本文共 11663 字,大约阅读时间需要 38 分钟。
基础知识
爬虫基本原理
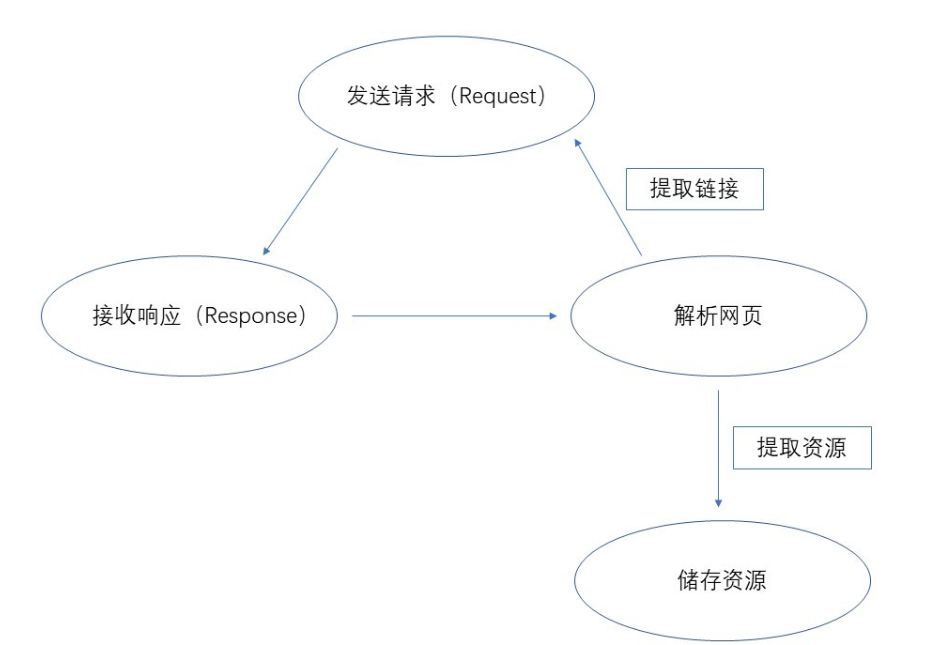
1、发起请求使用http库向目标站点发起请求,即发送一个RequestRequest中包含哪些内容?(1)请求方式主要是GET、POST两种类型,另外还有HEAD、PUT、DELETE、OPTIONS等。(2)请求URLURL全称是统一资源定位符,如一个网页文档、一张图片、一个视频等都可以用URL来唯一来确定(3)请求头包含请求时的头部信息,如User-Agent、Host、Cookies等信息(4)请求体请求时额外携带的数据,如表单提交时的表单数据2、获取响应内容如果服务器能正常响应,则会得到一个ResponseResponse中包含哪些内容?(1)响应状态有多种响应状态,如200代表成功,301代表跳转,404代表找不到页面,502代表服务器错误等(2)响应头如内容类型、内容长度、服务器信息、设置cookies等等(3)响应体最主要的部分,包含了请求资源的内容,如网页HTML、图片二进制数据等。3、解析内容解析html数据:正则表达式,第三方解析库如Beautifulsoup,pyquery等解析json数据:json模块解析二进制数据:以b的方式写入文件4、保存数据文本、二进制文件、数据库等Request:用户将自己的信息通过浏览器(socket client)发送给服务器(socket server)Response:服务器接收请求,分析用户发来的请求信息,然后返回数据(返回的数据中可能包含其他链接,如:图片,js,css等)ps:浏览器在接收Response后,会解析其内容来显示给用户,而爬虫程序在模拟浏览器发送请求然后接收Response后,是要提取其中的有用数据。
Requests的基本使用
Requests 是一个功能强大、简单易用的 HTTP 请求库,可以使用 pip install requests 命令进行安装。
get方法
该方法用于向目标网址发送请求,接收响应
该方法的参数说明如下:| 参数 | 说明 |
|---|---|
| url | 必填,指定请求 URL |
| params | 字典类型,指定请求参数,常用于发送 GET 请求时使用 |
| data | 字典类型,指定表单信息,常用于发送 POST 请求时使用 (此时应该使用 post 方法,只需要简单的将 get 替换成 post 即可) |
| headers | 字典类型,指定请求头部 |
| proxies | 字典类型,指定使用的代理 |
| cookies | 字典类型,指定 Cookie |
| auth | 元组类型,指定登陆时的账号和密码 |
| verify | 布尔类型,指定请求网站时是否需要进行证书验证,默认为 True,表示需要证书验证 |
| timeout | 指定超时时间,若超过指定时间没有获得响应,则抛出异常 |
该方法返回一个 Response 对象,其常用的属性和方法列举如下:
| 属性方法 | 说明 |
|---|---|
| response.url | 返回请求网站的 URL |
| response.status_code | 返回响应的状态码 |
| response.encoding | 返回响应的编码方式 |
| response.cookies | 返回响应的 Cookie 信息 |
| response.headers | 返回响应头 |
| response.content | 返回 bytes 类型的响应体 |
| response.text | 返回 str 类型的响应体,相当于 response.content.decode(‘utf-8’) |
| response.json() | 返回 dict 类型的响应体,相当于 json.loads(response.text) |
XPath
作用:解析XML(HTML)
对于网页解析来说,xpath比re更加方便简洁,故 Python 中也提供相应的模块 —— lxml.etree,我们可以使用pip install lxml 命令进行安装。 XML 文档中常见的节点包括: | 根节点 | html |
| 元素节点 | html、body、div、p、a |
| 属性节点 | href |
| 文本节点 | Hello world、Click here |
XML 文档中常见的节点间关系包括:
父子: 例如,和 是
匹配语法:
| / | 子代节点 |
| // | 后代节点 |
| * | 所有节点 |
| text() | 文本节点 |
| @ATTR | 属性节点 |
谓语 :用于匹配指定的标签
