本文共 4224 字,大约阅读时间需要 14 分钟。
深度优先搜索
深度优化遍历( Depth First Search ),也有称为 深度优化搜索 ,简称为 DFS 。为了讲清楚DFS,我们先来看两个概念
- 右手原则: 在没有碰到重复顶点的情况下,分叉路口始终是向右手边走,每路过一个顶点就做一个记号
- 左手原则: 在没有碰到重复顶点的情况下,分叉路口始终是向左手边走,每路过一个顶点就做一个记号
下文以右手原则进行深度优先遍历。
图解
以下图为例说明深度优先搜索
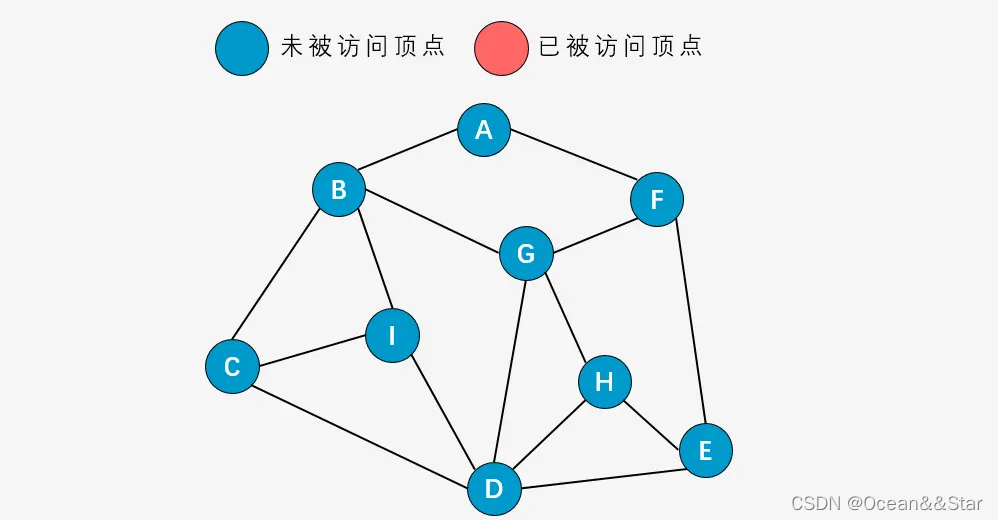
- 第一步:从顶点A开始,将顶点A标记为已访问节点
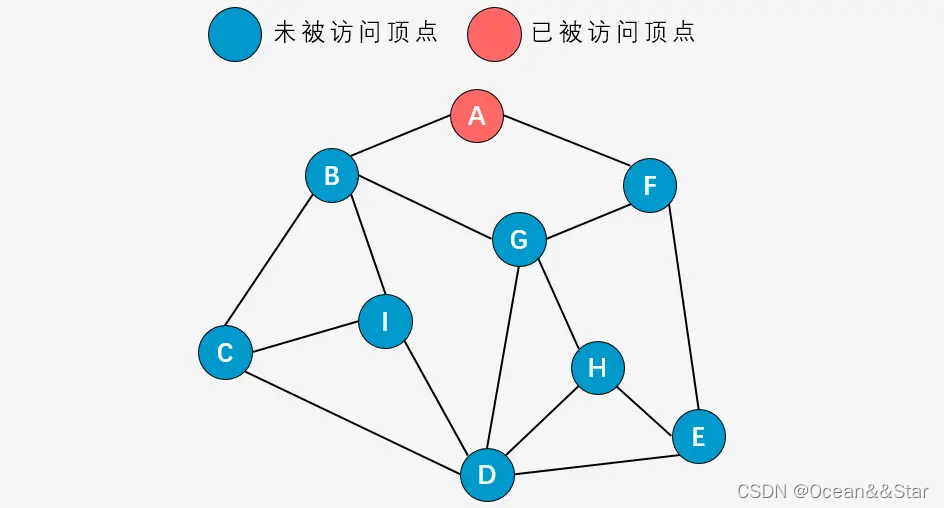
- 第二步:根据右手原则,访问顶点B,并将B标记为已访问节点
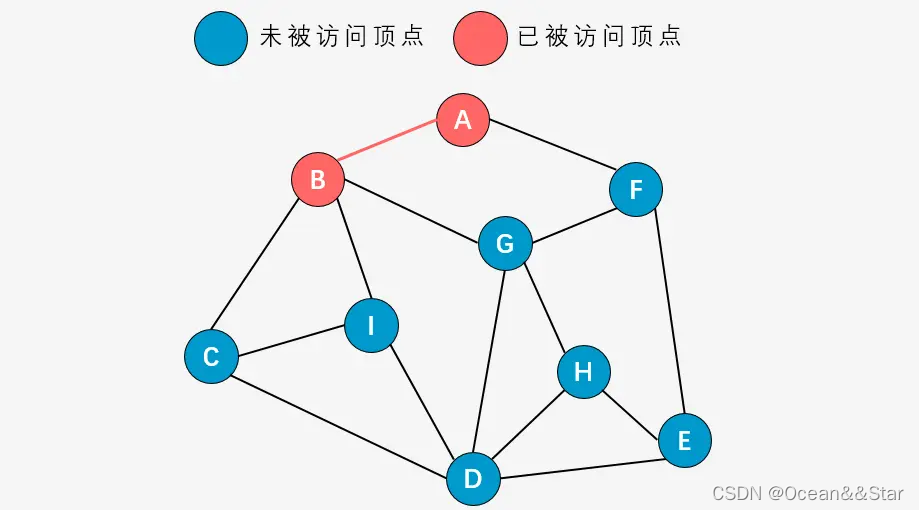
- 第三步:右手原则,访问顶点C

- 第四步:右手原则,访问顶点D
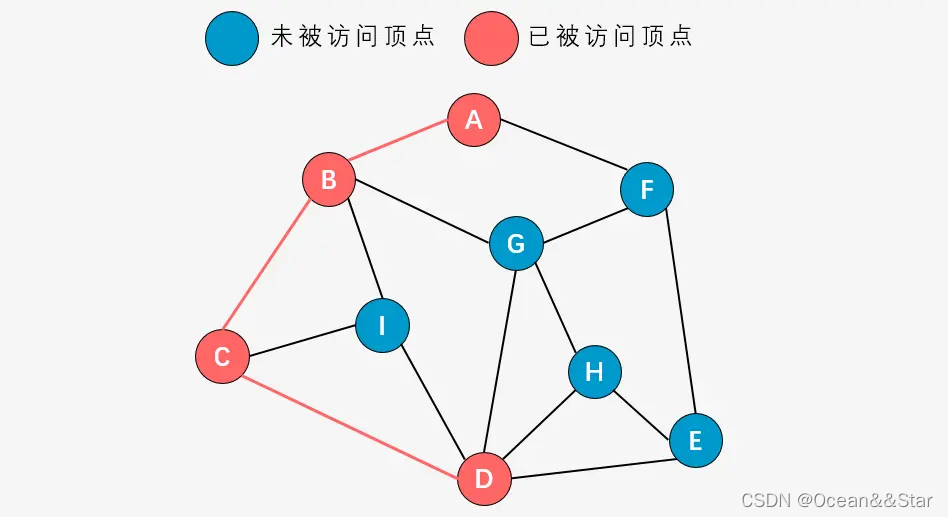
- 第五步:右手原则,访问顶点E
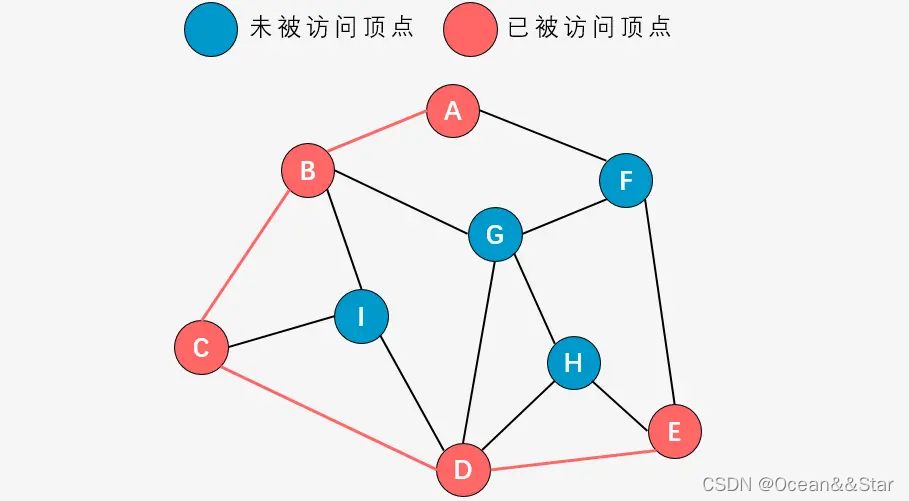
- 第六步:右手原则,访问顶点F
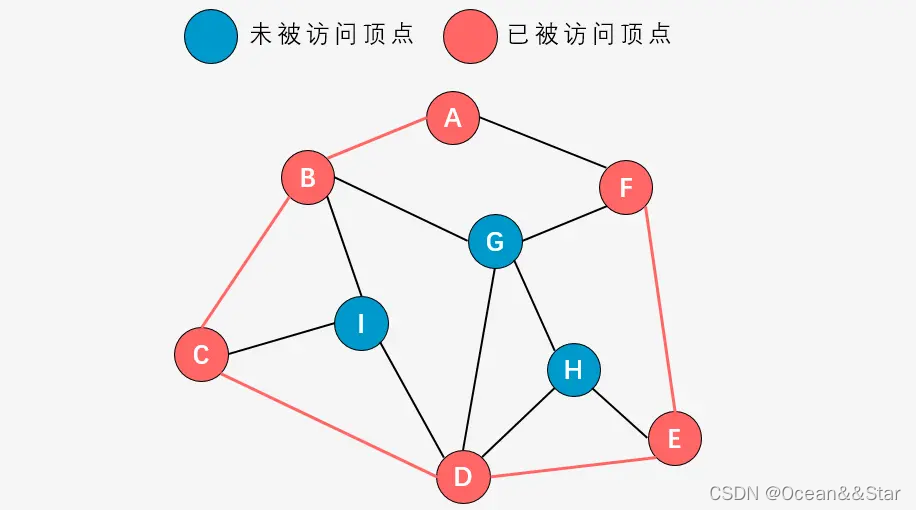
-
第七步:右手原则,应该先访问顶点F的邻接顶点A,但发现A已经被访问,则访问A之外的最右侧顶点G
