本文共 31891 字,大约阅读时间需要 106 分钟。
Category组件在Log4Cpp库中,是真正的Logging对象。我们可以使用category对象来进行各种级别的日志操作,比如debug、warn、info…并且这个对象还可以添加各种appender,用来将日志指令分发给各个appender对象来输出到最终目的地上
Category与Appender对象之间的关系(观察者模式)
category与appender之间是一种目标和观察者关系。也就是说它们之间使用的设计模式就是观察者设计模式:category对象会将具体的debug、warn、info…指令分发给内部添加的append对象。
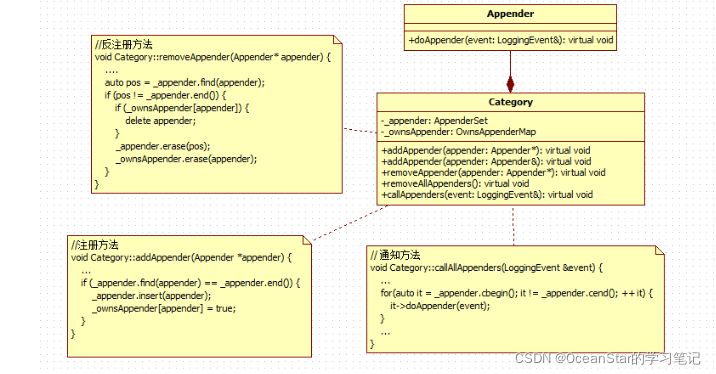
添加/移除Appender对象
class Category { private: typedef std::map OwnsAppenderMap; AppenderSet _appender; //AppenderSet的具体类型是:typedef std::set AppenderSet;在Appender.hh文件中被定义 OwnsAppenderMap _ownsAppender; // 用来复制实现内部添加的Appender对象能够被安全delet的一个辅助信息 mutable threading::Mutex _appenderSetMutex; //锁:一个辅助数据能够安全访问的手段 public: virtual void addAppender(Appender* appender); virtual void addAppender(Appender& appender); virtual void removeAllAppenders(); virtual void removeAppender(Appender* appender); virtual bool ownsAppender(Appender* appender) const throw(); }// 将指定的appender对象,添加到内部的管理容器中,参数无效会抛出std::invalid_argument异常void Category::addAppender(Appender* appender) { if (appender) { threading::ScopedLock lock(_appenderSetMutex); { // 首先检测指定的appender是否已经存在了,只有不存在的时候,才会添加,否则肯定什么也不用做 // 因为传过来的是指针,如果相同的话,则说明根本就是同一个东西 AppenderSet::iterator i = _appender.find(appender); if (_appender.end() == i) { // not found _appender.insert(appender); // 执行真正的添加操作 _ownsAppender[appender] = true; } } } else { throw std::invalid_argument("NULL appender"); // 注意第二个参数设置为true(当category类执行移除操作的时候,你会知道执行他的用意) } } // 另一重载的appender方法 // 执行的逻辑和addAppender(Appender*)版本基本类似,因为appender是引用,那么他肯定是已经存在的对象,所以不用进行空值检测 // 并且也是在已经存在列表中进行查找,如果不存在的话,他才会添加新的内容 // 唯一不一样的是(这儿需要注意):当发现appender是还没有添加的appender的时候,除了将appender插入到_appender容易中,还 // _ownsAppender[&appender] = false; 注意这儿设置为false, 而上面那个版本设置为true void Category::addAppender(Appender& appender) { threading::ScopedLock lock(_appenderSetMutex); { AppenderSet::iterator i = _appender.find(&appender); if (_appender.end() == i) { _appender.insert(&appender); _ownsAppender[&appender] = false; } } } void Category::removeAllAppenders() { threading::ScopedLock lock(_appenderSetMutex); { for (AppenderSet::iterator i = _appender.begin(); i != _appender.end(); i++) { // found OwnsAppenderMap::iterator i2; if (ownsAppender(*i, i2)) { delete (*i); } } _ownsAppender.clear(); //将两个用来记录appender的信息的容器中的信息完全删除 _appender.clear(); } } // 将当前appender从Category移除 void Category::removeAppender(Appender* appender) { threading::ScopedLock lock(_appenderSetMutex); { AppenderSet::iterator i = _appender.find(appender); //首先进行查找 if (_appender.end() != i) { OwnsAppenderMap::iterator i2; // 用来检测当前category对象,是否完全属于appender // 如果是的话,会将这个appender完全delete掉,然后也会将_ownsAppender中这个map对象的存在也移除掉 if (ownsAppender(*i, i2)) { _ownsAppender.erase(i2); delete (*i); } _appender.erase(i); // 不管是否属于肯定会将这个对象从_appender中移除掉 } else { // appender not found } } } // 检测当前category对象是否完全拥有appender对象(只要完全拥有它才有权使用delete来删除) bool Category::ownsAppender(Appender* appender) const throw() { bool owned = false; threading::ScopedLock lock(_appenderSetMutex); { if (NULL != appender) { OwnsAppenderMap::const_iterator i = _ownsAppender.find(appender); if (_ownsAppender.end() != i) { owned = (*i).second; } } } return owned; } 对于目标注册/反注册观察者的方法,总结如下:
- Category实际上使用AppenderSet _appender,来维护添加进来的Appender对象
- Category还使用OwnsAppenderMap _ownsAppender, 来辅助remove方法能够完全释放掉所有已经添加进来的Appender
- Category中的Appender方法,就是类似于观察者模式中的Subject的register方法,而remove方法就类似于Subject中的Unregister方法,可以看到Category完全就是充当一个subject的角色
