深度学习-TokenEmbedding-安装torch-GPU版本
发布日期:2022-02-17 04:52:21
浏览次数:16
分类:技术文章
本文共 1165 字,大约阅读时间需要 3 分钟。
TokenEmbedding:
向量矩阵:
类似字典,第一行为字典里第一个词的词向量;
例子:embedding若为300维,字典中有30000个词
token-embedding维度为:30000(列)*300(行),每一行为一个词向量。
第三行为,字典中第三个字对应的词向量。词向量大小为300维。
若中英文混杂,调用的中文tokenembedding,会将英文当做UNK处理。在特定领域需要自己进行词向量和词表的构建,效果会更好。
NLP任务中的字典:
一一对应关系,例:一个字对应一个索引
根据字典得到索引,就能得到词向量,任务结束后得到索引,根据词典,在返回结果。
深度学习处理NLP任务:
不处理特殊字符,以字为单位。都有对应的embedding
下载anaconda:
cuda和cuDNN的关系和对应关系:
查看cuda版本
win+r
cmd
nvcc --version
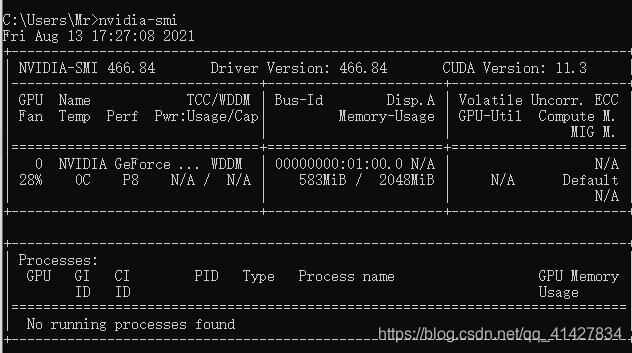
查看对应版本
根据cuda版本下载离线对应torch:
torch-N.x.x+cu110....torchaudio-0.x.x(x.x版本与上面对应
torchvision-...+cu110...
离线安装
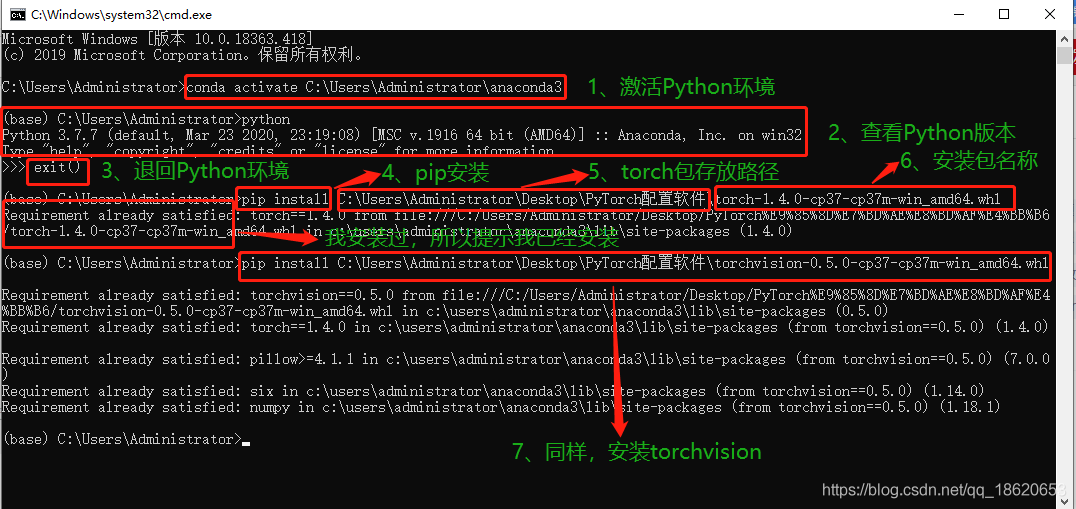
图转自
测试torch.cuda命令:
import torch#返回当前设备索引# torch.cuda.current_device()#返回GPU的数量# torch.cuda.device_count()#返回gpu名字,设备索引默认从0开始# torch.cuda.get_device_name(0)#cuda是否可用# torch.cuda.is_available()# pytorch 查看cuda 版本# 由于pytorch的whl 安装包名字都一样,所以我们很难区分到底是基于cuda 的哪个版本。# print(torch.version.cuda)# 判断pytorch是否支持GPU加速# print (torch.cuda.is_available())# 【PyTorch】查看自己的电脑是否已经准备好GPU加速(CUDA)# 那么在CUDA已经准备好的电脑上,会输出:cuda:0# 而在没有CUDA的电脑上则输出:cpudevice = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")print(device)————————————————版权声明:本文为CSDN博主「Gabriel_wei」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。原文链接:https://blog.csdn.net/Gabriel_wei/article/details/109897175 转载地址:https://blog.csdn.net/qq_41427834/article/details/118652925 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
留言是一种美德,欢迎回访!
[***.207.175.100]2024年04月01日 08时54分00秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
C++ 实现Buffer 动态分配管理代码实现
2019-04-26
C++ 实现Buffer 动态分配管理,FIFO模式存取数据
2019-04-26
动态修改屏分辨率
2019-04-26
高通平台启动过程
2019-04-26
2019年11月 生活记录&总结
2019-04-26
架构学习内容
2019-04-26
Android Audio Debug相关方法
2019-04-26
Android C++延时
2019-04-26
20200208 新的一年,学习大方向
2019-04-26
【Linux内核】---- 01 开机上电初始化过程
2019-04-26
【Linux内核】---- 02 从main到怠速
2019-04-26
【Linux内核】---- 03 安装文件系统
2019-04-26
【Android 输入子系统 01】- 前言
2019-04-26
输入子系统(input subsystem)
2019-04-26
Input Subsystem 底层框架浅析
2019-04-26
Android输入子系统之启动过程分析
2019-04-26
【输入子系统01】USB触摸屏驱动
2019-04-26
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 306243894 位访客
访问时间: 2024-04-19 16:49:12
访问IP: 3.137.172.68
Copyright © 2020 - 2023 blog.css8.cn 京ICP备2021015314号-1
手机版