本文共 7289 字,大约阅读时间需要 24 分钟。
BM算法是一种非常高效的字符串匹配算法,它的性能是著名的KMP 算法的 3 到 4 倍。
核心思想
我们把模式串和主串的匹配过程,看作模式串在主串中不停的往后滑动。当遇到不匹配的字符时,BF算法和RK算法的做法是,模式串往后滑动一位,然后从模式串的第一个字符开始重新匹配。如下图:
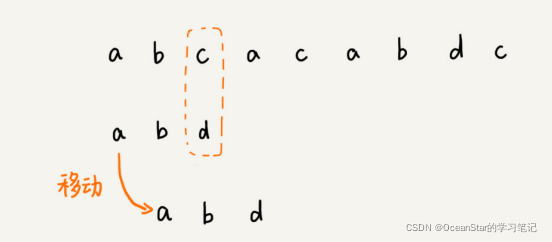 在上面例子中,主串中的c,在模式串中是不存在的,所以,模式串往后滑动的时候,只要c与模式串有重合,肯定无法匹配。所以,我们可以一次性的把模式串往后多滑动几位,把模式串移动到c的后面。
在上面例子中,主串中的c,在模式串中是不存在的,所以,模式串往后滑动的时候,只要c与模式串有重合,肯定无法匹配。所以,我们可以一次性的把模式串往后多滑动几位,把模式串移动到c的后面。 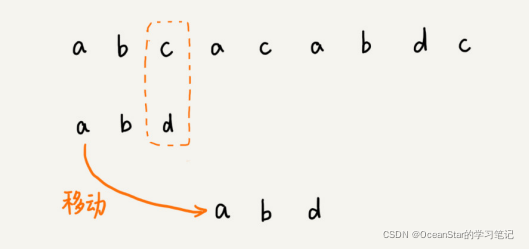 那当遇到不匹配的字符时,到底应该将模式串往后滑动几位呢?BM算法,本质上就是在寻找这种规律,借助这种规律,在模式串与字符串匹配的过程中,当模式串与主串某个字符不匹配的时候,能够跳过一些肯定不会匹配的情况,将模式串往后多滑动几位。
那当遇到不匹配的字符时,到底应该将模式串往后滑动几位呢?BM算法,本质上就是在寻找这种规律,借助这种规律,在模式串与字符串匹配的过程中,当模式串与主串某个字符不匹配的时候,能够跳过一些肯定不会匹配的情况,将模式串往后多滑动几位。 原理分析
BM 算法包含两部分,分别是坏字符规则(bad character rule)和好后缀规则(goodsuffix shift)。
坏字符规则
BF算法和RK算法,在匹配的过程中,我们都是按照模式串的下标从小到大的顺序,依次与主串中的字符进行匹配的。这种匹配规则比较符合我们的思维习惯,而BM算法的匹配顺序比较特别,它是按照模式串下标从大到小的顺序,倒着匹配的。如下图:
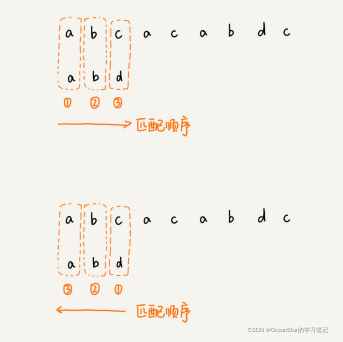 我们从模式串的末尾往前倒着匹配,当我们发现某个字符没法匹配的时候,我们把这个没有匹配的字符串叫做坏匹配(主串中的字符)
我们从模式串的末尾往前倒着匹配,当我们发现某个字符没法匹配的时候,我们把这个没有匹配的字符串叫做坏匹配(主串中的字符) 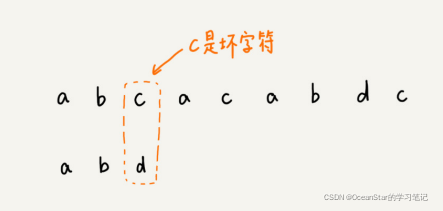
我们拿坏字符串c在模式串中查找,发现模式串中并不存在这个字符,也就是说,字符c与模式串中的任何字符都不可能匹配。这个时候,我们可以将模式串直接往后滑动三位,将模式串滑动到c后面的位置,再从模式串的末尾字符开始比较。
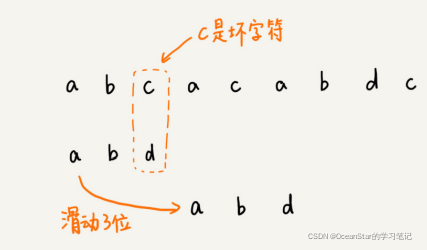
这个时候,我们发现,模式串中最后一个字符 d,还是无法跟主串中的 a 匹配,这个时候,还能将模式串往后滑动三位吗?答案是不行的。因为这个时候,坏字符 a 在模式串中是存在的,模式串中下标是 0 的位置也是字符 a。这种情况下,我们可以将模式串往后滑动两位,让两个 a 上下对齐,然后再从模式串的末尾字符开始,重新匹配。
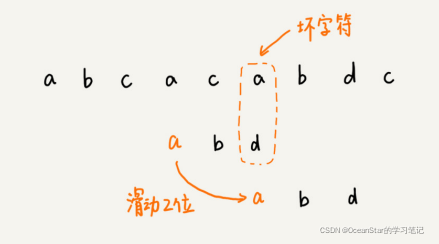
第一次不匹配的时候,我们滑动了三位,第二次不匹配的时候,我们将模式串后移两位,那具体滑动多少位,到底有没有规律呢?
当发生不匹配的时候,我们把坏字符对应的模式串中的字符下标记作 s i si si。如果坏字符在模式串中存在,我们把这个坏字符在模式串中的下标记作 x i xi xi。如果不存在,我们把 x i xi xi记作-1。那模式串往后移动的位数就等于 s i − x i si-xi si−xi(注意,这里说的下标,都是字符在模式串的下标)
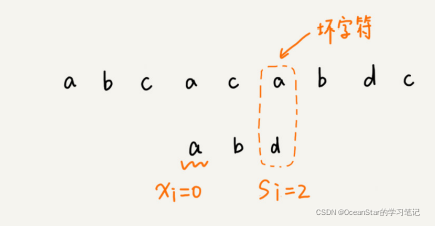
利用坏字符规则,BM算法在最好情况下的时间复杂度非常低,是O(n/m)。比如,主串是aaabaaabaaabaaab,模式串是 aaaa。每次比对,模式串都可以直接后移四位,所以,匹配具有类似特点的模式串和主从的时候,BM算法非常高效。