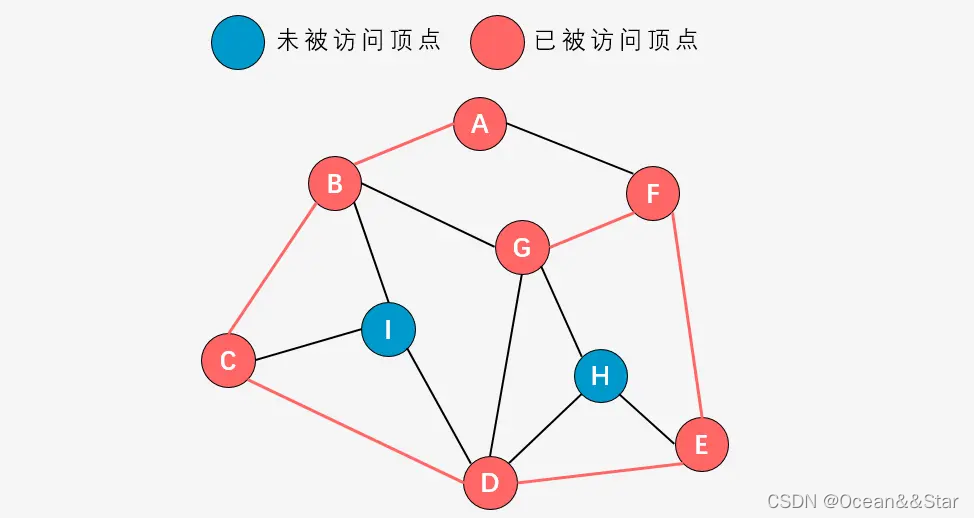
-
第八步:右手原则,先访问顶点B,顶点B已经被访问;在访问顶点D,顶点D已经被访问;最后访问顶点H
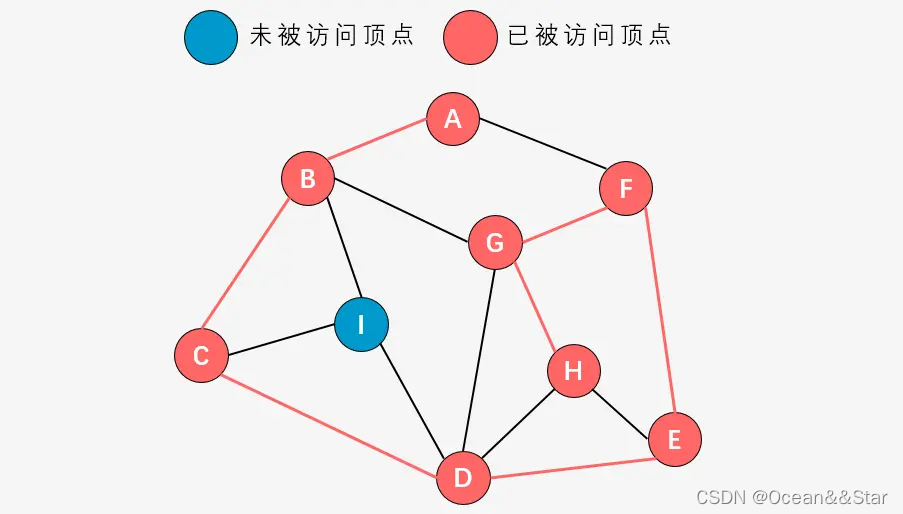
-
第九步:发现顶点H的邻接顶点均已被访问,则退回到顶点G;
-
第十步:顶点G的邻接顶点均已被访问,则退回到顶点F;
-
第十一步:顶点F的邻接顶点已被访问,则退回到顶点E;
-
第十二步:顶点E的邻接顶点均已被访问,则退回到顶点D;
-
第十三步:顶点D的邻接顶点I尚未被访问,则访问顶点I;
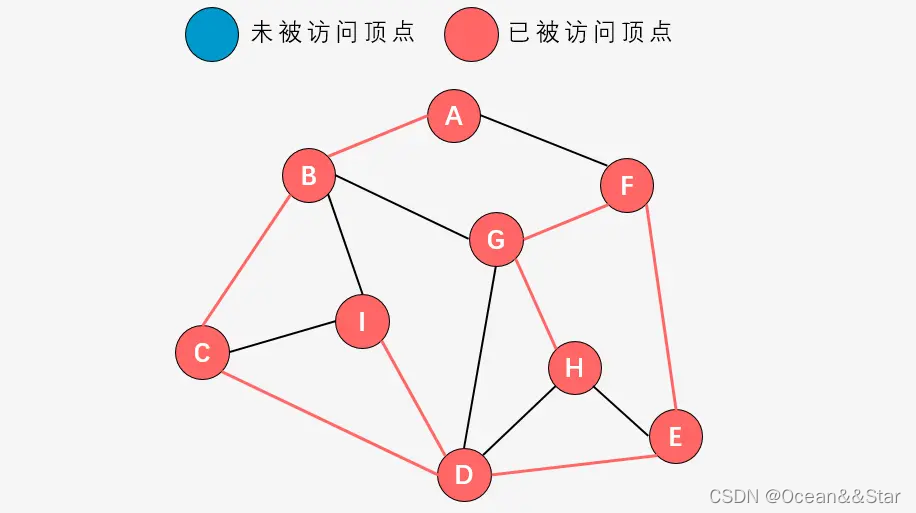
-
第十四步:顶点I的邻接顶点均已被访问,则退回到顶点D;
顶点D的邻接顶点均已被访问,退回到顶点C;顶点C的邻接顶点均已被访问,则退回到顶点B;顶点B的邻接顶点均已被访问,则退回到顶点A,顶点A为起始顶点,深度优先搜索结束。
图的深度优先搜索和二叉树的前序遍历、中序遍历、后序遍历本质上均属于一类方法。
上面的过程可以总结为以下3个步骤:
(1)首先选定一个未被访问过的顶点V作为起始顶点(或者访问指定的起始顶点V),并将其标记为已访问
(2)然后搜索与顶点V邻接的所有顶点,判断这些顶点是否被访问过,如果有未被访问过的顶点W;再选取与顶点W邻接的未被访问过的一个顶点并进行访问,依次重复进行。当一个顶点的所有的邻接顶点都被访问过时,则依次回退到最近被访问的顶点。若该顶点还有其他邻接顶点未被访问,则从这些未被访问的顶点中取出一个并重复上述过程,直到与起始顶点V相邻接的所有顶点都被访问过为止。
