本文共 2813 字,大约阅读时间需要 9 分钟。
如何量化两个字符串的相似度
量化两个字符串的相似度有一个非常著名的量化方法,那就是编辑距离。
所谓编辑距离就是指,将一个字符串转换成另一个字符串,需要的最少编辑操作次数(比如增加一个字符、删除一个字符、替换一个字符)。编辑距离越大,说明两个字符串的相似程度越小;编辑距离越小,说明两个字符串的相似程度越大。对于两个完全相同的字符串来说,编辑距离就是0.
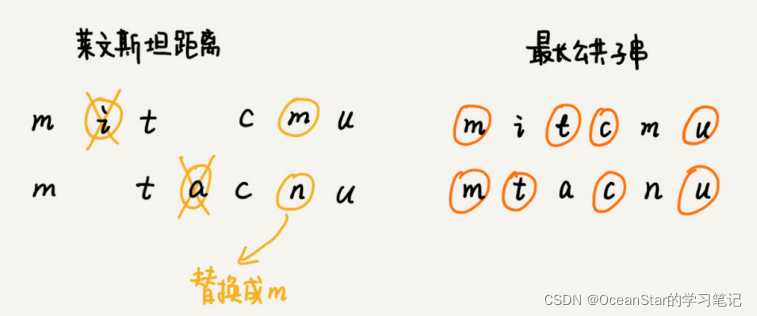
根据所包含的编辑,编辑距离有多种不同的计算方式,比较著名的有莱文斯坦距离和最长公共子串长度。其中,莱温斯坦距离允许增加、删除、替换字符这三个编辑操作,最长公共子串长度只允许增加、删除字符这两个编辑操作。
而且,莱温斯坦距离和最长公共子串长度,从两个截然相反的角度,分析字符串的相似程度。莱温斯坦距离的大小,表示两个字符串差异的大小;最长公共子串的大小,表示两个字符串相似程度的大小。
比如,两个字符串 mitcmu 和mtacnu 的莱文斯坦距离是 3,最长公共子串长度是 4。
如何编程计算莱文斯坦距离?
这个问题是求一个字符串变成另一个字符串,需要的是最少编辑次数。整个求解过程,涉及多个决策阶段,我们需要依次考察一个字符串中的每个字符,跟另一个字符串中的字符是否匹配,匹配的话如何处理,不匹配的话又如何处理。所以,这个问题符合多阶段决策最优解模型。
要解决这个问题,我们先来用最简单的回溯算法来解决。
回溯是一个递归处理的过程,如果 a [ i ] a[i] a[i]和 a [ j ] a[j] a[j]匹配,我们递归考察 a [ i + 1 ] a[i+1] a[i+1]和 b [ j + 1 ] b[j+1] b[j+1]。如果 a [ i ] a[i] a[i]和 b [ j ] b[j] b[j]不匹配,那我们有多种处理方式可选:
- 可以删除 a [ i ] a[i] a[i],然后递归考察 a [ i + 1 ] a[i+1] a[i+1]和 b [ j ] b[j] b[j]
- 可以删除 b [ i ] b[i] b[i],然后递归考察 a [ i ] a[i] a[i]和 b [ j + 1 ] b[j+1] b[j+1]
- 可以在 a [ i ] a[i] a[i]前面添加一个跟 b [ j ] b[j] b[j]相同的字符,然后递归考察 a [ i ] a[i] a[i]和 b [ j + 1 ] b[j+1] b[j+1]
- 可以在 b [ j ] b[j] b[j]前面添加一个跟 a [ i ] a[i] a[i]相同的字符,然后递归考察 a [ i + 1 ] a[i+1] a[i+1] 和 b [ j ] b[j] b[j]
- 可以将 a [ i ] a[i] a[i] 替换成 b [ j ] b[j] b[j],或者将 b [ j ] b[j] b[j]替换成 a[i],然后递归考察 a [ i + 1 ] a[i+1] a[i+1] 和 b [ j + 1 ] b[j+1] b[j+1]
上面过程代码实现如下:
