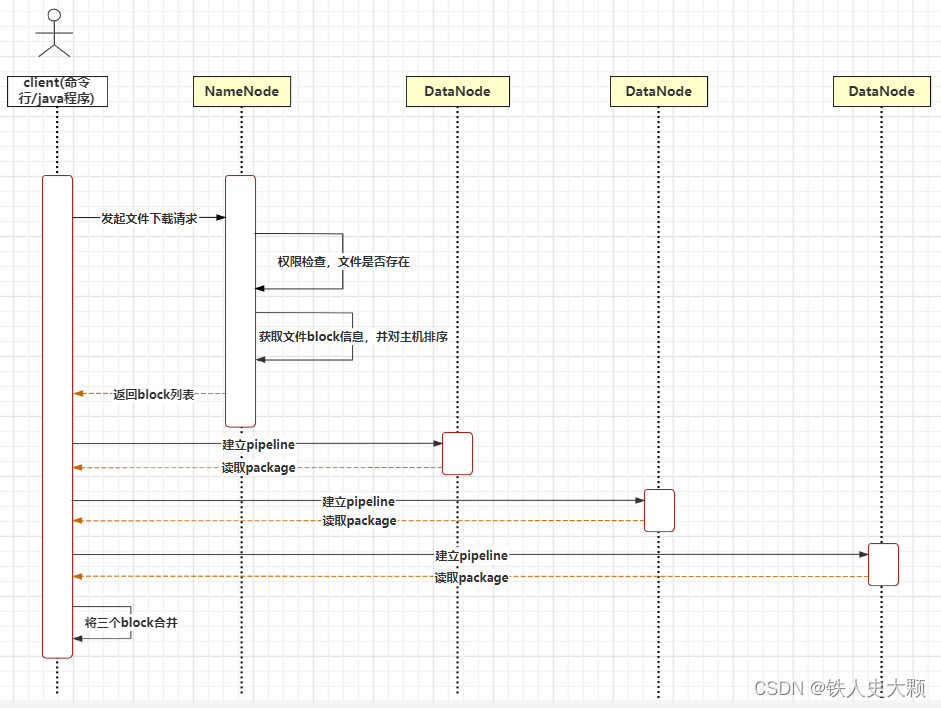
以hadoop fs -get /a.txt /root为例,三副本,文件切成了三个block,分别存放在三台DataNode上。
1.客户端发起下载文件请求。
2.NameNode收到请求后,进行权限检查以及文件目录检查。
3.获取文件的block信息,由于block是三副本,所以会按网络情况进行排序获得主机列表。
4.将三个block的主机列表返回给客户端。之所以返回主机列表是担心只返回一台主机,万一网络出了故障就无法取数据了。
5.客户端同时和三个DataNode建立pipeline(这里只是为了说明过程,而假定的返回的最优主机是三台,实际有可能是一台或者两台,也就是说比如三个block都从DataNode1上取)
6.分别按package为单位读取block。
7.读取完成后,在本地进行合并。
面试问题
1.请简述HDFS读流程
客户端发起读请求,NameNode进行权限检查以及文件目录检查,之后获取block的主机列表返回给客户端。客户端和每个列表的第一台主机建立pipeline开始读数据。读完后在本地合并。
转载地址:https://blog.csdn.net/xingyunyang/article/details/126298655 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
留言是一种美德,欢迎回访!
[***.207.175.100]2024年04月11日 01时51分14秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
Unity中获取物体的尺寸(size)的三种方法
2019-04-27
Unity中的关节组件和绳子效果的实现
2019-04-27
Unity可视化编程插件: Bolt,可以像UE4的蓝图那样啦
2019-04-27
Android的.dex、.odex与.oat文件扫盲
2019-04-27
Unity移动应用如何在Bugly上查看崩溃堆栈
2019-04-27
一分钟搞明白Android的.so文件、ABI和CPU的关系
2019-04-27
UGUI的Text描边Outline拓展
2019-04-27
游戏性能指标参考,游戏质量白皮书下载
2019-04-27
游戏帧同步学习笔记
2019-04-27
Mac苹果电脑分辨率不够用,安装SwitchResX这个软件完美解决
2019-04-27
iOS Info.plist知多少
2019-04-27
XCode9之后命令打包需要使用OptionExport.plist
2019-04-27
关于iOS XCode的entitlements文件
2019-04-27
Airtest自动化测试神器,教你实现Unity自动化测试
2019-04-27
模拟器连接端口汇总和常用ADB命令
2019-04-27
ShaderGraph使用教程与各种特效案例:Unity2020(持续更新)
2019-04-27
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 307851720 位访客
访问时间: 2024-04-25 17:12:50
访问IP: 3.128.94.171
Copyright © 2020 - 2023 blog.css8.cn 京ICP备2021015314号-1
手机版