Spark源码(九)——资源调度机制
 LaunchDriver方法:
LaunchDriver方法: 
发布日期:2021-11-18 17:47:15
浏览次数:9
分类:技术文章
本文共 2581 字,大约阅读时间需要 8 分钟。
文章目录
前言
资源分配
Spark的分配资源主要就是 executor数量、每个executor需要的CPU core 数量、每个 executor 需要的内存大小。分配资源,首先要了解机器有多大的内存,多少个cpu core,就根据这个实际情况去设置。一个cpu对应2-3task合理。资源分配的两种方式:
- 静态分配:在提交任务的时候设置
- 动态分配:根据数据的大小、需要的运算能力设置,便于以后类似任务的重用
Standalone 模式
如果每台机器可用内存是4G,2个cpu core,20台机器,
那可以设置:20个executor,每个executor4G内存,2个cpu core(资源最大化利用)。yarn 模式下
根据spark要提交的资源队列资源来考虑,如果所在队列资源为500G内存,100个cpu core。
可以设置50个executor;每个executor10G内存2个cpu分配资源分析
增加每个executor的cpu core,也是增加了执行的并行能力。 原本20个executor,每个才2个cpu core。能够并行执行的task数量,就是40个task。如果现在每个executor的cpu core,增加到了5个。能够并行执行的task数量,就是100个task。执行的速度,提升了2.5倍。如果executor数量比较少,那么能够并行执行的task数量就比较少,就意味着Application的并行执行的能力就很弱。增加每个executor的内存量。 增加了内存量以后,对性能的提升有几点:
- 如果需要对RDD进行cache,那么更多的内存,就可以缓存更多的数据,将更少的数据写入磁盘,甚至不写入磁盘。减少了磁盘IO
- 对于shuffle操作,reduce端,会需要内存来存放拉取的数据并进行聚合。如果内存不够,也会写入磁盘。如果给executor分配更多内存以后,就有更少的数据,需要写入磁盘,甚至不需要写入磁盘。减少了磁盘IO,提升了性能
- 对于task的执行,可能会创建很多对象。如果内存比较小,可能会频繁导致JVM堆内存满了,然后频繁GC(速度很慢)。内存加大以后,带来更少的GC
Spark的Master资源分配算法
概述流程
Master资源调度通过schedule()方法实现,步骤如下:- 首先判断master是否是alive状态,如果不是alive则返回,也就是只有活动的master才会进行资源调度,standby master是不会进行资源调度的
- 把之前注册的worker中的alive状态的worker传入 Random.shuffle方法,该方法主要是把worker顺序打乱,返回一个数组
