本文共 6277 字,大约阅读时间需要 20 分钟。
Java中的锁 | JDK6 关于锁的优化
1. JDK1.6之前的锁是什么样的
在JDK6之前,Synchronized是非常笨重的,以至于开发者不太愿意使用而慢慢摒弃它
但是在JDK6中,对Synchronized做了大量的优化,性能和ReentrantLock已经不相上下,官方也更加推荐使用Synchronized。
2. JDK1.6之后的优化
2.1 锁消除
设计一个类时,为了考虑并发安全,往往会对代码块上锁。
但是有时候压根就不会产生并发问题 例如:在线程私有的栈内存中使用线程安全的类实例,且实例不存在逃逸。
如果不存在并发安全,那还有什么理由上锁呢?
在 JIT 编译时,会对运行上下文进行扫描,去除不可能产生并发问题的锁。用代码举例:
public String method(){ StringBuffer sb = new StringBuffer(); sb.append("1"); sb.append("2"); return sb.toString();} 如上代码,StringBuffer的append()方法被synchronized修饰,但是在该方法中不存在并发问题,方法栈内存为线程私有,sb实例不可能被其他线程访问到,对于这种情况就会进行锁消除。
2.2 锁粗化
由于锁的竞争和释放开销比较大,如果代码中对锁进行了频繁的竞争和释放,那么JVM会进行优化,将锁的范围适当扩大。
如下代码,在循环内使用synchronized,JVM锁粗化后,会将锁范围扩大到循环外面
public String method(){ for (int i= 0; i < 100; i++) { synchronized (this){ ... } }} 2.3 自旋锁
正常情况下线程阻塞的话需要切换至内核态,但是优化后的处理方式如下:
线程阻塞不必直接转化为内核态, 尝试自旋可以节省下来切换成内核态(因为用户态与内核态都有各自专用的内存空间,专用的寄存器等,用户态切换至内核态需要传递给许多变量、参数给内核,内核也需要保护好用户态在切换时的一些寄存器值、变量等,以便内核态调用结束后切换回用户态继续工作。)所需要的时间。 Question : 当有多个线程在竞争同一把锁时,竞争失败的线程如何处理?
面对这种情况有两种选择:
- 将线程挂起,锁释放后再将其唤醒。
- 线程不挂起,自旋操作,不断的监测锁状态并竞争。 如果锁竞争非常激烈,且短时间得不到释放,那么将线程挂起效率会更高,因为竞争失败的线程不断自旋会造成CPU空转,浪费性能。
2.3.1 自旋锁优劣势
优势:
如果锁竞争并不激烈,且锁会很快得到释放,那么自旋效率会更高。因为将线程挂起和唤醒是一个开销很大的操作。
自旋锁的优化是针对“锁竞争不激烈,且会很快释放”的场景,避免了OS频繁挂起和唤醒线程。
缺点:
但是线程自旋是需要消耗CPU的,说白了就是让CPU在做无用功,如果一直获取不到锁,那线程也不能一直占用CPU自旋做无用功,所以需要设定一个自旋等待的最大时间.2.4 自适应自旋锁
当线程竞争锁失败时,自旋和挂起哪一种更高效?