1.指定第二个 标签test = html.xpath('//a[2]')2.指定前两个 标签test = html.xpath('//a[position()<=2]')3.指定带有 href 属性的 标签test = html.xpath('//a[@href]')4.指定带有 href 属性且值为 image1.html 的 标签 test = html.xpath('//a[@href="image1.html"]')5.指定带有 href 属性且值包含 image 的 标签test = html.xpath('//a[contains(@href,"image")]')
_Element 对象:
xpath 方法返回字符串或者匹配列表,匹配列表中的每一项都是 lxml.etree._Element 对象| tag | 返回标签名 |
| attrib | 返回属性与值组成的字典 |
| get() | 返回指定属性的值 |
| text | 返回文本值 |
网页分析
for i in range ()
range(start, stop[, step]),分别是起始、终止和步长
for i in range(3): print(i) 012for i in range(1,3): print(i)12
多进程
multiprocessing多进程-Pool进程池模块
Multiprocessing.Pool可以提供指定数量的进程供用户调用,当有新的请求提交到pool中时,如果池还没有满,那么就会创建一个新的进程用来执行该请求;但如果池中的进程数已经达到规定最大值,那么该请求就会等待,直到池中有进程结束,才会创建新的进程来执行它。Pool类用于需要执行的目标很多,而手动限制进程数量又太繁琐时,如果目标少且不用控制进程数量则可以用Process类。
class multiprocessing.pool.Pool([processes[, initializer[, initargs[, maxtasksperchild[, context]]]]])
| processes | 是要使用的工作进程数。如果进程是None,那么使用返回的数字os.cpu_count()。也就是说根据本地的cpu个数决定,processes小于等于本地的cpu个数 |
| initializer | 如果initializer是None,那么每一个工作进程在开始的时候会调用initializer(*initargs)。 |
| maxtasksperchild | 工作进程退出之前可以完成的任务数,完成后用一个新的工作进程来替代原进程,来让闲置的资源被释放。maxtasksperchild默认是None,意味着只要Pool存在工作进程就会一直存活。 |
| context | 用在制定工作进程启动时的上下文,一般使用 multiprocessing.Pool() 或者一个context对象的Pool()方法来创建一个池,两种方法都适当的设置了context。 |
实例方法:
apply(func [,args [,kwds ] ] )
使用参数args和关键字参数kwds调用func。它会阻塞,直到结果准备就绪。鉴于此块,更适合并行执行工作。此外,func 仅在池中的一个工作程序中执行。
from multiprocessing import Poolimport timedef test(p): print(p) time.sleep(3)if __name__=="__main__": pool = Pool(processes=10) for i in range(500): ''' ('\n' ' (1)遍历500个可迭代对象,往进程池放一个子进程\n' ' (2)执行这个子进程,等子进程执行完毕,再往进程池放一个子进程,再执行。(同时只执行一个子进程)\n' ' for循环执行完毕,再执行print函数。\n' ' ') ''' pool.apply(test, args=(i,)) #维持执行的进程总数为10,当一个进程执行完后启动一个新进程. print('test') pool.close() pool.join() apply_async(func [,args [,kwds [,callback [,error_callback ] ] ] ] )
异步进程池(非阻塞),返回结果对象的方法的变体。如果指定了回调,则它应该是可调用的,它接受单个参数。当结果变为就绪时,将对其应用回调,即除非调用失败,在这种情况下将应用error_callback。如果指定了error_callback,那么它应该是一个可调用的,它接受一个参数。如果目标函数失败,则使用异常实例调用error_callback。回调应立即完成,否则处理结果的线程将被阻止。