- 获取返回的worker的数量
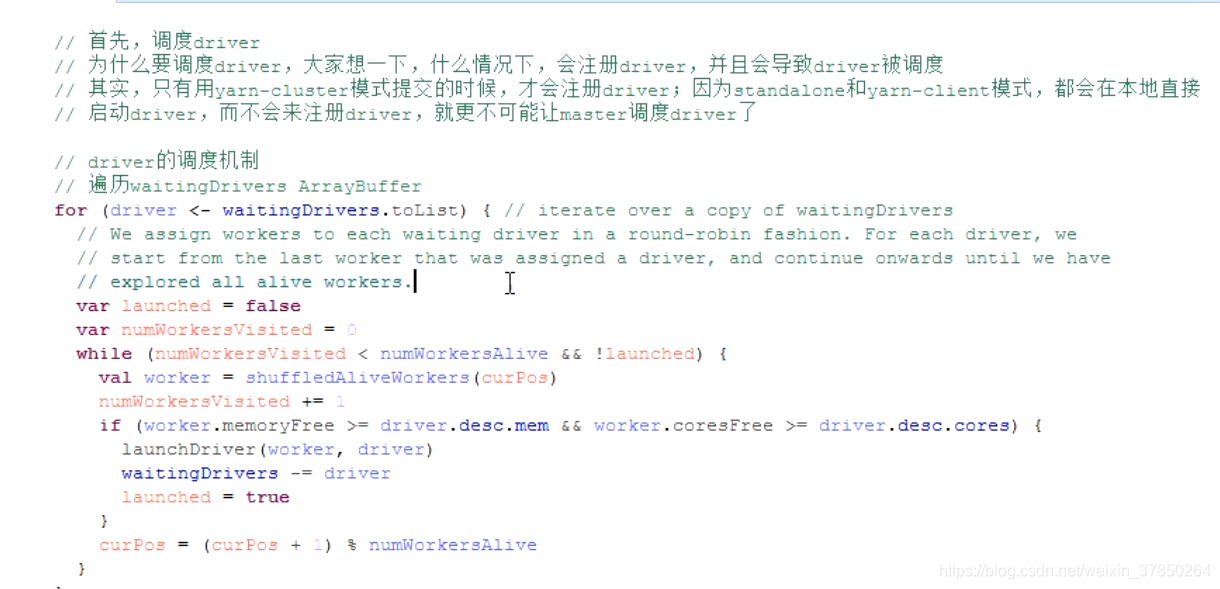
- 用for循环进行driver调度,只有启用yarn-cluster模式提交application才会进行driver调度,因为yarn-client和 standalone模式都是在提交的客户端启动driver,不需要调度
- for循环遍历WaittingDrivers,如果这个worker的内存>=driver需要的内存并且CPU>=driver需要的CPU,则启动driver,将driver从WaittingDrivers队列中移除
- 启动driver的方法为launchDriver,将driver加入worker的内部缓存,将worker剩余的内存、CPU减去driver需要的内存、CPU,worker也被加入到driver缓存结构中,然后调用worker的actor方法,给worker发送LaunchDriver消息,让它把driver启动起来,然后将driver状态改为RUNNING
- driver启动后,进行application的调度,这里有两个算法,spreadOutApps和非spreadOutApps算法,这个在代码的SparkConf里可以设置, (“spark.deploy.spreadOut”, true),默认是为true,启用spreadoutApps
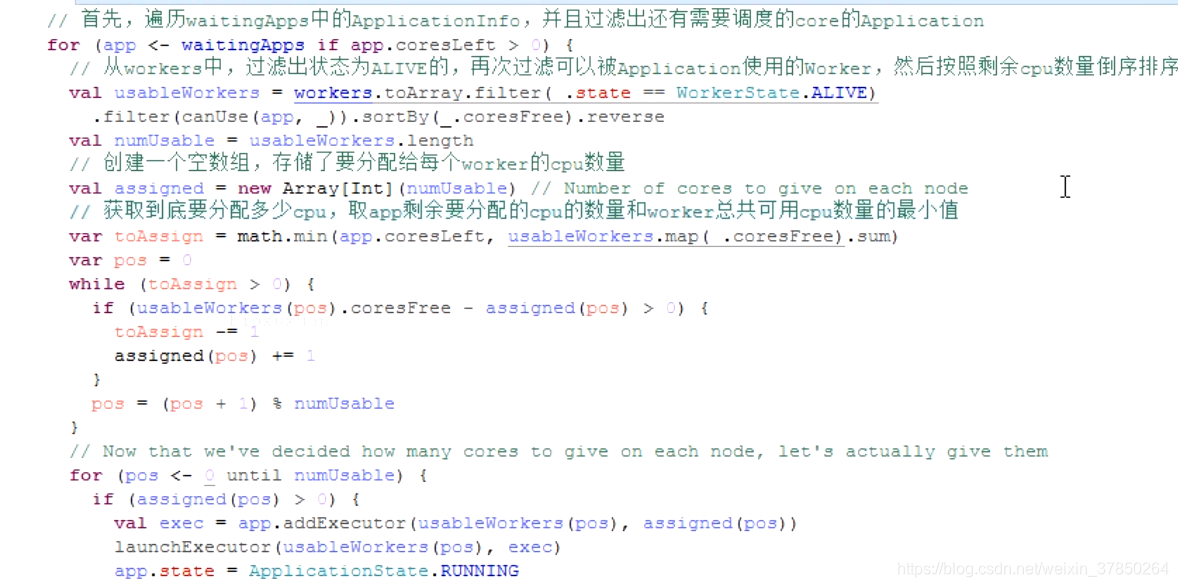
- for遍历WaitingApps中的application,并且用if守卫过滤出还需要进行CPU分配的application,再次过滤状态为alive并且可以被application使用的worker,然后按照其剩余的CPU数量倒序排序
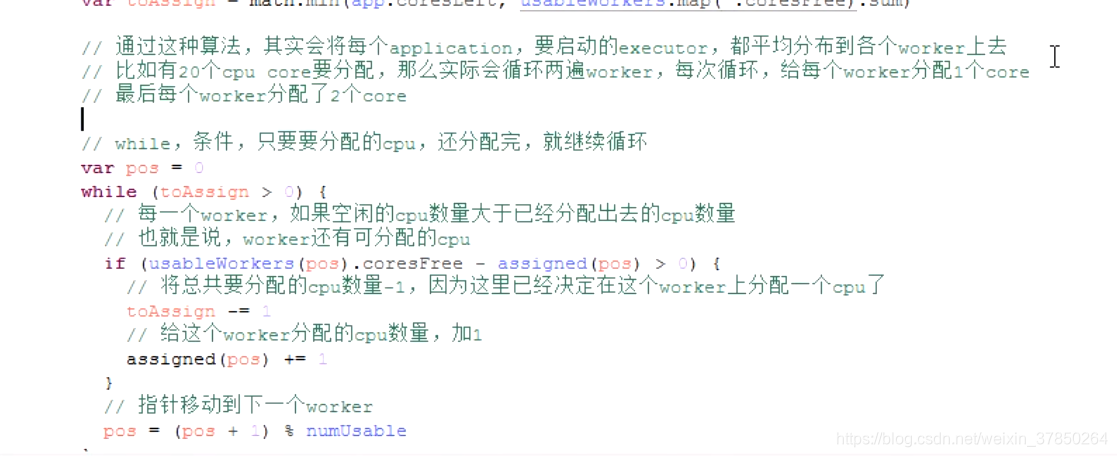
- 把需要分配的application数量放入一个数组,然后获取最终需要分配的CPU数量=application需要分配的CPU和worker总CPU的最小值
- while遍历worker,如果worker还有可分配的CPU,将总的需要分配的CPU-1,给这个worker分配的CPU+1,指针移到下一个CPU。循环一直到CPU分配完,这种分配算法的结果是application的CPU尽可能的平均分配到了各个worker上,应用程序尽可能多的运行在所有的Node上
- 给worker分配完CPU后,遍历分配到CPU的worker,在每个application内部缓存结构中,添加executor,创建executorDSC对象,其中封装了给这个executor分配多少 CPU core,然后在worker上启动executor,将application状态改为RUNNING
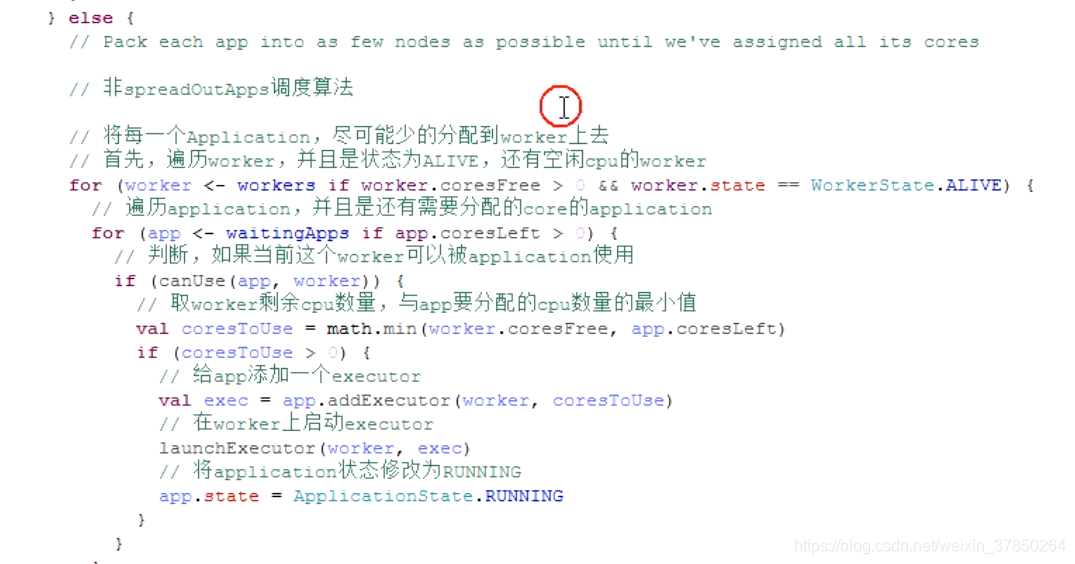