不过,单纯使用坏字符规则还是不够的。因为根据 s i − x i si-xi si−xi计算出来的移动位数,有可能是负数,比如aaaaaaaaaaaaaaaa,模式串是 baaa,不但不会向后滑动模式串,还有可能倒退。所以,BM算法还需要“好后缀规则”
好后缀规则
好后缀规则实际上跟坏字符规则的思路很类似。如下图,当模式串滑动到图中的位置的时候,模式串和主串有2个字符是匹配的,倒数第3个字符发生了不匹配的情况。
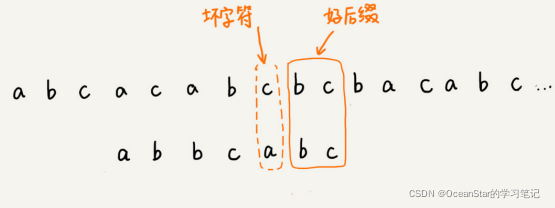
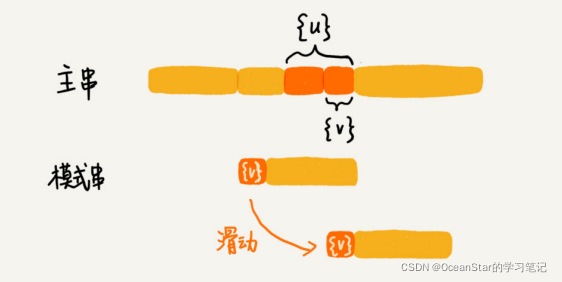
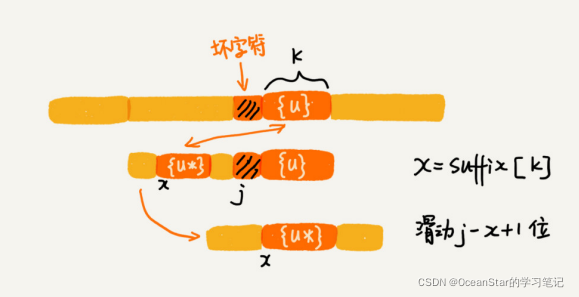
我们把已经匹配的bc叫做好后缀,记作{u}。我们拿它在模式串中查找,如果找到了另一个跟{u}相匹配的子串{u*},那我们就将模式串滑动到子串{u*}与主串中{u}对齐的位置。
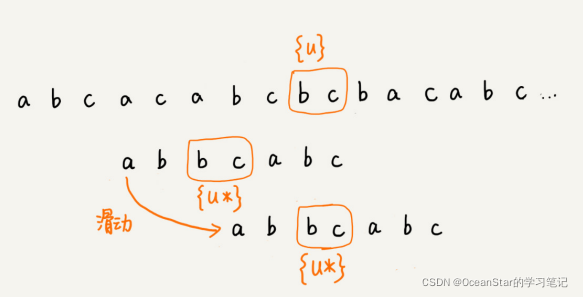
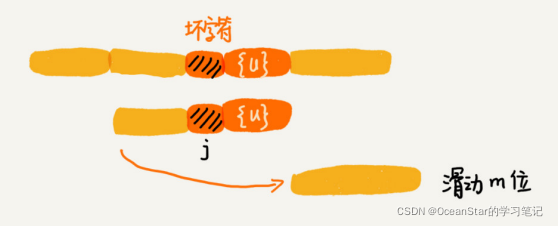
如果在模式串中找不到另一个等于{u}的子串,我们就直接将模式串,滑动到主串中{u}的后面,因为之前的任何一次往后滑动,都没有匹配主串中{u}的情况。
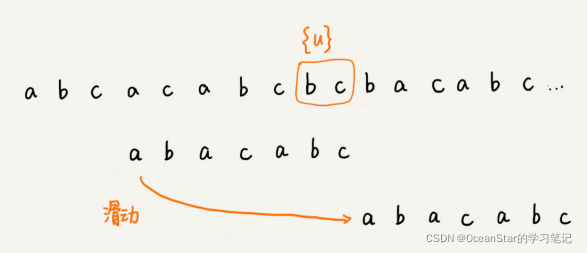
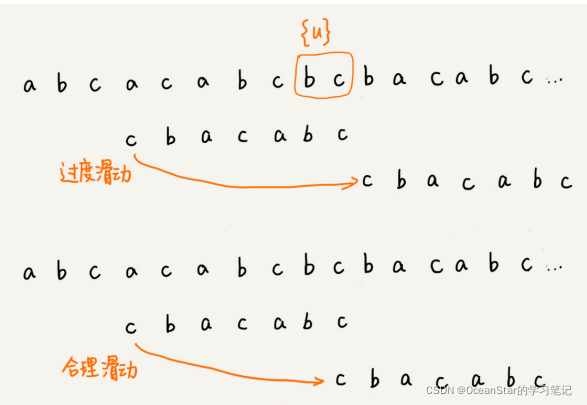
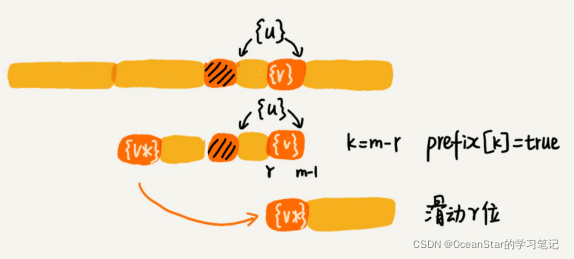
所谓某个字符串s的后缀子串,就是最后一个字符跟s对齐的子串,比如abc的后缀子串就包含c、bc。所谓前缀子串,就是起始字符跟s对齐的子串,比如abc的前缀子串有a,ab。我们从好后缀的后缀子串中,找一个最长的并且能够跟模式串的前缀子串匹配的,假设是{v},然后将模式串滑动到如图所示的位置。
如何抉择
当模式串和主串中的某个字符不匹配的时候,如何选择用好后缀规则还是坏字符规则,来计算模式串往后滑动的位数?