callAppenders方法(观察者模式中的通知方法)
void Category::callAppenders(const LoggingEvent& event) throw() { threading::ScopedLock lock(_appenderSetMutex); { // 挨个遍历每一个Appender对象,调用appender对象的doAppend方法 if (!_appender.empty()) { for(AppenderSet::const_iterator i = _appender.begin(); i != _appender.end(); i++) { (*i)->doAppend(event); // Appender只是一个接口,其doAppender会执行真正的日志输出 } } } // 下面的代码,你可以暂时不用看,等学完Category的自身结构的时候就明白了 if (getAdditivity() && (getParent() != NULL)) { getParent()->callAppenders(event); } } 我们可以看到,Category::callAppender方法就类似于观察者模式中的Subject的notify方法,而Appender::doAppend方法就类似于观察者模式中的Observer的receive方法。
Category自身的结构(责任链模式)
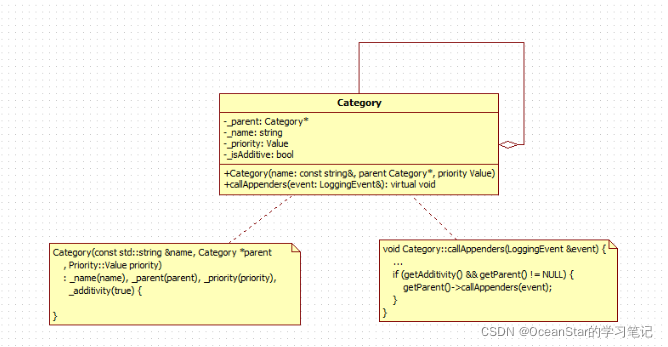
class Category { protected: // 唯一一个可以被子类或者友元调用的构造器 // name是当前category对象的名称 // parent 最后会被设置到_parent属性中(他是我们目前为止唯一需要关心) // priority 表示这个日志能够处理的最低优先级,如果低于这个优先级的日志操作是不会真正进行的 Category(const std::string& name, Category* parent, Priority::Value priority = Priority::NOTSET); private: Category(const Category& other); //禁止拷贝和赋值 Category& operator=(const Category& other); Category* _parent; // 执行父category const std::string _name; //代表category对象的名称 volatile Priority::Value _priority; //代码这个对象所能处理日志的操作的最低优先级 volatile bool _isAdditive; //这个属性,我们暂时不用考虑 } Category::Category(const std::string& name, Category* parent, Priority::Value priority) : _name(name), _parent(parent), _priority(priority), _isAdditive(true) { } 从上面可以看出,Category是一种链式的结果,一个Category对象,还可以指向一个父Category对象,然后父Category对象还可以拥有它自己的父Category,以此类推,可以形成一条很长的Category链。
还可以看到,Category拥有一个唯一的构造器,而且这个构造器是protected的。那么我们怎么实例化它呢?难道我们要继承这个Category类吗?其实Category对象还提供了几个工厂方法。
我们先不要想这些工厂方法,我们先来看一看Category的属性:
- name就是Category类型的名称
- _priority,本质上是一个int类型,Category类的具体日志操作时使用
- _isAdditive,我们来具体看一看。因为我们讲到Category::callAppends方法的时候,里面有一段 代码没有讲,现在我们已经完成了所有必要的基础了,我们回过头来看一下:
void Category::callAppenders(const LoggingEvent& event) throw() { threading::ScopedLock lock(_appenderSetMutex); { // 挨个遍历每一个Appender对象,调用appender对象的doAppend方法 。。。。。。 } // getAdditivity()就是_isAdditivity属性的访问方法, // getParent()获取的是_parent属性 // 我们可以看到下面的逻辑是,如果_isAdditivity==true,则会调用 // 父亲的callAppenders方法,但是父亲也是一个Category对象啊,他仍然会 // 调用自己已经添加Appender对象的doAppend方法,然后检测自己的_isAdditivity,来决定是否将这个LoggingEvent // 继续向上传送处理 if (getAdditivity() && (getParent() != NULL)) { getParent()->callAppenders(event); } } 从这里我们可以看到,其实Category类,还用到了责任链模式:在构造的时候,它会将父Category对象传进来,当执行callAppenders方法的时候,它可以根据_isAdditivity属性的设置情况将event传递给它的父category对象。
即子类的category进行某项日志的时候,其实他默认也会将日志事件 传递给父category的,并且父category处理完后,仍然会向上串。这个功能可能会对某些人有好用,但是可能很多多情况下,并不是如此。需要禁用这个功能
到此整个Category的观察者模式部分已经彻底讲解完毕。
Category的工厂方法(工厂方法)
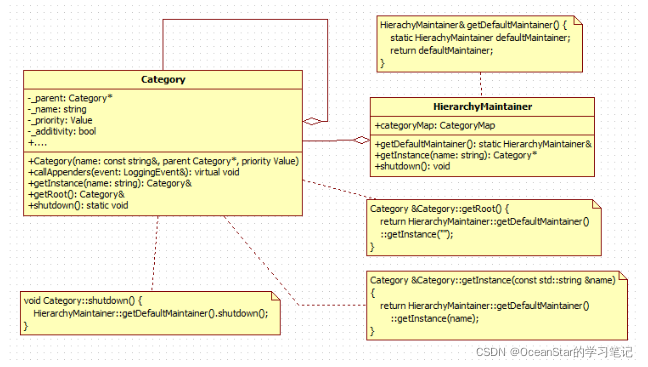
Category& Category::getRoot() { return getInstance(""); } Category& Category::getInstance(const std::string& name) { return HierarchyMaintainer::getDefaultMaintainer().getInstance(name); } 我们可以看到getRoot静态方法内部调用的是getInstance静态方法,而getInstance静态方法内部调用的是 HierarchyMaintainer::getDefaultMaintainer().getInstance(name)
又:
class Category { friend class HierarchyMaintainer; 。。。 }; 即HierarchyMaintainer是Category的友元类,我们再想到,Category提供了一个唯一实现的构造方法,这个构造方法是protected的。可以推测出,HierarchyMaintainer是Category的工厂类。
HierarchyMaintainer
Category的工厂类,内部负责所有Category对象的构造操作。
我们先来看一下它的数据成员
class HierarchyMaintainer { public: typedef std::map CategoryMap; protected: CategoryMap _categoryMap; } 内部包含了一个成员_categoryMap。HierarchyMaintainer 内部创建的Category对象都会保存在_categoryMap容器中,都是通过Category::getInstance方法内部调用的。
