**Python爬虫使用mysql数据库存储*
 登录mysql,那串星星一样的东西就是上面标记出来的临时密码。
登录mysql,那串星星一样的东西就是上面标记出来的临时密码。  登录MySQL后,使用命令ALTER USER USER() IDENTIFIED BY ‘root’;更改密码,我把密码改成了‘root’。
登录MySQL后,使用命令ALTER USER USER() IDENTIFIED BY ‘root’;更改密码,我把密码改成了‘root’。  登录后创建一个叫 ‘pachong’ 的数据库 ,mysql>create database pachong;
登录后创建一个叫 ‘pachong’ 的数据库 ,mysql>create database pachong;  搞定数据库后,我们就开始编写爬虫代码了,因为我们要把爬取到的数据存储在数据库中,所以在编写代码之前我们先在数据库里创建一个 ‘doubanmovie’ 的表,注意这里是严格区分大小写的。
搞定数据库后,我们就开始编写爬虫代码了,因为我们要把爬取到的数据存储在数据库中,所以在编写代码之前我们先在数据库里创建一个 ‘doubanmovie’ 的表,注意这里是严格区分大小写的。 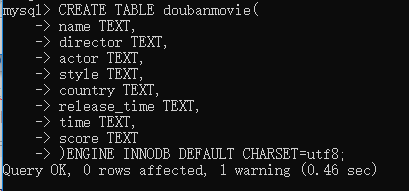 然后再看看我们的小海豚,我们已经在数据库pachong下建立了一个doubanmovie的表了。
然后再看看我们的小海豚,我们已经在数据库pachong下建立了一个doubanmovie的表了。 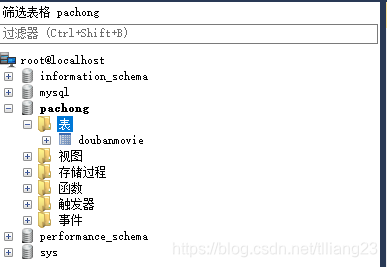 下面开始我们的爬虫代码
下面开始我们的爬虫代码 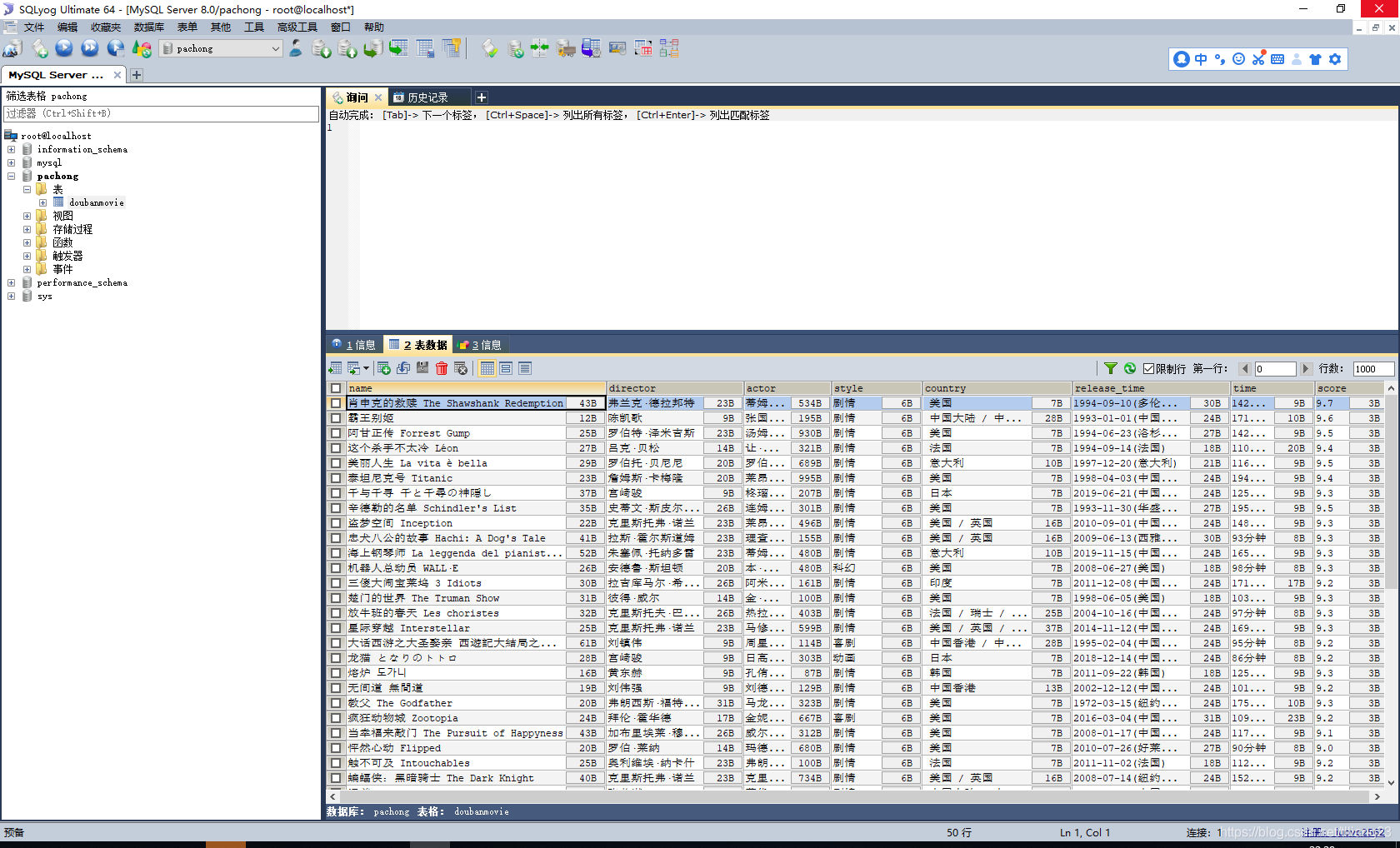 第一次发文章,可能有不足之处,请大家谅解
第一次发文章,可能有不足之处,请大家谅解
发布日期:2022-02-26 00:17:40
浏览次数:9
分类:技术文章
本文共 3016 字,大约阅读时间需要 10 分钟。
Python爬虫使用mysql数据库存储
爬取豆瓣top250电影
我的系统是win10 + Python3.7
首先,我们需要下载一个mysql数据库 数据库下载地址是: https://cdn.mysql.com//Downloads/MySQL-8.0/mysql-8.0.18-winx64.zip 下载完成后,解压之后的内容: 我们把解压之后目录下的所有文件复制到这里:
我们发现多了一个my.ini的文件,这是自己编写的
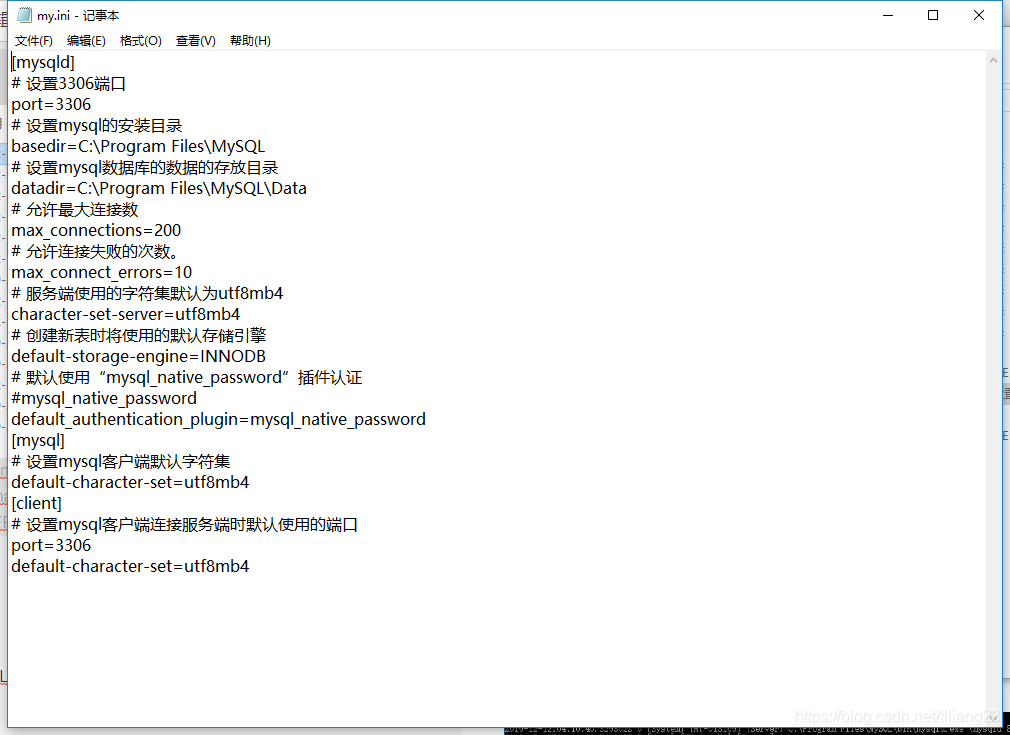
以管理员身份运行cmd,运行mysqld --initialize --console,记住root@localhost:后面标记出来的一串代码,这是登录mysql数据库的临时密码,然后net start mysql启动mysql服务。
登录mysql,那串星星一样的东西就是上面标记出来的临时密码。 登录MySQL后,使用命令ALTER USER USER() IDENTIFIED BY ‘root’;更改密码,我把密码改成了‘root’。 登录后创建一个叫 ‘pachong’ 的数据库 ,mysql>create database pachong; 再下载个“小海豚“:
http://forspeed.onlinedown.net/down/Webyog-SQLyog-Ultimate12.0.8.0.zip 输入密码‘root’连接,就可以可视化了,可以看见我们新建的pachong数据库了 搞定数据库后,我们就开始编写爬虫代码了,因为我们要把爬取到的数据存储在数据库中,所以在编写代码之前我们先在数据库里创建一个 ‘doubanmovie’ 的表,注意这里是严格区分大小写的。 然后再看看我们的小海豚,我们已经在数据库pachong下建立了一个doubanmovie的表了。 下面开始我们的爬虫代码 ‘’‘导入我们需要的包’‘’
