python爬取网页代码_python爬虫爬取网页的内容和网页源码不同?
发布日期:2022-02-04 01:43:52
浏览次数:34
分类:技术文章
本文共 379 字,大约阅读时间需要 1 分钟。

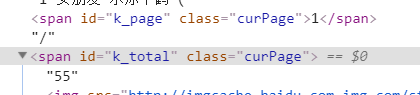
可以看到这里id为k_total的元素值不同,爬出来是1,网页源码是55。
附还未完成的代码:import requests
from bs4 import BeautifulSoup
import re
head={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36',
'Referer':'http://m.manhuaju.com/maoxian/zujienvyou/420624.html'
}
baseurl=r'http://m.manhuaju.com/maoxian/zujienvyou/'
find_link=re.compile('
转载地址:https://blog.csdn.net/weixin_39603908/article/details/110164893 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
哈哈,博客排版真的漂亮呢~
[***.90.31.176]2024年03月23日 19时01分26秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
【Linux】一步一步学Linux——rename命令(36)
2019-04-26
【Linux】一步一步学Linux——file命令(37)
2021-06-29
【Linux】一步一步学Linux——cat/tac命令(38)
2021-06-29
【Linux】一步一步学Linux——cut命令(44)
2021-06-29
【Linux】一步一步学Linux——sort命令(53)
2021-06-29
【Linux】一步一步学Linux——uniq命令(54)
2021-06-29
【Linux】一步一步学Linux——tr命令(55)
2021-06-29
【Linux】一步一步学Linux——join命令(56)
2021-06-29
【Linux】一步一步学Linux——rev命令(57)
2021-06-29
【Linux】一步一步学Linux——paste命令(58)
2021-06-29
【Linux】一步一步学Linux——split命令(59)
2021-06-29
【Linux】一步一步学Linux——iconv命令(60)
2021-06-29
【Linux】一步一步学Linux——md5sum命令(61)
2021-06-29
【Linux】一步一步学Linux——tar命令(62)
2021-06-29
【Linux】一步一步学Linux——gzip命令(63)
2021-06-29
【Linux】一步一步学Linux——gunzip命令(64)
2021-06-29
【Linux】一步一步学Linux——bzip2命令(65)
2021-06-29
【Linux】一步一步学Linux——bunzip2命令(66)
2021-06-29
【Linux】一步一步学Linux——zip命令(67)
2021-06-29
【Linux】一步一步学Linux——unzip命令(68)
2021-06-29
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 306496395 位访客
访问时间: 2024-04-20 17:20:38
访问IP: 3.141.24.134
Copyright © 2020 - 2023 blog.css8.cn 京ICP备2021015314号-1
手机版