下面以HierarchyMaintainer::getDefaultMaintainer().getInstance(name);为引,来看一下整个HierarchyMaintainer类的功能
HierarchyMaintainer::getDefaultMaintainer()方法(一种单例工厂方法的一种实现方式)
class HierarchyMaintainer { public: static HierarchyMaintainer& getDefaultMaintainer(); } // 这个方法是静态的 // 当这个方法第一次被调用的时候,defaultMaintainer会被构造,然后将之返回 // 当下次这个方法被调用时,会直接将此静态对象返回 // 这是单例模式的一种典型实现方式 HierarchyMaintainer& HierarchyMaintainer::getDefaultMaintainer() { static HierarchyMaintainer defaultMaintainer; return defaultMaintainer; } 可以看到,getDefaultMaintainer()其实是HierarchyMaintainer类的一个单例工厂方法。所以HierarchyMaintainer::getDefaultMaintainer().getInstance(name); 内部真正getInstance方法就是HierarchyMaintainer::getInstance方法
HierarchyMaintainer::getInstance方法
class HierarchyMaintainer { public: virtual Category& getInstance(const std::string& name); } Category& HierarchyMaintainer::getInstance(const std::string& name) { threading::ScopedLock lock(_categoryMutex); // 确保getInstance()能够多线程安全的访问 return _getInstance(name); //真正的调用的是_getInstance方法 } 这个方法其实是一个包装方法,它是线程安全的,内部调用的是_getInstance方法。
class HierarchyMaintainer { protected: virtual Category* _getExistingInstance(const std::string& name); virtual Category& _getInstance(const std::string& name); } Category* HierarchyMaintainer::_getExistingInstance(const std::string& name) { Category* result = NULL; CategoryMap::iterator i = _categoryMap.find(name); if (_categoryMap.end() != i) { result = (*i).second; } return result; } Category& HierarchyMaintainer::_getInstance(const std::string& name) { Category* result; // 就是就是检测指定name名称的Cateogory对象是否已经被创建,如果创建好的则将之返回(就是利用利用_categoryMap的find方法) result = _getExistingInstance(name); if (NULL == result) { // 指定名称的category对象还没有被创建,需要创建一个 // name为"",说明创建的是root if (name == "") { // 第二个参数为NULL,表示没有父category指针(根没有父category) // 即Category::getRoot方法实现是:HierarchyMaintainer::getDefaultMainter().getInstance(""); result = new Category(name, NULL, Priority::INFO); } else { // name的格式可以包含多个点: // 比如 parentparent.parent.son.sonson std::string parentName; size_t dotIndex = name.find_last_of('.'); //首先查找的最后一个.的位置 if (name.length() <= dotIndex) { // 这儿为什么是小于等于呢?是因为当name没有找到'.'的时候返回的是std::size_t(-1) parentName = ""; // 这个值是size_t即unsigned int(是无符号)中最大的值,没有比他再大了 } else { parentName = name.substr(0, dotIndex); //不包最后点的名称。比方name是parentparent.parent.son.sonson,那么这儿parentName就是parentparent.parent.son } Category& parent = _getInstance(parentName); // 递归调用,相当于先创建父category result = new Category(name, &parent, Priority::NOTSET); // 然后使用创建号的父category来创建子category } _categoryMap[name] = result; //最终创建号的category对象,会保存到_categoryMap属性中,以category对象的name为key } return *result; } 这个方法是整个工厂方法的核心所在,主要执行如下流程:
- 检测name是否已经创建号了,如果创建号了,则将之返回
- 检测name是否为空,如果是,那么创建一个根节点(有一个细节,根节点的priority属性默认设置为Priority::INFO),并且将这个新建的节点保存到_categoryMap属性中
- 3.如果name不为空,那么他首先先递归调用_getInstance方法获取 name名称所指定的父节点(比如name是parent.son,那么他会使用 _getInstance(“parent”)来创建父节点),然后使用创建号的父category对象来新建一个子category,也就是指定name的category对象。(这儿 也有一个细节,非根节点的priority属性设置为Priority::NOTSET),并且将之添加到_categoryMap中(以name为key,以新建的category指针为值)
- 上面递归调用中,比如name=parent.son,那么它会调用_getInstance(“parent”),然后这个方法内部 又会调用_getInstance(""),此方法返回根节点记为root,然后继续回到_getInstance(“parent”)中,新建一个Category(“parent”, root, Priority::NOTSET),假设为p,然后将这个对象返回,继续回到_getInstane(“parent.son”)来执行,则会返回Category(“parent.son”, p, Priority:NOTSET)
根据这个_getInstance方法的实现我们可以知道:
- 首先指定的name可以包含几个’.’