(3)若此时图中依然有顶点未被访问,则再选取其中一个顶点作为起始顶点并进行遍历,转(2)。反之,则遍历结束。
实现
当图采用邻接矩阵进行存储,递归的实现操作:
#define MAXVBA 100#define INFINITY 65536typedef struct { char vexs[MAXVBA]; int arc[MAXVBA][MAXVBA]; int numVertexes, numEdges;} MGraph;// 邻接矩阵的深度有限递归算法#define TRUE 1#define FALSE 0#define MAX 256typedef int Boolean; // 这里我们定义Boolean为布尔类型,其值为TRUE或FALSEBoolean visited[MAX]; // 访问标志的数组void DFS(MGraph G, int i){ visited[i] = TRUE; printf("%c", G.vexs[i]); for (int j = 0; j < G.numVertexes; ++j) { if (G.arc[i][j] == 1 && !visited[j]){ DFS(G, j); // 对为访问的邻接顶点递归调用 } }}// 邻接矩阵的深度遍历操作void DFSTraverse(MGraph G){ int i; // 初始化所有顶点状态都是未访问过状态 for (i = 0; i < G.numVertexes; ++i) { visited[i] = FALSE; } //防止图为非联通的情况,遍历整个图 for (i = 0; i < G.numVertexes; ++i) { if (!visited[i]){ // 若是连通图,只会执行一次 DFS(G, i); } }} 当图采用邻接矩阵进行存储,栈的实现操作:
void DFS_Stack(MGraph G, int i){ int node; int count = 1; printf("%c ", G.vexs[i]); // 打印已访问顶点 visited[i] = TRUE; node = i; push(i); //开始的节点入栈 while(count < G.numVertexes) //still has node not visited { /* 所有被访问的节点依次入栈,只有node当找不到下一个相连的节点时,才使用出栈节点 */ for(j=0; j < G.numVertexes; j++) { if(G.arc[node][j] == 1 && visited[j] == FALSE) { visited[j] = TRUE; printf("%c ", G.vexs[j]); count++; push(j); //push node j break; } } if(j == G.numVertexes) //与node相连的顶点均已被访问过,所以需要从stack里取出node的上一个顶点,再看该顶点的邻接顶点是否未被访问 