我们可以分别计算好后缀和坏字符往后滑动的位数,然后取两个数中最大的,作为模式串往后滑动的位数。这种处理方法还可以避免我们前面提到的,根据坏字符规则,计算得到的往后滑动的位数,有可能是负数的情况。
代码实现
“坏字符规则”:当遇到坏字符的时候,要计算往后移动的位数si-xi,其中xi的计算是重点,我们如何求得xi呢?或者说,如何查找坏字符在模式串中出现的位置呢?
如果我们拿到坏字符,在模式串中顺序遍历查找,这样就会比较低效,势必影响这个算法的性能。有没有更高效的方式呢?我们可以将模式串中每个字符以及其下标都存储在散列表中。这样就可以快速找到坏字符在模式串的位置下标了。
关于这个散列表,我们只实现一种最简单的情况,假设字符串的字符集不是很大,并且每个字符长度是1字符串,我们用大小为256的数组,来记录每个字符在模式串中出现的位置。数组的下标对应字符的ASCII码值,数组中存储这个字符在模式串中出现的位置。
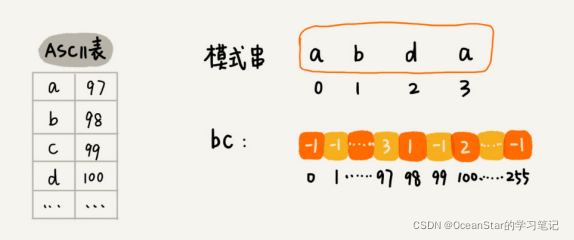 具体实现如下。其中,变量b是模式串,m是模式串的长度,bc是散列表
具体实现如下。其中,变量b是模式串,m是模式串的长度,bc是散列表 private static final int SIZE = 256; private void generateBC(char []b, int m, int []bc){ for (int i = 0; i < SIZE; i++) { bc[i] = -1; } for (int i = 0; i < m; i++) { int ascii = (int)b[i];// 计算b[i]的ASCII码值 bc[ascii] = i; } } 我们先把BM算法代码的大框架写好,先不考虑好后缀规则,仅用坏字符规则,并且不考虑 si-xi 计算得到的移动位数可能会出现负数的情况。
/* * @param a 主串 * @param n 主串长度 * @param b 模式串 * @param m 模式串长度 * @return int * */ public int bm(int []a, int n, char [] b, int m){ int[] bc = new int[SIZE]; //记录模式串中每个字符最后出现的位置 generateBC(b, m, bc); // 构造坏字符哈希表 int i = 0; // i表示主串与模式串对齐的第一个字符 while (i <= n - m){ int j; for (j = m - 1; j >= 0; --j) { //模式串从后往前匹配 if(a[i + j] != b[j]){ break; // 坏字符对应模式串中的下标是j } } if(j < 0){ return i; //匹配成功,返回主串与模式串中第一个匹配的字符的位置 } // 这里等同于将模式串往后滑动 j - bc[(int)a[i+j]]位 i = i + (j - bc[(int)a[i+j]]); } return -1; } 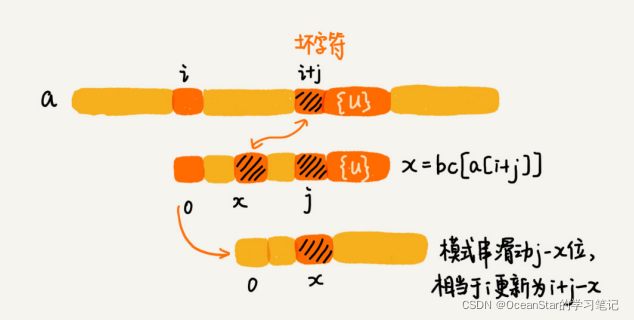
- 在模式串中,查找跟好后缀匹配的另一个子串
- 在好后缀的后缀子串中,查找最长的,能够跟模式串前缀子串匹配的后缀子串
在不考虑效率的情况下,这两个操作都可以用很“暴力”的匹配查找方式解决。但是,如果想要 BM 算法的效率很高,这部分就不能太低效。如何来做呢?