- 根Category对象的默认_priority属性是Priority::INFO,其他的非根Category对象的_priority属性Priority::NOTSET属性。
- 所有创建好的Category对象,都被备份到HieratchyMaintainer的_categoryMap属性中
HierarchyMaintainer::~HierarchyMaintainer的析构方法
class HierarchyMaintainer { public: virtual ~HierarchyMaintainer(); } HierarchyMaintainer::~HierarchyMaintainer() { shutdown(); deleteAllCategories(); } 我们可以看到执行了shutdown()方法和deleteAllCategories()方法。
HierarchyMaintainer::shutdown方法
下面我们看一下shutdown()方法,但是在看这个方法之前,我们要看一下准备:
class HierarchyMaintainer { public: typedef void (*shutdown_fun_ptr)(); //定义了一种不带参数没有返回值的函数指针类型,其实就是一种类型回调函数 void register_shutdown_handler(shutdown_fun_ptr handler); //注册指定回调函数到handlers中 private: typedef std::vector handlers_t; //用来保存函数指针的容器类型 handlers_t handlers_; } //注册指定回调函数到handlers中 void HierarchyMaintainer::register_shutdown_handler(shutdown_fun_ptr handler) { handlers_.push_back(handler); } 即HierarchyMaintainer体供了可以用来扩展的回调函数,至于这些回调函数的具体功能,我们需要看一下这个类的shutdown方法。
class HierarchyMaintainer { public: virtual void shutdown(); } void HierarchyMaintainer::shutdown() { threading::ScopedLock lock(_categoryMutex); //保证此方法是线程安全的 { // 清除所有的已经实例化好的Category对象内部的Appender对象(通过调用Category的removeAllAppenders方法来实现,这个方法我们前面已经讨论过) for(CategoryMap::const_iterator i = _categoryMap.begin(); i != _categoryMap.end(); i++) { ((*i).second)->removeAllAppenders(); } } // 调用使用register_shutdown_handler添加过来的回调函数 // 其实你可以看到,他也是有限制的,因为到有一个回调函数发生以后的时候,那么其他的回调函数都没有机会被执行了 // 不知道,是设置者是有心的还是无心的过失,个人认为可以将这个try ... catch...块添加到for循环的内部 try { for(handlers_t::const_iterator i = handlers_.begin(), last = handlers_.end(); i != last; ++i) (**i)(); } catch(...) { } } 简单总结一下HierarchyMaintainer::shutdown方法功能:
- 清除所有已经创建号的category对象内部已经添加的appener
- 调用所有已经注册进来的回调函数。需要注意的是:这个回调函数不能发生异常,否则可能终止这个回调函数后面注册进来的回调参数
HierarchyMaintainer::deleteAllCategories方法
class HierarchyMaintainer { public: virtual void deleteAllCategories(); } void HierarchyMaintainer::deleteAllCategories() { threading::ScopedLock lock(_categoryMutex); { for(CategoryMap::const_iterator i = _categoryMap.begin(); i != _categoryMap.end(); i++) { delete ((*i).second); } _categoryMap.clear(); } } 这个方法非常简单,直接delete掉_categoryMap内部的所有的成员,这样就不会发生内存泄露了
上面介绍的getInstance()方法和析构方法是整个类的核心功能所在,即用来创建Category对象,和用来维护已经创建好的Category对象。
小结:
- HierarchyMaintainer方法的工厂方法getInstance()和对每个category对象进行清理的shutdown()方法,和释放内部所有已经创建好的category对象的deleteAllCategories()方法,它们都是线程安全的
- 当HierarchyMaintainer对象被销毁的时候,它会自动调用shutdown()方法和deleteAllCategories()方法。,所以说,对于 整个程序来即使程序最后没有调用Category::shutdown()方法,也不会发生任何资源资料的。这就是说,这个工厂类来负责维护所有已经创建号的category对象的生命周期。
- 3.对于使用getInstance方法创建的含有父亲的category对象,他们的名称是包含有点的名称,而不是最后点号后面的名称,我们可以从 getInstance()中来寻找到原因。
其他方法:
// 是否存在name对象的category Category* HierarchyMaintainer::getExistingInstance(const std::string& name) { threading::ScopedLock lock(_categoryMutex); return _getExistingInstance(name); } // 当前已经创建的所有category std::vector * HierarchyMaintainer::getCurrentCategories() const { std::vector * categories = new std::vector ; threading::ScopedLock lock(_categoryMutex); { for(CategoryMap::const_iterator i = _categoryMap.begin(); i != _categoryMap.end(); i++) { categories->push_back((*i).second); } } return categories; } Category::shutdown()
Category的资源回收方法
class Category { public: static void shutdown(); } void Category::shutdown() { HierarchyMaintainer::getDefaultMaintainer().shutdown(); } Category对象的shutdown方法,内部实际上调用的是上一节中介绍的HierarchyMaintainer.shutdown方法。内部执行步骤可以简单回忆一下:
- 调用所有category的removeAllAppenders方法,来delete掉所有拥有的Appender对象,并且清空category对象内部的_appender容器中的内容,和ownsAppender容器中的内容、