import re import pymysql import requests from lxml import etreeconn = pymysql.connect(host=‘localhost’, user=‘root’, passwd=‘root’, db=‘pachong’, port=3306, charset=‘utf8’)
‘’‘初始化数据库对象conn’‘’ cursor = conn.cursor() # 定义光标对象headers = {
‘User-Agent’: ‘Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36’ ’ (KHTML, like Gecko) Chrome/69.0.3947.100 Safari/537.36’ }def get_movie_url(url):
html = requests.get(url, headers=headers) selector = etree.HTML(html.text) movie_hrefs = selector.xpath("//div[@class=‘hd’]/a/@href") print(movie_hrefs) for movie_href in movie_hrefs: get_movie_info(movie_href)def get_movie_info(url):
html = requests.get(url, headers=headers) selector = etree.HTML(html.text) try: name = selector.xpath(’//[@id=“content”]/h1/span[1]/text()’)[0] director = selector.xpath(’//[@id=“info”]/span[1]/span[2]/a/text()’)[0] actors = selector.xpath(’//[@id=“info”]/span[3]/span[2]’)[0] actor = actors.xpath(‘string(.)’) style = re.findall(’(.?)’, html.text, re.S)[0] country1 = re.findall(‘制片国家/地区:.?’, html.text, re.S)[0] ‘’‘用re.findall爬出的数据,有很多html代码不是我们需要的,所有在爬取到的数据里在findall一次’‘’ country = re.findall(’(.?)’, country1, re.S)[0] release_time = re.findall(‘上映日期:.?>(.?)’, html.text, re.S)[0] time = re.findall(‘片长:.?>(.?)’, html.text, re.S)[0] score = selector.xpath(’//*[@id=“interest_sectl”]/div[1]/div[2]/strong/text()’)[0] # print(name, director, actor, style, country, release_time, time, score) #也可以不打印,我在这里打印只是为了看看程序爬取的过程 print('片名: ’ + name) print('导演: ’ + director) print('演员: ’ + actor) print('类型: ’ + style) print('国家: ’ + country) print('上映时间: ’ + release_time) print('时长: ’ + time) print('评分: ’ + score)‘’‘到这一步,我们已经完成了所需要的数据的爬取了,接下来再编写存储到数据库的代码’’’