from multiprocessing import Poolimport timedef test(p): print(p) time.sleep(3)if __name__=="__main__": pool = Pool(processes=2) for i in range(500): ''' (1)循环遍历,将500个子进程添加到进程池(相对父进程会阻塞)\n' (2)每次执行2个子进程,等一个子进程执行完后,立马启动新的子进程。(相对父进程不阻塞)\n' ''' pool.apply_async(test, args=(i,)) #维持执行的进程总数为10,当一个进程执行完后启动一个新进程. print('test') pool.close() pool.join() map(func,iterable [,chunksize ] )
map()内置函数的并行等价物(尽管它只支持一个可迭代的参数)。它会阻塞,直到结果准备就绪。此方法将iterable内的每一个对象作为单独的任务提交给进程池。可以通过将chunksize设置为正整数来指定这些块的(近似)大小。
from multiprocessing import Pooldef test(i): print(i)if __name__ == "__main__": lists = [1, 2, 3] pool = Pool(processes=2) #定义最大的进程数 pool.map(test, lists) #p必须是一个可迭代变量。 pool.close() pool.join()
map_async(func,iterable [,chunksize [,callback [,error_callback ] ] ] )
map()返回结果对象的方法的变体。需要传入可迭代对象iterable
from multiprocessing import Poolimport timedef test(p): print(p) time.sleep(3)if __name__=="__main__": pool = Pool(processes=2) # for i in range(500): # ''' # (1)循环遍历,将500个子进程添加到进程池(相对父进程会阻塞)\n' # (2)每次执行2个子进程,等一个子进程执行完后,立马启动新的子进程。(相对父进程不阻塞)\n' # ''' # pool.apply_async(test, args=(i,)) #维持执行的进程总数为10,当一个进程执行完后启动一个新进程. pool.map_async(test, range(500)) print('test') pool.close() pool.join() imap(func,iterable [,chunksize ] )
返回迭代器,next()调用返回的迭代器的方法得到结果,imap()方法有一个可选的超时参数: next(timeout)将提高multiprocessing.TimeoutError如果结果不能内退回超时秒。
close()
防止任何更多的任务被提交到池中。 一旦完成所有任务,工作进程将退出。
terminate()
立即停止工作进程而不完成未完成的工作。当池对象被垃圾收集时,terminate()将立即调用。
join()
调用join之前,先调用close或者terminate方法,否则会出错。执行完close后不会有新的进程加入到pool,join函数等待所有子进程结束。
SQLite
参考链接:
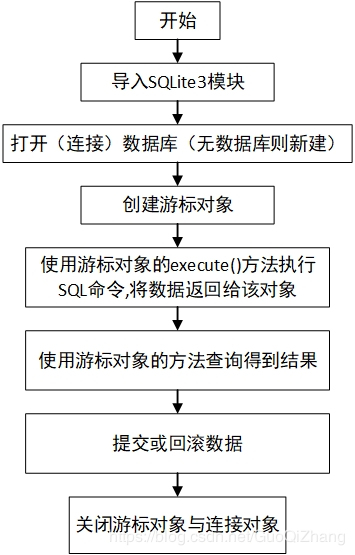
- 导入数据库模块 python2.5以后的安装包自带SQLite3的软件包
import sqlite3
- 链接sqlite3数据库
# 创建链接对象# 打开一个到 SQLite 数据库文件 youdao.db的链接# 如果该数据库不存在则会自动创建,可以指定带有文件路径的文件名conn = sqlite3.connect('youdao.db') - 获取游标对象
# 获取游标对象用来操作数据库c = conn.cursor()
- 操作sqlite数据库
#创建表#方法一:c.execute("CREATE TABLE IF NOT EXISTS test(id INTEGER PRIMARY KEY,name TEXT,age INTEGER)")#方法二:c.execute("CREATE TABLE test(id INTEGER PRIMARY KEY,name TEXT,age INTEGER)")#如果使用方法二(不加 IF NOT EXISTS),当项目中存在相同的表时会报错,所以为了省略检查表是否已建立的过程,建议使用方法一。