- 调用HierarchyMaintainer内部注册进的回调函数。(其实对于这一步,通过阅读Category的整个实现,他并没有注册任何回调函数,也就是 说,这个拓展清理机制,在实际使用中并没有被用到。)
- 补充:所有创建的的category对象,其实并没有被销毁。它的销毁时机是HierarchyMaintainer::getDefaultMaintainer()方法内部定义的static变量被销毁的时候。这里只是销毁了所有被category对象完全拥有的Appender。
看一下Category对象的析构方法:
class Category { public: ~Category(); ...... }; ~Category::Category() { removeAllAppenders();} 就是移除内部所有的Appender对象。存在这个方法,单独上来考虑是合理的,但是因为Category对象的生命周期是完全由HierachyMaintainer对象 来维护的,而在HierachyMaintainer的shutdown方法中,拥有此方法的功能,在HierachyMaintainer的析构方法中,也有此功能,所以我认为, 要么这个类的析构方法中不做任何处理,要么将就HierachyMaintainer::shutdown方法,不要提供调用每一个category对象的removeAllAppenders这个流程。 我认为前者更合理,就是不在Category的析构方法中进行任何处理。
Category的日志方法
Category可以用来输出各种不同的日志,并且也处理了一种需求,比如某些情况下,我想输出各种类型的信息,包括错误信息、普通信息、调试信息,但是某些情况下,我们只想看到错误信息。category使用了Prority::Value _priority属性来实现。
Priority这个类,其内部有一个PriorityLevel枚举类型,内部定义了各种枚举常量,定义了一个typedef int Value; 还定义了两工具函数,一个是getPriorityName,可以将Value类型转换为字符串类型,比如getPriorityName(Priority::DEBUG)返回"DEBUG",一个是 getPriorityValue,将字符串转换为Value,比如getPriorityValue(“DEBUG”) 则输出为Priority::DEBUG,这个方法字符串还可以是数字,比如 getPriorityValue(“123”)则返回则为123,一般不这样使用。
用来确定某种日志级别的操作是否执行的辅助方法是isPriorityEnabled,源码如下:
bool Category::isPriorityEnabled(Priority::Value priority) const throw() { return(getChainedPriority() >= priority); // 只有当设置的_priority值大于指定priority值的时候才会返回true } // 上面getChainedPriority方法的实现 Priority::Value Category::getChainedPriority() const throw() { // REQUIRE(rootCategory->getPriority() != Priority::NOTSET) ,这儿的条件肯定是成立的, //因为root对象使用HierachyMaintainer::getInstance(""),内部当name为空,他创建的root的priority值为Priority::INFO //所以只要不人为将root Category的priority设置为Priority::NOTSET,下面的程序就不会crush // 子 -> 父 -> 父。。。查找到第一个_priority属性不是设置为Priority::NOTSET,因为root的默认_priority为Priority::INFO // 这个循环是肯定能够终止的。 const Category* c = this; while(c->getPriority() >= Priority::NOTSET) { c = c->getParent(); } return c->getPriority(); } void Category::setPriority(Priority::Value priority) { if ((priority < Priority::NOTSET) || (getParent() != NULL)) { _priority = priority; } else { /* caller tried to set NOTSET priority to root Category. Bad caller! */ throw std::invalid_argument("cannot set priority NOTSET on Root Category"); } } 正如我们可以看到,当内部设置的_priority的值大于指定的priority值的时候,那么表示进行的操作都是满足的。
下面我们来看一下一个具体的记录日志方法,我们选择的是debug方法,对于其他的info, alert, warn。。。他们的组成都是相同的。我们可以看一下他们的 类似结构:
class Category { public: void debug(const char* stringFormat, ...) throw(); void debug(const std::string& message) throw(); inline bool isDebugEnabled() const throw() { return isPriorityEnabled(Priority::DEBUG); }; inline CategoryStream debugStream() { return getStream(Priority::DEBUG); } } class Category { public: void info(const char* stringFormat, ...) throw(); void info(const std::string& message) throw(); inline bool isInfoEnabled() const throw() { return isPriorityEnabled(Priority::INFO); }; inline CategoryStream infoStream() { return getStream(Priority::INFO); } } class Category { public: void notice(const char* stringFormat, ...) throw(); void notice(const std::string& message) throw(); inline bool isNoticeEnabled() const throw() { return isPriorityEnabled(Priority::NOTICE); }; inline CategoryStream noticeStream() { return getStream(Priority::NOTICE); } } 。。。。 下面仅以debug方面的方法来进行系统介绍。
void debug(const char* stringFormat, …)