- 如果是非spreadOutApps算法,刚好相反,先把每个worker的CPU全部分配完,在分配下一个worker的CPU
剖析scheduler方法

LaunchDriver方法: Application的调度机制
- spreadout分配算法,平均分的思想


- 非spreadout算法,这种算法和 spreadoutApps算法正好相反,每个app1 natlon,都尽可能分配到尽量少的 worker上去,比如总共有10个worker,每个有10个core,app总共要分配20个cre,那么其实,只会分配到两个 worker上,每个 worker都占满10个core,那么,其余的ap,就只能分配到下一个 worke
转载地址:https://blog.csdn.net/weixin_37850264/article/details/112184345 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
很好
[***.229.124.182]2024年04月17日 17时05分54秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
BeautifulSoup库的安装及基本元素
2019-04-26
基于bs4的HTML内容遍历方法
2019-04-26
信息标记与信息提取
2019-04-26
各大网站CSS初始化代码
2019-04-26
正则表达式的基本用法
2019-04-26
Python的Re库(正则表达式)基本用法
2019-04-26
Scrapy爬虫框架
2019-04-26
Anaconda
2019-04-26
NumPy库入门
2019-04-26
简单的留言板网页
2019-04-26
如何快速的搭建Apache+MySQL+PHP+PERL的环境
2019-04-26
初识JavaScript
2019-04-26
JavaScript的常用互动方法
2019-04-26
JavaScript的DOM操作
2019-04-26
JavaScript实现的网页计算器功能
2019-04-26
【物联网实训项目】------(一)家庭智慧安防系统之前期项目工作准备
2019-04-26
【物联网实训项目】------(二)家庭智慧安防系统之定时监控
2019-04-26
【物联网实训项目】------(三)家庭智慧安防系统之实时监控
2019-04-26
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 306479157 位访客
访问时间: 2024-04-20 15:39:30
访问IP: 3.141.47.221
Copyright © 2020 - 2023 blog.css8.cn 京ICP备2021015314号-1
手机版