本文共 2658 字,大约阅读时间需要 8 分钟。
Btree索引(或Balanced Tree),是一种很普遍的数据库索引结构,oracle默认的索引类型(本文也主要依据oracle来讲)。其特点是定位高效、利用率高、自我平衡,特别适用于高基数字段,定位单条或小范围数据非常高效。理论上,使用Btree在亿条数据与100条数据中定位记录的花销相同。
数据结构利用率高、定位高效
Btree索引的数据结构如下:
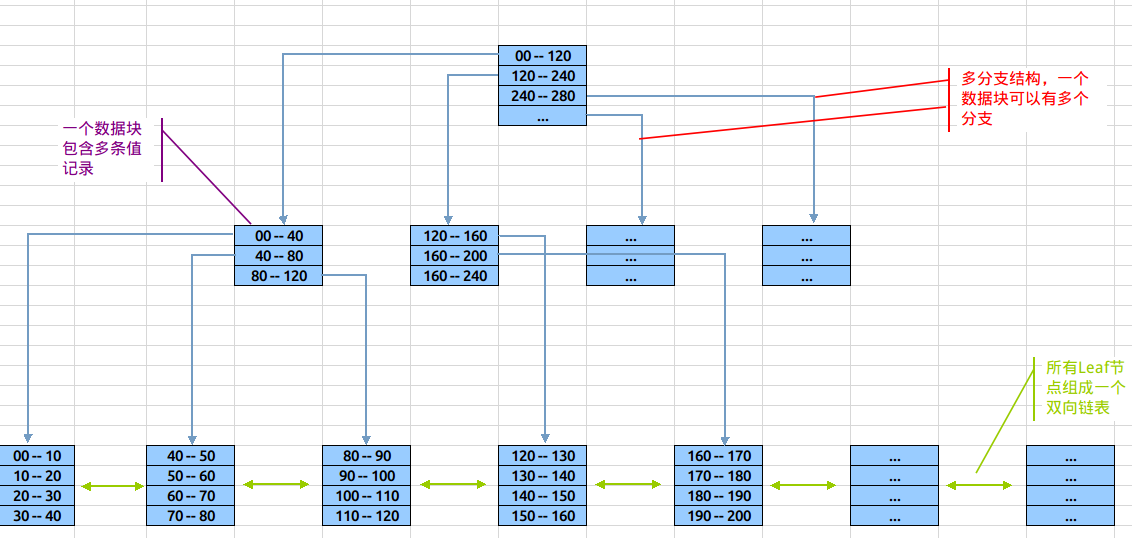
结构看起来Btree索引与Binary Tree相似,但在细节上有所不同,上图中用不同颜色的标示出了Btree索引的几个主要特点:
- 树形结构:由根节(root)、分支(branches)、叶(leaves)三级节点组成,其中分支节点可以有多层。
- 多分支结构:与binary tree不相同的是,btree索引中单root/branch可以有多个子节点(超过2个)。
- 双向链表:整个叶子节点部分是一个双向链表(后面会描述这个设计的作用)
- 单个数据块中包括多条索引记录
这里先把几个特点罗列出来,后面会说到各自的作用。
结构上Btree与Binary Tree的区别,在于binary中每节点代表一个数值,而balanced中root和Btree节点中记录了多条”值范围”条目(如:[60-70][70-80]),这些”值范围”条目分别指向在其范围内的叶子节点。既root与branch可以有多个分支,而不一定是两个,对数据块的利用率更高。
在Leaf节点中,同样也是存放了多条索引记录,这些记录就是具体的索引列值,和与其对应的rowid。另外,在叶节点层上,所有的节点在组成了一个双向链表。 了解基本结构后,下图展示定位数值82的过程:
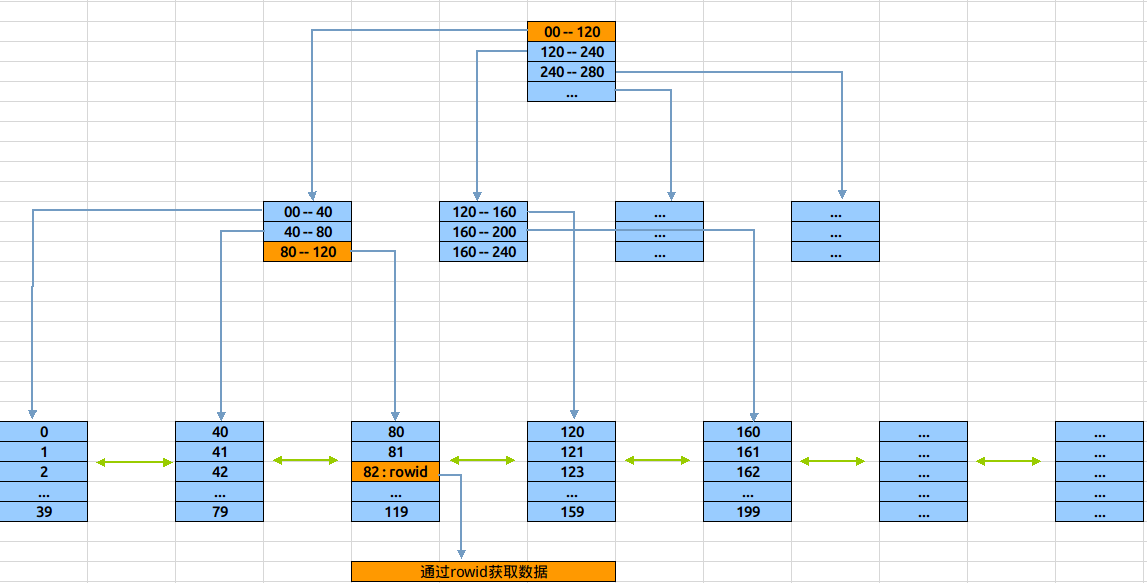
演算如下:读取root节点,判断82大于在0-120之间,走左边分支。读取左边branch节点,判断82大于80且小于等于120,走右边分支。读取右边leaf节点,在该节点中找到数据82及对应的rowid使用rowid去物理表中读取记录数据块(如果是count或者只,则最后一次读取不需要)
在整个索引定位过程中,数据块的读取只有3次。既三次I/O后定位到rowid。