node = pop(); else //找到与node相连并且未被访问的顶点, node = j; }} 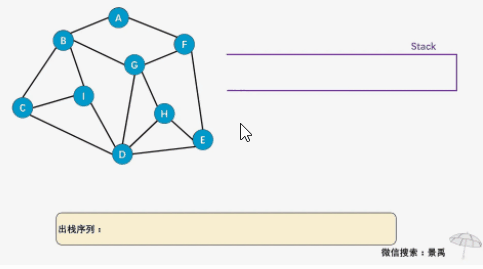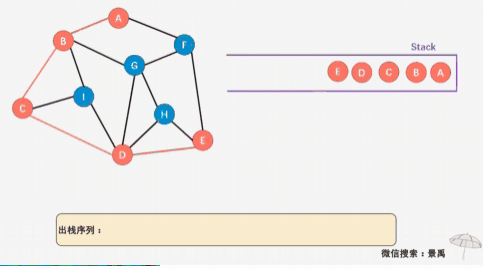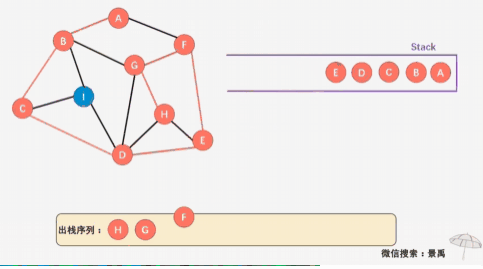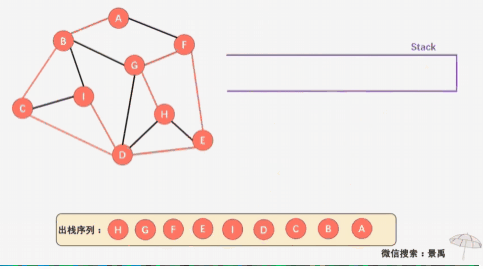
// 邻接表的深度有限递归算法#define TRUE 1#define FALSE 0#define MAX 256typedef int Boolean; // 这里我们定义Boolean为布尔类型,其值为TRUE或FALSEBoolean visited[MAX]; // 访问标志的数组void DFS(GraphAdjList GL, int i){ EdgeNode *p; visited[i] = TRUE; printf("%c " GL->adjList[i].data); p = GL->adjList[i].firstEdge; while(p) { if( !visited[p->adjvex] ) { DFS(GL, p->adjvex); } p = p->next; }}// 邻接表的深度遍历操作void DFSTraverse(GraphAdjList GL){ int i; for( i=0; i < GL->numVertexes; i++ ) { visited[i] = FALSE; // 初始化所有顶点状态都是未访问过状态 } for( i=0; i < GL->numVertexes; i++ ) { if( !visited[i] ) // 若是连通图,只会执行一次 { DFS(GL, i); } }} 广度优先算法
图解
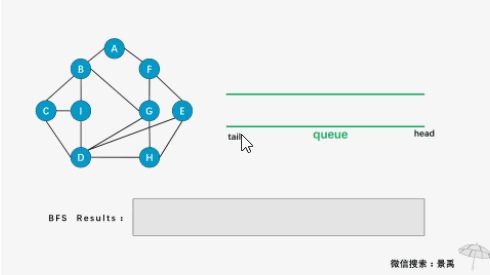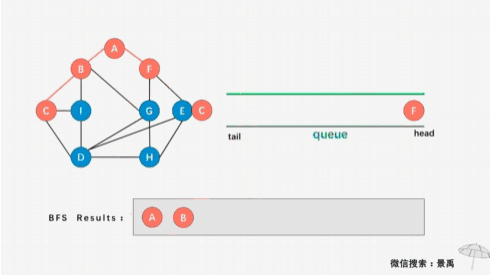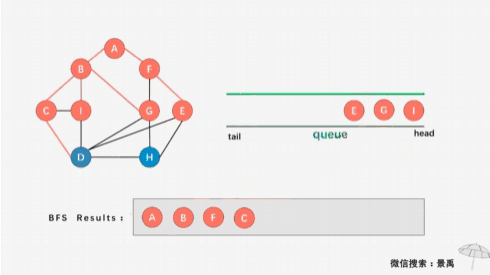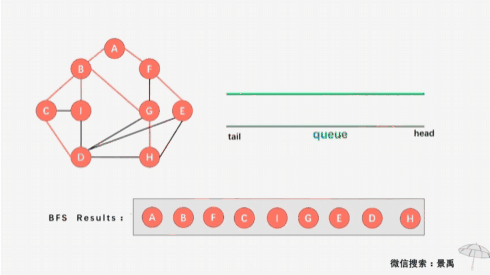
广度优先遍历(Breadth First Search),又称为广度优先搜索,简称BFS。树的层序遍历方式便是一种广度优先搜索方式。为了清晰地理解广度优先搜索,我们同样以深度优先搜索的例子一起走一遍,这不过,我们对图中顶点的位置做了调整,这样看起来更清楚。
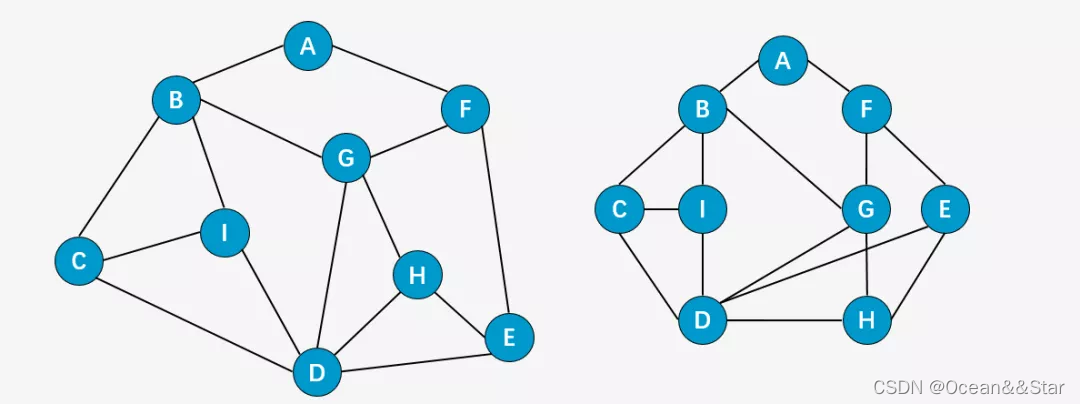
- 第一步:访问顶点A;
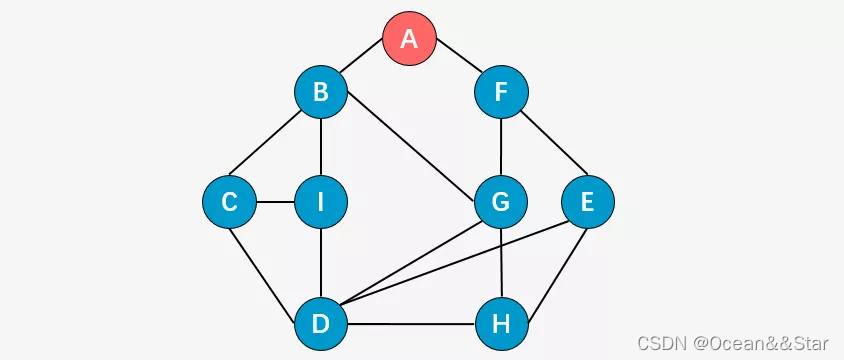
- 第二步:访问顶点A的所有未被访问的邻接顶点,顶点B和顶点F;
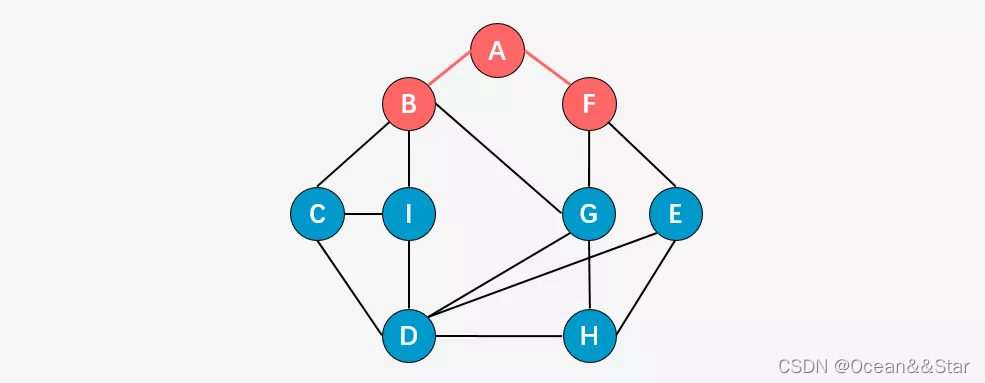
- 第三步:访问顶点B和顶点F的所有未被访问的邻接顶点,顶点C、I、G、E;