#新增数据#方法一data = "5,'leon',22"c.execute('INSERT INTO test VALUES (%s)'%data)#方法二c.execute("INSERT INTO test values(?,?,?)",(6,"zgq",20))#方法三c.executemany('INSERT INTO test VALUES (?,?,?)',[(3,'name3',19),(4,'name4',26)])#更新数据#方法一:c.execute("UPDATE test SET name=? WHERE id=?",("nihao",1))#方法二:c.execute("UPDATE test SET name='haha' WHERE id=1")#删除数据#方法一:n=c.execute("DELETE FROM test WHERE id=?",(1,))#方法二:n=c.execute("DELETE FROM test WHERE id=2")#返回的n为游标对象#查询数据#查询的结果存储在游标对象c中,可以使用对象的方法进行访问。c.execute("SELECT * FROM test")#删除表c.execute("DROP TABLE Test ")#查询并显示数据#全部显示c.execute("select * from Test")for item in cur: print(item)或print(cur.fetchall())#显示一条print(cur.fetchone())#显示多条print(cur.fetchmany(3))#使用游标的方法返回的数据类型是列表 - 提交事务关闭数据库
c.close()#关闭游标,不关似乎不会有明显问题conn.commit()# 提交事务conn.close()# 关闭链接
爬取数据代码
from multiprocessing import Poolimport requestsfrom lxml import etreedef word(i): def get_page(url): #构造请求头部 headers = { 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36' } #向目标网址发送请求,接收响应,返回一个 Response 对象 response = requests.get(url=url,headers=headers) requests.adapters.DEFAULT_RETRIES = 5 # 获得网页源代码 html = response.text return html #打开单词文件读取单词查询 with open('./word.txt',encoding = 'utf-8') as f: a = f.readlines() w =a[i] word = w.rstrip('\n') url = 'http://www.youdao.com/w/'+word+'/#keyfrom=dict2.top' html = get_page(url) # 构造 lxml.etree._Element 对象 # lxml.etree._Element 对象还具有代码补全功能 # 假如我们得到的 XML 文档不是规范的文档,该对象将会自动补全缺失的闭合标签 html_elem = etree.HTML(html) #// 表示后代节点 * 表示所有节点 text() 表示文本节点 # xpath 方法返回字符串或者匹配列表,匹配列表中的每一项都是 lxml.etree._Element 对象 fy1 = html_elem.xpath('//*[@id="phrsListTab"]/div[2]/ul//*/text()') #每个元素后面加换行符 for x in range(len(fy1)): fy1[x]+='\n' chinese = "".join(fy1).replace("'","''")#数据库插入时'会报错 if (chinese !=""): with open('./chinese/'+word+'.txt','w',encoding = 'utf-8') as fd: fd.write(chinese+'\n')#写到缓存区 fd.flush()#将缓存区数据写入文件 fy2 = html_elem.xpath('//*[@id="phrsListTab"]/h2/div/span[1]//*/text()') british = "".join(fy2).replace("'","''") if (british !=""): with open('./british/'+word+'.txt','w',encoding = 'utf-8') as fd: fd.write(british+'\n')#写到缓存区 fd.flush()#将缓存区数据写入文件 fy3 = html_elem.xpath('//*[@id="phrsListTab"]/h2/div/span[2]//*/text()') american = "".join(fy3).replace("'","''") if (american !