而由于Btree索引对结构的利用率很高,定位高效。当1千万条数据时,Btree索引也是三层结构(依稀记得亿级数据才是3层与4层的分水岭)。定位记录仍只需要三次I/O,这便是开头所说的,100条数据和1千万条数据的定位,在btree索引中的花销是一样的。
平衡扩张
除了利用率高、定位高效外,Btree的另一个特点是能够永远保持平衡,这与它的扩张方式有关。(unbalanced和hotspot是两类问题,之前我一直混在一起),先描述下Btree索引的扩张方式:
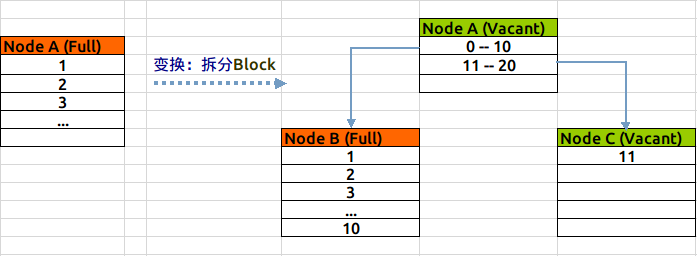
新建一个索引,索引上只会有一个leaf节点,取名为Node A,不断的向这个leaf节点中插入数据后,直到这个节点满,这个过程如下图(绿色表示新建/空闲状态,红色表示节点没有空余空间):

当Node A满之后,我们再向表中插入一条记录,此时索引就需要做拆分处理:会新分配两个数据块NodeB & C,如果新插入的值,大于当前最大值,则将Node A中的值全部插入Node B中,将新插入的值放到Node C中;否则按照5-5比例,将已有数据分别插入到NodeB与C中。
无论采用哪种分割方式,之前的leaf节点A,将变成一个root节点,保存两个范围条目,指向B与C,结构如下图(按第一种拆分形式):
当Node C满之后,此时 Node A仍有空余空间存放条目,所以不需要再拆分,而只是新分配一个数据块Node D,将在Node A中创建指定到Node D的条目:
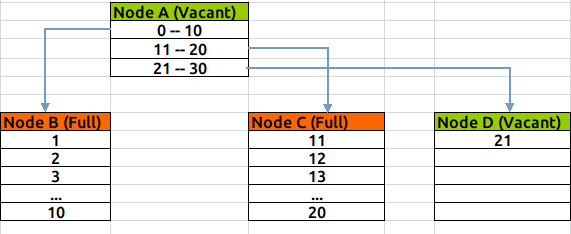
如果当根节点Node A也满了,则需要进一步拆分:新建Node E&F&G,将Node A中范围条目拆分到E&F两个节点中,并建立E&F到BCD节点的关联,向Node G插入索引值。此时E&F为branch节点,G为leaf节点,A为Root节点:
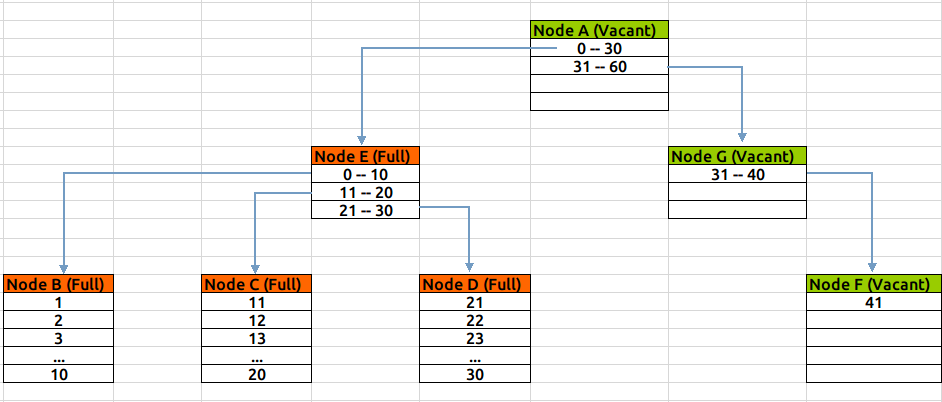
在整个扩张过程中,Btree自身总能保持平衡,Leaf节点的深度能一直保持一致。
实际应用中的一些问题
前面说完了Btree索引的结构与扩张逻辑,接下来讲一些Btree索引在应用中的一些问题:
单一方向扩展引起的索引竞争(Index Contention)
若索引列使用sequence或者timestamp这类只增不减的数据类型。这种情况下Btree索引的增长方向总是不变的,不断的向右边扩展,因为新插入的值永远是最大的。