void Category::debug(const char* stringFormat, ...) throw() { // 首先检测权限 if (isPriorityEnabled(Priority::DEBUG)) { va_list va; va_start(va,stringFormat); _logUnconditionally(Priority::DEBUG, stringFormat, va); //进行真正的日志操作 va_end(va); }} 可以看到,这个类会首先检测当前权限是否支持Priority::DEBUG,只要_priorty > Priority::DEBUG就支持。然后初始化可变参数进行真正的日志操作,然后释放可变参数。所以关键就是_logUnconditionally实现。
_logUnconditionally
class Category { protected: virtual void _logUnconditionally(Priority::Value priority, const char* format, va_list arguments) throw(); } void Category::_logUnconditionally(Priority::Value priority, const char* format, va_list arguments) throw() { _logUnconditionally2(priority, StringUtil::vform(format, arguments)); } _logUnconditionally2
class Category { protected: virtual void _logUnconditionally2(Priority::Value priority, const std::string& message) throw(); } void Category::_logUnconditionally2(Priority::Value priority, const std::string& message) throw() { //组装一个日志事件对象:当前category对象的名称;需要写入的消息;当前线程的NDC值,如果没有使用NDC::put放入的话,则返回为空字符串;这个日志操作的等级 LoggingEvent event(getName(), message, NDC::get(), priority); callAppenders(event);// 将这个日志事件对象调用我们上面介绍的通知接口,将这个对象分发到各个appener中 } //--------------------- const std::string& Category::getName() const throw() { return _name; } //--------------------- const std::string& NDC::get() { if (isUsedNDC) return getNDC()._get(); else return emptyString; } const std::string& NDC::_get() const { static std::string empty = ""; return (_stack.empty() ? empty : _stack.back().fullMessage); } 总结一下void debug(const char* stringFormat, …)的执行流程:首先组织可变参数,然后调用_logUnconditionally分发,而_logUnconditionally内部利用StringUtil::vform方法将可变参数转换为字符串,然后调用 _logUnconditionally2方法,此方法内部构建LoggingEvent对象,然后利用我们前面介绍的通知方法callAllAppener方法,将此LoggingEvent对象分发出去。
void Category::debug(const std::string& message) throw()
void Category::debug(const std::string& message) throw() { // 先检测当前cateogry权限是否支持debug操作 if (isPriorityEnabled(Priority::DEBUG)) _logUnconditionally2(Priority::DEBUG, message); //直接调用_logUnconditionally2来构建LoggingEvent并且将之分发给 //各个appender对象} 和使用支持格式化字符串和可变参数的版本相比,少了转换为字符串的过程,而是直接调用_logUnconditionally2来进行 组装日志对象和分发日志对象。
debugStream()
class Category { public: ... // 获取的是输出debug信息的流对象,此流输出的所有消息都是debug消息 // 我们可以向这样来使用流 // Category &root = Category::getRoot(); // ... 进行一些设置 // CategoryStream debugStream = root.debugStream(); // debugStream << 3 << "is greater than" << 4 << eol; inline CategoryStream debugStream() { return getStream(Priority::DEBUG); } };// 内部直接返回一个CategoryStream对象 CategoryStream Category::getStream(Priority::Value priority) { return CategoryStream(*this, isPriorityEnabled(priority) ? priority : Priority::NOTSET); //我们暂时先放一放,下面看一下CategoryStream的实现 我们可以看到debugStream返回的是一个CategoryStream的对象,我们可以看一下CategoryStream的实现
CategoryStream
这个类是一个支持流风格的流,但是它们并没有继承任何已有的流对象,它的内部实现是使用聚合一个字符串流来实现的。这个类算是一个输出流,它的输出目标是某个具体的category对象。
我们先来看一下它的数据成员
class CategoryStream { private: Category& _category; // 所关联的category对象 Priority::Value _priority; //日志的等级 union { std::ostringstream* _buffer; #if LOG4CPP_HAS_WCHAR_T != 0 // 对于这儿的设计我真的是不敢恭维,等到后面看他的算法实现就知道 std::wostringstream* _wbuffer; #endif }; // 作为缓冲区 public: CategoryStream(Category& category, Priority::Value priority); } CategoryStream::CategoryStream(Category& category, Priority::Value priority) : _category(category), _priority(priority), _buffer(NULL) { } _cateogory就是最后要输出的目的地,_priority是进行输出操作的等级,_buffer是作为CategoryStream的缓存区而存在的。
CategoryStream::operator<<