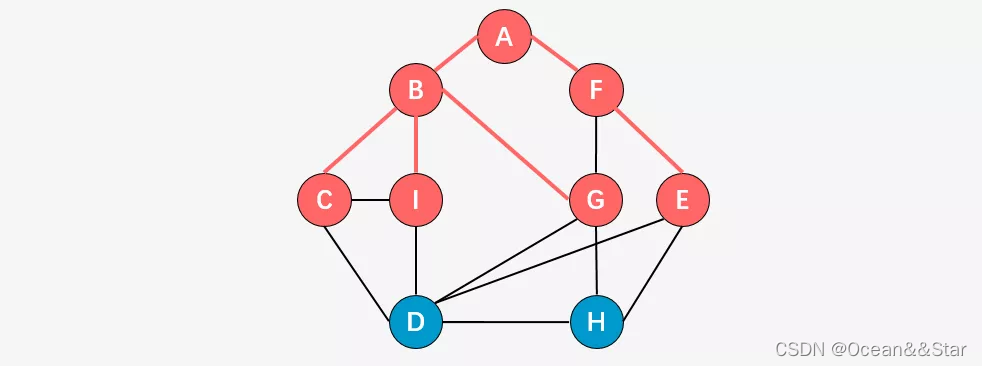
- 第四步:访问顶点C、I、G、E 的所有邻接顶点中未被访问的顶点,顶点D和顶点H。
实现
// 邻接矩阵的广度遍历算法void BFSTraverse(MGraph G){ int i, j; Queue Q; for( i=0; i < G.numVertexes; i++ ) { visited[i] = FALSE; } initQueue( &Q ); for( i=0; i < G.numVertexes; i++ ) { if( !visited[i] ) { printf("%c ", G.vex[i]); visited[i] = TRUE; EnQueue(&Q, i); while( !QueueEmpty(Q) ) { DeQueue(&Q, &i); for( j=0; j < G.numVertexes; j++ ) { if( G.art[i][j]==1 && !visited[j] ) { printf("%c ", G.vex[j]); visited[j] = TRUE; EnQueue(&Q, j); } } } } }} 转载地址:https://blog.csdn.net/zhizhengguan/article/details/122476848 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