private char[] a = "mitcmu".toCharArray(); private char[] b = "mtacnu".toCharArray(); private int n = 6; private int m = 6; private int minDist = Integer.MAX_VALUE; //存储结果 // 调用 lwstDT(0, 0, 0); public void lwstBT(int i, int j, int edist){ if(i == n || j == m){ if(i < n){ edist += (n - i); } if(j < m){ edist += (m - j); } if(edist < minDist){ minDist = edist; } return; } // 两个字符匹配 if(a[i] == b[j]){ lwstBT(i +1, j + 1, edist); }else{ //两个字符不匹配 lwstBT(i + 1, j, edist + 1); // 删除 a[i] 或者 b[j] 前添加一个字符 lwstBT(i, j + 1, edist + 1); // 删除 b[j] 或者 a[i] 前添加一个字符 lwstBT(i + 1, j + 1, edist + 1); // 将 a[i] 和 b[j] 替换为相同字符 } } 根据回溯算法的代码实现,我们可以画出递归树,看是否存在重复子问题。如果存在重复子问题,那我们就可以考虑是否能用动态规划来解决;如果不存在重复子问题,那回溯就是最好的解决方法。
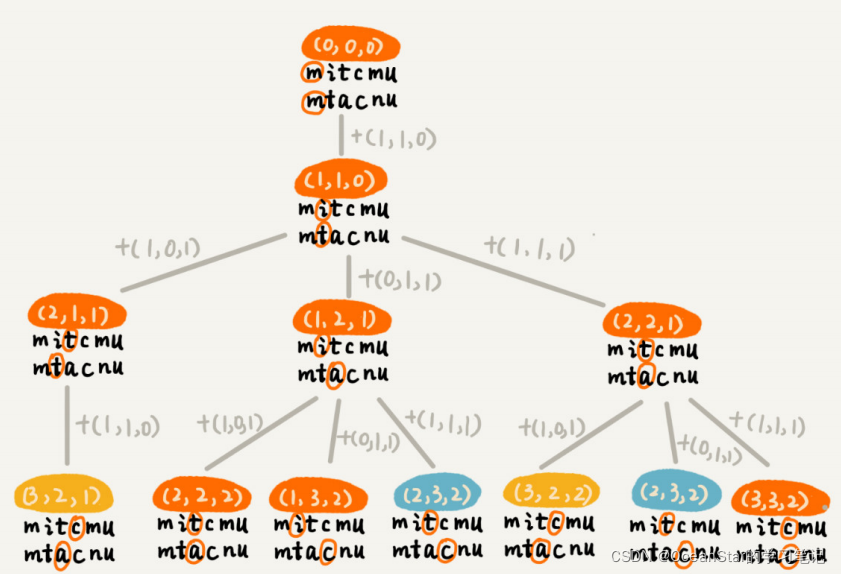
在递归树中, ( i , j ) (i,j) (i,j)两个变量重复的节点很多,比如 ( 3 , 2 ) (3,2) (3,2)和 ( 2 , 3 ) (2,3) (2,3)。对于 ( i , j ) (i,j) (i,j)相同的节点,我们只需要考虑保留edist最小的,继续递归处理就可以了,剩下的节点都可以舍弃。所以,状态就从 ( i , j , e d i s t ) (i,j,edist) (i,j,edist)变成了 ( i , j , m i n d i s t ) (i,j,mindist) (i,j,mindist),其中mindist表示处理到 a [ i ] a[i] a[i]和 b [ j ] b[j] b[j],已经执行的最少编辑次数。
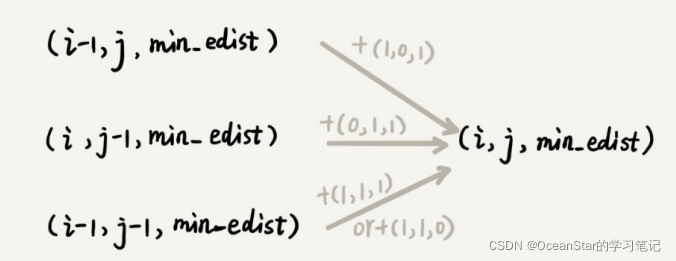
这里的动态递归跟很相似,在矩阵最短路径中,到达状态(i,j)只能通过(i-1,j)或者(i,j-1)两个状态转移过来,而字符编辑距离状态(i,j)可能从(i-1,j),(i,j-1),(i-1,j-1)三个状态中的任意一个转移过来。
转载地址:https://blog.csdn.net/zhizhengguan/article/details/122762793 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