当一个最大值插入到leaf block中后,leaf block要向上传播,通知上层节点更新所对应的“值范围”条目中的最大值,因此所有靠右边的block(从leaf 到branch甚至root)都需要做更新操作,并且可能因为块写满后执行块拆分。
如果并发插入多个最大值,则最右边索引数据块的的更新与拆分都会存在争抢,影响效率。在AWR报告中可以通过检测enq: TX – index contention事件的时间来评估争抢的影响。解决此类问题可以使用Reverse Index解决,不过会带来新的问题。
Index Browning 索引枯萎(不知道该怎么翻译这个名词,就是指leaves节点”死”了,树枯萎了)
其实oracle针对这个问题有优化机制,但优化的不彻底,所以还是要拿出来的说。
我们知道当表中的数据删除后,索引上对应的索引值是不会删除的,特别是在一性次删除大批量数据后,会造成大量的dead leaf挂到索引树上。考虑以下示例,如果表100以上的数据会部被删除了,但这些记录仍在索引中存在,此时若对该列取max():
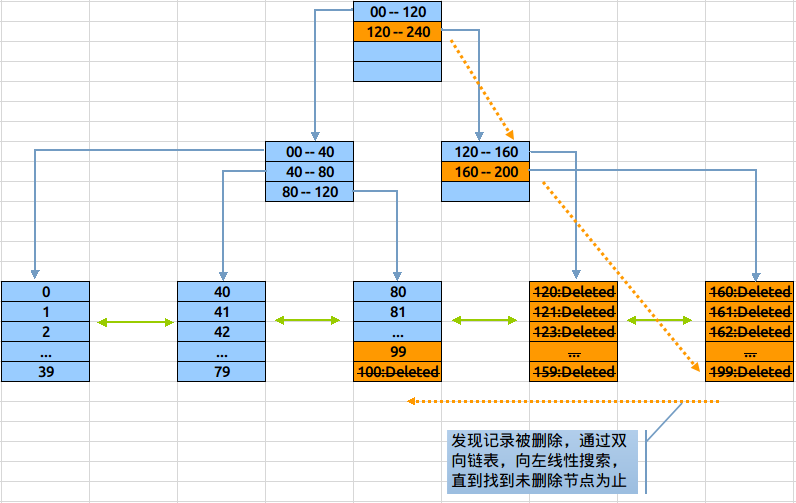
通过与之前相同演算,找到了索引树上最大的数据块,按照记录最大的值应该在这里,但发现这数据块里的数据已经被清空了,与是利用Btree索引的另一个特点:leaves节点是一个双向列表,若数据没有找到就去临近的一个数据块中看看,在这个数据块中发现了最大值99。
在计算最大值的过程中,这次的定位多加载了一个数据块,再极端的情况下,大批量的数据被删除,就会造成大量访问这些dead leaves。
针对这个问题的一般解决办法是重建索引,但记住! 重建索引并不是最优方案,。使用coalesce语句来整理这些dead leaves到freelist中,就可以避免这些问题。理论上oracle中这步操作是可以自动完成的,但在实际中一次性大量删除数据后,oracle在短时间内是反应不过来的。
更多资料:
有点老了
转载地址:https://blog.csdn.net/liao0801_123/article/details/84955443 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