自适应自旋锁 解决的就是这个问题
策略:
- 当线程竞争锁失败时,会自旋N次,如果仍然竞争不到锁,说明锁竞争比较激烈,继续自旋会浪费性能,JVM就会将线程挂起。
- JDK6之前: 自旋的次数通过JVM参数
-XX:PreBlockSpin设置,但是开发者往往不知道该设置多少比较合适- 于是在JDK6中: 对其进行了优化,加入了“自适应自旋锁”。
自适应自旋锁的大致原理 :
- 线程如果自旋成功了,那么下次自旋的最大次数会增加,因为JVM认为既然上次成功了,那么这一次也很大概率会成功。
- 反之,如果很少会自旋成功,那么下次会减少自旋的次数甚至不自旋,避免CPU空转。
2.5 锁膨胀
在JDK6之前,Synchronized用的都是重量级锁,依赖于OS的
Mutex Lock来实现,OS将线程从用户态切换到核心态,成本非常高,性能很低。
在JDK6中,针对锁进行优化,不直接使用重量级锁,而是逐步进行锁的膨胀。
锁状态的级别由低到高为:无锁、偏向锁、轻量级锁、重量级锁。 偏向锁、轻量级锁都属于乐观锁,重量级锁属于悲观锁。默认为无锁状态,随着锁竞争的激烈程度会不断膨胀,最终才会使用开销最大的重量级锁。
2.5.1 无锁
在对象的头信息Mark Word中记录了对象的锁状态,如下图:
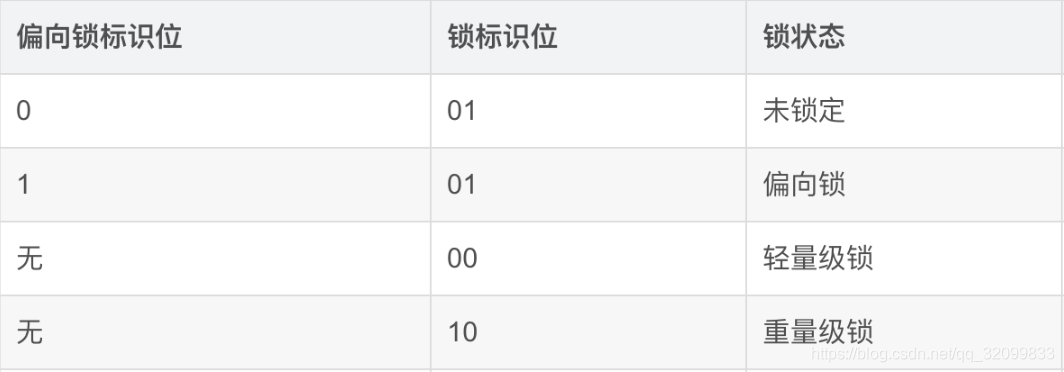
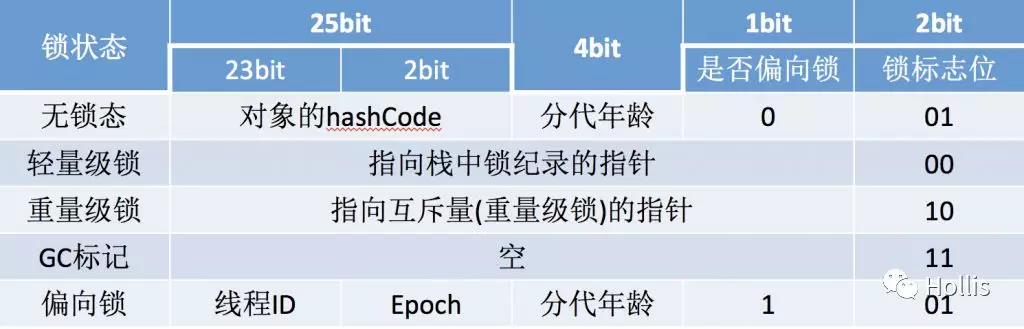
2.5.2 偏向锁
针对单线程锁竞争做的优化,最乐观的锁。
HotSpot作者经过研究发现,开发者为了保证线程安全问题给代码块上了锁,但是大多数情况下,锁并不存在多线程竞争,而是单线程反复获得。
单一线程,为什么还要去频繁的获取和释放锁呢?所以就有了“偏向锁”的概念。
偏向锁是针对单线程反复获得锁而做的优化,是最乐观的锁:只有单个线程来竞争锁。
在JDK5中偏向锁是关闭的,JDK6中默认开启,可以通过JVM参数
-XX:-UseBiasedLocking来关闭偏向锁。
偏向锁大致流程如下:
- 线程A第一次获得锁后,CAS操作修改对象头信息中的Mark Word:无锁->偏向锁、偏向线程ID->线程A。
- 线程A需要再次获得锁时,首先判断偏向线程ID是否是自己,如果是则直接获得锁,速度非常快。 偏向锁并不会主动释放,需要等待其他线程来竞争。 线程B来竞争锁,发现锁偏向线程A,此时CAS操作失败,则进一步判断:线程A是否还在占用锁?