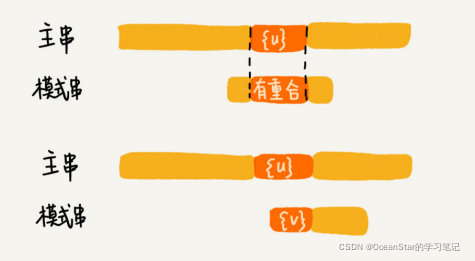
因为好后缀也是模式串本身的后缀子串,所以,我们可以在模式串和主串正式匹配之前,通过预处理模式串,预先计算好模式串中的每个后缀子串,对应的另一个可匹配子串的位置。
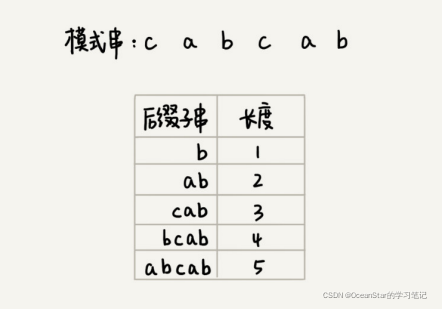
那,如果表示模式串中不同的后缀子串呢?因为后缀子串的最后一个字符的位置是固定的,下标为m-1,我们只需要记录长度就可以了。通过长度,我们可以确定一个唯一的后缀子串
下面开始不理解了,待研究
现在,我们要引入最关键的变量suffix数组。suffix数组的下标k,表示后缀子串的长度,下标对应的数组值存储的是,在模式串中跟好后缀{u}相匹配的子串{u*}的起始下标值。举个例子。

但是,如果模式串中有多个(大于 1 个)子串跟后缀子串{u}匹配,那 suffix 数组中该存储哪一个子串的起始位置呢?为了避免模式串往后滑动得过头了,我们肯定要存储模式串中最靠后的那个子串的起始位置,也就是下标最大的那个子串的起始位置。不过,这样处理就足够了吗?
实际上,仅仅是选最靠后的子串片段来存储是不够的。我们再回忆一下好后缀规则。
我们不仅要在模式串中,查找跟好后缀匹配的另一个子串,还要在好后缀的后缀子串中,查找最长的能够跟模式串前缀子串匹配的后缀子串。
如果我们只记录刚刚定义的 suffix,实际上,只能处理规则的前半部分,也就是,在模式串中,查找跟好后缀匹配的另一个子串。所以,除了 suffix 数组之外,我们还需要另外一个boolean 类型的 prefix 数组,来记录模式串的后缀子串是否能匹配模式串的前缀子串。

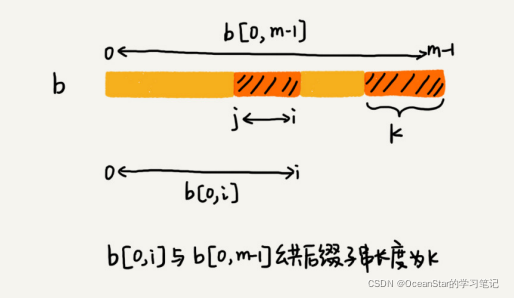
- 我们拿下标从 0 到 i 的子串(i 可以是 0 到 m-2)与整个模式串,求公共后缀子串。
- 如果公共后缀子串的长度是 k,那我们就记录 suffix[k]=j(j 表示公共后缀子串的起始下标)。
- 如果 j 等于 0,也就是说,公共后缀子串也是模式串的前缀子串,我们就记录prefix[k]=true。
// b 表示模式串,m 表示长度,suffix,prefix 数组事先申请好了private void generateGS(char[] b, int m, int[] suffix, boolean[] prefix) { for (int i = 0; i < m; ++i) { // 初始化 suffix[i] = -1; prefix[i] = false; } for (int i = 0; i < m - 1; ++i) { // b[0, i] int j = i; int k = 0; // 公共后缀子串长度 while (j >= 0 && b[j] == b[m-1-k]) { // 与 b[0, m-1] 求公共后缀子串 --j; ++k; suffix[k] = j+1; //j+1 表示公共后缀子串在 b[0, i] 中的起始下标 } if (j == -1) prefix[k] = true; // 如果公共后缀子串也是模式串的前缀子串 }} 有了这两个数组之后,我们现在来看,在模式串跟主串匹配的过程中,遇到不能匹配的字符时,如何根据好后缀规则,计算模式串往后滑动的位数?