class CategoryStream { public: template CategoryStream& operator<<(const T& t) { if (getPriority() != Priority::NOTSET) { //只有当从构造器中传来的priority不是Priority::NOTSET的时候,它才会进行真正的日志输出操作。 if (!_buffer) { // 首先要检查输入流缓冲区是否存在,不存在的话就创建,然后将输出输出到这个缓冲区中 if (!(_buffer = new std::ostringstream)) { // XXX help help help } } (*_buffer) << t; } return *this; } // 居然还没有这个实现,不是已经有模板成员方法了吗?(实现逻辑和上面的基本一致) CategoryStream& operator<<(const char* t); // 这个方法真搞笑,内部根本就没有用到类型T,为什么要在头上加个T(而且函数根本就没有偏特例化这个概念) // 并且我经过实测,对于vs2013上来讲,这个方法是永远也调用不到, // 即使我的输出对象是std::string方法,感觉有点误人子弟啊,有木有。我不知道log4cpp对于编译器兼容考虑还是什么原因 // 总之下面的方法根本就不应该存在 template CategoryStream& operator<<(const std::string& t) { if (getPriority() != Priority::NOTSET) { if (!_buffer) { if (!(_buffer = new std::ostringstream)) { // XXX help help help } } (*_buffer) << t; } return *this; } // 同上,内部方法永远无法执行,可能vs2013内置C++编译器看到这种写法,就直接将这个模板成员方法给剔除掉了 #if LOG4CPP_HAS_WCHAR_T != 0 template CategoryStream& operator<<(const std::wstring& t) { if (getPriority() != Priority::NOTSET) { if (!_wbuffer) { if (!(_wbuffer = new std::wostringstream)) { // XXX help help help } } (*_wbuffer) << t; } return *this; } #endif} 我们可以看到,第一个目标方法,已经完成了对各种常用类型的流支持,但是它不支持宽字符类型(不相信的朋友可以试一下, 你先传入一个L"123"到oeprator<<是可以编译通过的,但是输出的内容不是你想要的内容,然后你在传入一个wstring(L"123")到operator<< 中,编译器根本就无法编译成功)。到目前为止,它只是将内容输出到内部的_buffer中,并没有将内容输出到内部的category对象。
而且,在CategoryStream& operator<<(const T& t)模板方法中,会检测_priority属性是否为Priority::NOTSET, 只有当_priority不等于Priority::NOTSET的时候,才会将内容输出到缓冲区中,否则是不进行任何操作的。再次申明这里是非常重要的,明白这儿就会明白Category::debugStream()方法的返回的是CategoryStream(isPriorityEnabled(Priority::DEBUG) ? priority : Priority::NOTSET);当权限不支持debug操作时,这个流是无法进行任何输出操作的
CategoryStream::flush方法
class CategoryStream { public: void flush(); } void CategoryStream::flush() { if (_buffer) { // 缓冲区存在内容的话,他就会将缓冲区的内容通过_category.log方法输出到_category中 getCategory().log(getPriority(), _buffer->str()); //getCategory()获取的就是通过构造器传进来的_category对象 delete _buffer; _buffer = NULL; } } 我们可以看到,categoryStream的flush操作,就是将缓冲区的内容通过_category.log方法输出到_categroy对象中。其实Cateogory::log方法 和我们上面介绍的debug方法功能是类似的,debug方法只能输出Priority::DEBUG权限的消息,而logg方法则比debug方法都一个功能,那么就是它可以指定一个输出权限。
我们来看一下category::log方法的实现
// 多了一个参数,用来设置输出权限等级,内部实现和debug的内部实现基本一致 void Category::log(Priority::Value priority, const std::string& message) throw() { if (isPriorityEnabled(priority)) _logUnconditionally2(priority, message); } CategoryStream流控制函数的支持
到目前为止,已经讲述了CategoryStream的数据成员,构造函数,以及operator<<和flush,另外Category还为我们提供了几个 流控制符函数,通过这些函数,我们可以知道向std::cout << std::endl, std::cout << std::flush,实现类似这种风格的 原理,我们来看一下这几个函数。
class CategoryStream { public: typedef CategoryStream& (*cspf) (CategoryStream&); //定义了一种函数类型 CategoryStream& operator << (cspf); //关键是这个方法,他让我们支持categoryStream << eol; 这样的写法 std::streamsize width(std::streamsize wide ); // 用来设置每次流输出的宽度,内部是调用的_buffer->width方法来实现的 // 声明了两个友元函数 friend CategoryStream& eol (CategoryStream& os); friend CategoryStream& left (CategoryStream& os); } // 内部直接就是将CategoryStream对象交给pf处理,并且返回其值 CategoryStream& CategoryStream::operator<< (cspf pf) { return (*pf)(*this); } // 执行的功能等价于std::flush,会刷新缓冲区中的内容到Category对象中 CategoryStream& eol (CategoryStream& os) { if (os._buffer) { //缓冲区中有内容则要缓冲区内容进行刷出 os.flush(); } return os; } // 用来设置缓冲区的对齐方式,内部就是通过std::ostringstream的setf标志来实现 // 当指定的宽度大于实际输出值的宽度的时候,他会自动将内容对齐到左面,右边会留空的 CategoryStream& left (CategoryStream& os) { if (os._buffer) { os._buffer->setf(std::ios::left); } return os; } // 用来设置每次流输出的宽度,内部是调用的_buffer->width方法来实现的 std::streamsize CategoryStream::width(std::streamsize wide ) { if (getPriority() != Priority::NOTSET) { if (!_buffer) { if (!(_buffer = new std::ostringstream)) { // XXX help help help } } } return _buffer->width(wide); } 好了到目前为止,CategoryStream的流控制相关方法,只剩下两个get方法,只是用来获取内部属性,在此就不在啰嗦了。