- 线程A未占用:将锁重新偏向线程B,线程B获得锁。
- 线程A仍占用:说明锁存在多线程竞争,升级为:轻量级锁。
2.5.3 轻量级锁
针对锁竞争不激烈做的优化,使用自旋锁避免线程频繁挂起和唤醒。
只有单一线程竞争锁时用的是偏向锁,最乐观的锁也是性能最高的锁。
一旦涉及到多线程竞争锁,就会升级为轻量级锁。偏向锁发现线程不一致, 则升级为轻量级锁 - 轻量级锁认为:存在多线程竞争锁,但是竞争不激烈。
- 轻量级锁的实现原理:让竞争锁失败的线程自旋而不是挂起。
如果将竞争锁失败的线程直接挂起,然后锁释放后再将其唤醒,这是一个开销很大的操作。
而大多数情况下,锁的占用时间往往非常短,会很快被释放,那么轻量级锁认为:不要挂起线程,而是让其进行自旋,执行一些无用的指令,只要锁被释放,线程马上就能获得锁,而不用等待OS将其唤醒。总结:自旋成本 < 线程挂起成本
线程A获得锁未释放,此时线程B来竞争锁,发现锁被线程A占用,线程B认为线程A可能很快就会释放锁,于是进行自旋操作:
- 自旋成功:说明锁的占用时间并不长,下次会自适应增加最大自旋次数(自适应自旋)。
- 自旋失败:锁的占用时间较长,继续自旋会浪费CPU资源,线程被挂起,升级为:重量级锁。
2.5.4 重量级锁
开销最大,性能最低的悲观锁,锁竞争激烈时采用
- 锁竞争不激烈时,竞争锁失败的线程进行自旋而非挂起可以提升性能,因为
自旋的开销 < 线程挂起、唤醒的开销。 - 但是锁竞争激烈时,自旋会造成更大的资源开销。 例如:100个线程竞争同一把锁,99个线程在自旋,意味着99%的CPU资源被浪费,此时
自旋的开销>线程挂起、唤醒的开销。
当竞争比较激烈时,就会膨胀为重量级锁,因为轻量级锁的效率此时更低。
重量级锁通过监视器锁(Monitor)实现,Monitor又依赖于底层OS的Mutex Lock实现。
升级为重量级锁后,所有竞争锁失败的线程都会被阻塞挂起,锁被释放后再将线程唤醒。
线程频繁的挂起和唤醒,OS需要将线程从用户态切换为核心态,这个操作成本是非常高的,需要花费较长的时间,这就导致重量级锁效率很低。
3. JDK6后Sychronized和Lock性能比较
在Synchronized和Lock的区别中已经说过,在不同场景下两者的性能表现不同。
尽管JDK6为Synchronized做了大量优化,但是在竞争比较激烈时,Synchronized的性能依然会有所下降。
而Lock不管锁竞争激烈与否,性能基本保持在一个数量级,适合锁竞争比较激烈的应用场景。分别对Synchronized和Lock进行性能测试,1、10、100线程下分别进行1亿次自增运算,采样5次。
测试代码:
public abstract class PerformanceTemplate { protected int threadCount = 0;//线程数 protected int index = 0; protected final int count; protected long startTime = System.currentTimeMillis(); private final CyclicBarrier cb; public PerformanceTemplate(int count, int threadCount) { this.count = count; this.threadCount = threadCount; this.cb = new CyclicBarrier(threadCount); } public void test() { int c = count / threadCount; for (int i = 0; i < threadCount; i++) { new Thread(() -> { try { cb.await(); } catch (Exception e) { e.printStackTrace(); } while (true) { func(); } }).start(); } } protected abstract void func(); protected void print(){ System.out.println("耗时:" + (System.currentTimeMillis() - startTime)+"ms"); startTime = System.currentTimeMillis(); }}public class Sync extends PerformanceTemplate { public Sync(int count, int