假设好后缀的长度是 k。我们先拿好后缀,在 suffix 数组中查找其匹配的子串。如果suffix[k] 不等于 -1(-1 表示不存在匹配的子串),那我们就将模式串往后移动 jsuffix[k]+1 位(j 表示坏字符对应的模式串中的字符下标)。如果 suffix[k] 等于 -1,表示模式串中不存在另一个跟好后缀匹配的子串片段。我们可以用下面这条规则来处理。
// a,b 表示主串和模式串;n,m 表示主串和模式串的长度。public int bm(char[] a, int n, char[] b, int m) { int[] bc = new int[SIZE]; // 记录模式串中每个字符最后出现的位置 generateBC(b, m, bc); // 构建坏字符哈希表 int[] suffix = new int[m]; boolean[] prefix = new boolean[m]; generateGS(b, m, suffix, prefix); int i = 0; // j 表示主串与模式串匹配的第一个字符 while (i <= n - m) { int j; for (j = m - 1; j >= 0; --j) { // 模式串从后往前匹配 if (a[i+j] != b[j]) break; // 坏字符对应模式串中的下标是 j } if (j < 0) { return i; // 匹配成功,返回主串与模式串第一个匹配的字符的位置 } int x = j - bc[(int)a[i+j]]; int y = 0; if (j < m-1) { // 如果有好后缀的话 y = moveByGS(j, m, suffix, prefix); } i = i + Math.max(x, y); } return -1;}// j 表示坏字符对应的模式串中的字符下标 ; m 表示模式串长度private int moveByGS(int j, int m, int[] suffix, boolean[] prefix) { int k = m - 1 - j; // 好后缀长度 if (suffix[k] != -1) return j - suffix[k] +1; for (int r = j+2; r <= m-1; ++r) { if (prefix[m-r] == true) { return r; } } return m;} BM 算法的性能分析及优化
我们先来分析 BM 算法的内存消耗。整个算法用到了额外的 3 个数组,其中 bc 数组的大小跟字符集大小有关,suffix 数组和 prefix 数组的大小跟模式串长度 m 有关。
如果我们处理字符集很大的字符串匹配问题,bc 数组对内存的消耗就会比较多。因为好后缀和坏字符规则是独立的,如果我们运行的环境对内存要求苛刻,可以只使用好后缀规则,不使用坏字符规则,这样就可以避免 bc 数组过多的内存消耗。不过,单纯使用好后缀规则的 BM 算法效率就会下降一些了。
对于执行效率来说,我们可以先从时间复杂度的角度来分析。基于上面的BM初级版本,在极端情况下,预处理计算 suffix 数组、prefix 数组的性能会比较差。比如模式串是 aaaaaaa 这种包含很多重复的字符的模式串,预处理的时间复杂度就是O(m^2)。当然,大部分情况下,时间复杂度不会这么差
小结
BM算法的核心思想是,利用模式串本身的特点,在模式串中某个字符与主串不能匹配的时候,将模式串往后多滑动几位,以此来减少不必要的字符比较,提高匹配的效率。BM算法构建规则有两类,坏字符规则和好后缀规则。好后缀规则可以独立于坏字符规则使用。因为坏字符规则的实现比较耗内存,为了节省内存,我们可以只用好字符规则来实现BM算法
转载地址:https://blog.csdn.net/zhizhengguan/article/details/122662006 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