现在回过头来再看一下Category:;getStream方法实现的getStream()。
CategoryStream Category::getStream(Priority::Value priority) { return CategoryStream(*this, isPriorityEnabled(priority) ? priority : Priority::NOTSET); //关键就是第二个参数的设置,当priority不在category对象的权限范围内的时候,他会将第二个参数设置为Priority::NOTSET} 正如我们源码注释讲的那样,当priority不被当前Category对象支持的时候,他会将新建的CategoryStream的_priority属性设置为 Priority::NOTSET,原因,前面在介绍CategoryStream::operator<<(const T&)这个方法时候已经介绍过,这儿再次重复一下:
templateCategoryStream& CategoryStream::operator<<(const T& t) { // 只有当从构造器中传过来的priority不是Priority::NOTSET的时候,它才会进行真正的日志输出操作 if (getPriority() != Priority::NOTSET) { if (!_buffer) { if (!(_buffer = new std::ostringstream)) { // XXX help help help } } (*_buffer) << t; } return *this;}
只有当CategoryStream的_priority属性不是Priority::NOTSET的时候,它才会将输出流中的内容输出到缓冲区中,否则它是什么也不干的。也就是说上面的getStream(Priority::Value priority)对象返回的流有两种,一种是可以进行正常输出的流,一种是不能进行正常输出的流。
总结
- 首先我们讲解了category和appener之间的关系,这里采用了观察者设计模式,并且介绍了相应的注册/反注册方法( addAppender(Appender*), addAppender(Appender&)),和对应的通知方法(callAppenders)。
- 对于添加方法,它内部使用了两个容器来维护内部添加进来的Appender对象,一个AppenderSet _appender用来保存所有添加进来的Appender对象,一个_ownsAppender用来记录某个对象是否被完全拥有。当删除某个Appender对象,获取移除所有Appender对象的时候,,_ownsAppender可以用来 检测某个Apepnder是否能够使用delete运算符来删除掉。
- callAppenders调用每个Appender对象的doAppend方法来讲LoggingEvent对象通知给它们,并且根据_additivity属性来决定是否将此事件传递给它的父类。
- 然后我们分析了Category的结构。Category有一个成员Category *_parent,这个参数是通过构造函数传递进来的。另外,在callAppends方法中,除了通知所有已添加的Appender对象,还会根据_additvity的值来决定是否调用_parent.callAllAppenders方法,父类同样此逻辑。这是典型的责任链模式。
- 再之后我们学习了Category对象的工程方法getRoot()方法和getInstance()方法。它们内部其实调用的是HierachyMaintainer的 getInstance方法,然后我们详细介绍了这个HierachyMaintainer类,他实际上就是Category的工厂类,加上维护类,我们通过阅读源码知道, HierachyMaintainer的getInstance的方法首先是线程安全,并且将传递的名称为"",返回的是根Category,当不为空的时候,我们可以 传递xx.xx.xx来创建一个Category对象,HierachyMaintainer工厂方法会自动构建此链上的相关对象并且将最终对象返回,注意返回的对象的名称 仍然是xx.xx.xx,通过读源码,我们会发现,这个工厂类的getInstance()方法是线程安全的。
- 然后我们介绍了Category对象的shutdown方法,这个类内部调用的仍然是HierachyMaintainer类的shutdown方法,在此方法内部执行如下逻辑, 首先调用所有已经创建好的Category对象的removeAllAppenders方法,然后调用内部注册的好多回调函数(当有异常发生,那么后面的回调函数 都不会被执行)。至于这个利用回调函数来进行额外进行某些操作的特性,在整个Category设计中并没有被使用到。还有呢,在HierachyMaintainer 的析构函数中,会先调用shutdown方法,然后调用removeAllCategories方法,前者已经介绍过,后者,内部实现就是delete所有已经实例化的Category 对象,避免内存发生泄漏。
- 对于HierachyMaintainer,这个类实际被Category使用的对象只有一个,Category获取 HierachyMaintainer对象是通过HierachyMaintainer::getDefaultMaintainer方法来实现。这是个HierachyMaintainer类,并没有对构造器 进行私有化,所以我们认为可能HierachyMaintainer是非严格意义上的单例设计,因为他提供了一个单例的工厂方法。
- 下面我们选择某一个具体的日志操作来介绍,我们选择的是debug操作,我们讲解了Category类对于某些级别的检测方法,isPriorityEnabled方法, 内部是检测_priority是否大于函数传进来的优先级。然后我们介绍了debug的几个重载方法,和debugStream方法,debug两个重载方法执行逻辑 都是一致的,当有格式化字符串和可变参数的时候,他们会构造可变参数然后调用_logUnconditionally方法,此方法内部会利用StringUtil::vform 来将格式化字符串和可变参数转换为字符串。然后调用_logUnconditionally2来进行真正的日志操作,此方法会利用一些信息来构建LoggingEvent对象,然后调用我们上面介绍的通知方法callAppenders来讲LoggingEvent对象通知给已经注册进来的所有的Apender对象,并且根据_additivity属性来 确定是否将此事件传递给父Category对象
- 最后我们讲解了debugStream方法的实现,内部调用的是getStream方法,而getStream方法返回的是一个CategoryStream对象,并且根据是否支持对应的priority操作来将它第二个参数设置为Priority::NOTSET。
- 对于CategoryStream,内部其实是聚合了一个std::ostringstream对象,它是将这个对象作为缓冲区,并且提供了一个支持常用类型的模板方法operator<<来实现对于大多数类型的输出流支持,并且对于 这个模板方法,我们也详细说明了那儿在输出之前他会对内部的_priority属性进行判断,如果只为Priority::NOTSET则不进行任何操作。这儿也就是 Category::getStream那个方法那儿里面那样实现的原因。CategoryStream还为我们提供了控制流输出的函数,比如eol, 比如left。总之当我们不想 使用格式化字符串 + 可变参数的时候,可以尝试使用这个方法。
转载地址:https://blog.csdn.net/zhizhengguan/article/details/123221348 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