threadCount) { super(count, threadCount); } @Override protected synchronized void func() { if (++index % count == 0) { print(); } } @Override protected void print() { System.out.print("Synchronized:1亿次运算,"+threadCount+"线程耗时:"); super.print(); }}public class Lock extends PerformanceTemplate { private ReentrantLock lock = new ReentrantLock(); public Lock(int count, int threadCount) { super(count, threadCount); } @Override protected void func() { lock.lock(); if (++index % count == 0) { print(); } lock.unlock(); } @Override protected void print() { System.out.print("Lock:1亿次运算,"+threadCount+"线程耗时:"); super.print(); }} 测试结果:
Synchronized:1亿次运算,1线程耗时:耗时:3174msSynchronized:1亿次运算,1线程耗时:耗时:1878msSynchronized:1亿次运算,1线程耗时:耗时:2404msSynchronized:1亿次运算,1线程耗时:耗时:2392msSynchronized:1亿次运算,1线程耗时:耗时:2409ms---Synchronized:1亿次运算,10线程耗时:耗时:4835msSynchronized:1亿次运算,10线程耗时:耗时:5407msSynchronized:1亿次运算,10线程耗时:耗时:5391msSynchronized:1亿次运算,10线程耗时:耗时:5406msSynchronized:1亿次运算,10线程耗时:耗时:5462ms---Synchronized:1亿次运算,100线程耗时:耗时:4538msSynchronized:1亿次运算,100线程耗时:耗时:4921msSynchronized:1亿次运算,100线程耗时:耗时:4957msSynchronized:1亿次运算,100线程耗时:耗时:4999msSynchronized:1亿次运算,100线程耗时:耗时:4980ms
Lock:1亿次运算,1线程耗时:耗时:1985msLock:1亿次运算,1线程耗时:耗时:1961msLock:1亿次运算,1线程耗时:耗时:1857msLock:1亿次运算,1线程耗时:耗时:2138msLock:1亿次运算,1线程耗时:耗时:1912ms---Lock:1亿次运算,10线程耗时:耗时:2986msLock:1亿次运算,10线程耗时:耗时:2861msLock:1亿次运算,10线程耗时:耗时:2792msLock:1亿次运算,10线程耗时:耗时:2792msLock:1亿次运算,10线程耗时:耗时:2773ms---Lock:1亿次运算,100线程耗时:耗时:3023msLock:1亿次运算,100线程耗时:耗时:2743msLock:1亿次运算,100线程耗时:耗时:2706msLock:1亿次运算,100线程耗时:耗时:2714msLock:1亿次运算,100线程耗时:耗时:2765ms
可以看到,Synchronized经过优化之后,性能并不差,和Lock差不多,Lock性能稍微高一丢丢。
3.1 Sychornized和Lock两者如何选择?
-
Synchronized是Java内置的同步器,使用简单,语法清晰易读,性能也不差,而且便于JVM堆栈跟踪,官方也表示Synchronized性能后期还有优化的余地,所以如果没有特殊要求,建议尽量使用Synchronized。
-
虽然建议尽量使用Synchronized,但是它毕竟自身存在一些功能上的缺陷,例如:无法响应中断,不支持锁超时,不能采用公平锁等等,如果确实需要这些高级特性,那么还是应该使用ReentrantLock(重进入锁)。
转载地址:https://blog.csdn.net/weixin_40597409/article/details/115438968 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