‘’’ 获取信息插入数据库 ‘’’ cursor.execute( ‘insert into doubanmovie (name, director, actor, style, country, release_time, time, score) values(%s, %s, %s, %s, %s, %s, %s, %s)’, (str(name), str(director), str(actor), str(style), str(country), str(release_time), str(time), str(score)) ) except IndexError: passif name == ‘main’:
urls = [‘https://movie.douban.com/top250?start={}’.format(str(i)) for i in range(0, 50, 25)] for url in urls: get_movie_url(url) conn.commit()然后存储到数据库中,我们看看最终的效果
第一次发文章,可能有不足之处,请大家谅解 转载地址:https://blog.csdn.net/tlliang23/article/details/103518128 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
网站不错 人气很旺了 加油
[***.192.178.218]2024年03月22日 10时59分18秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
改进算法1
2021-06-29
用tensorflow,pytorch框架使用GPU,指定GPU问题
2021-06-29
数据处理中ToTensor紧接着Normalize
2021-06-29
WGAN
2021-06-29
调解算法参数2
2021-06-29
调节学习率的不同策略
2021-06-29
np.ascontiguousarray(array)
2021-06-29
from scipy import misc 读取和保存图片
2021-06-29
关于Batch Normalization
2021-06-29
关于PGGAN
2021-06-29
后台挂起,让服务器运行,客户端崩溃也可以继续运行
2021-06-29
SQL中的token含义
2021-06-29
网络的权重初始化示例
2021-06-29
python的各种推导式
2021-06-29
集合的运算关系
2021-06-29
Python的位置参数、默认参数、可变参数(*args)、关键字参数(**kwargs)
2021-06-29
匿名函数lambda
2021-06-29
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 306214314 位访客
访问时间: 2024-04-19 13:37:42
访问IP: 18.223.0.53
Copyright © 2020 - 2023 blog.css8.cn 京ICP备2021015314号-1
手机版