=""): with open('./american/'+word+'.txt','w',encoding = 'utf-8') as fd: fd.write(american+'\n')#写到缓存区 fd.flush()#将缓存区数据写入文件 #爬例句 n=1 sentence='' while True: fy4 = html_elem.xpath('//*[@id="bilingual"]/ul/li['+str(n)+']/p[1]//text()') fy5 = html_elem.xpath('//*[@id="bilingual"]/ul/li['+str(n)+']/p[2]//text()') #整齐 s = "".join(fy4).replace("'","''").strip()+'\n'+"".join(fy5).replace("'","''").strip() s1 =s.replace( ' ' , '' ) s2 =str(n)+'.'+s #加编号 #判断是否为空 if (s1.strip()==''): break #所有例句整合 sentence =sentence+s2+'\n' n=n+1 if (sentence !=""): with open('./sentence/'+word+'.txt','w',encoding = 'utf-8') as fd: fd.write(sentence+'\n')#写到缓存区 fd.flush()#将缓存区数据写入文件 if __name__ == '__main__': pool=Pool(processes=4)#申请的进程数 for i in range(1000,74399): pool.apply_async(word,(i,)) #异步执行,非阻塞方式 pool.close()#关闭进程池,关闭之后,不能再向进程池中添加进程 pool.join()#当进程池中的所有进程执行完后,主进程才可以继续执行。 导入数据库
多进程似乎和sqlite无法同时使用,所以先爬取内容到txt,再写入sqlite
import sqlite3import os.path#连接数据库,不存在则创建conn = sqlite3.connect('youdao.db')# 获取游标对象用来操作数据库c = conn.cursor()#创建表c.execute('''CREATE TABLE IF NOT EXISTS USE ( English VARCHAR(100) PRIMARY KEY NOT NULL, Synonyms VARCHAR(100) NOT NULL, WordGroup VARCHAR(100) NOT NULL, Discriminate VARCHAR(100) NOT NULL);''')with open('./word.txt',encoding = 'utf-8') as f: a = f.readlines() for i in range(0,74398): w =a[i] word = w.rstrip('\n') synonyms ="" wordGroup ="" discriminate ="" sign = False #判断文件是否存在 if (os.path.isfile('./synonyms/'+word+'.txt')): fd1 = open('./synonyms/'+word+'.txt',encoding = 'utf-8') synonyms ="".join(fd1.read()) sign = True if (os.path.isfile('./wordGroup/'+word+'.txt')): fd2 = open('./wordGroup/'+word+'.txt',encoding = 'utf-8') wordGroup ="".join(fd2.read()) sign = True if (os.path.isfile('./discriminate/'+word+'.txt')): fd3 = open('./discriminate/'+word+'.txt',encoding = 'utf-8') discriminate ="".join(fd3.read()) sign = True if(sign): #插入数据 c.execute("INSERT OR IGNORE INTO USE (English,Synonyms,WordGroup,Discriminate) \ VALUES ('%s', '%s' ,'%s','%s')"%(word,synonyms,wordGroup,discriminate))print("insert successfully")c.close()#关闭游标,不关似乎不会有明显问题conn.commit()# 提交事务conn.close()# 关闭链接 转载地址:https://blog.csdn.net/Leslie_Waong/article/details/105583730 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
