Spark源码(四)——sparkcontext

 2.TaskSchedulerImpl对象的初始化方法主要是新建了一个调度线程池
2.TaskSchedulerImpl对象的初始化方法主要是新建了一个调度线程池 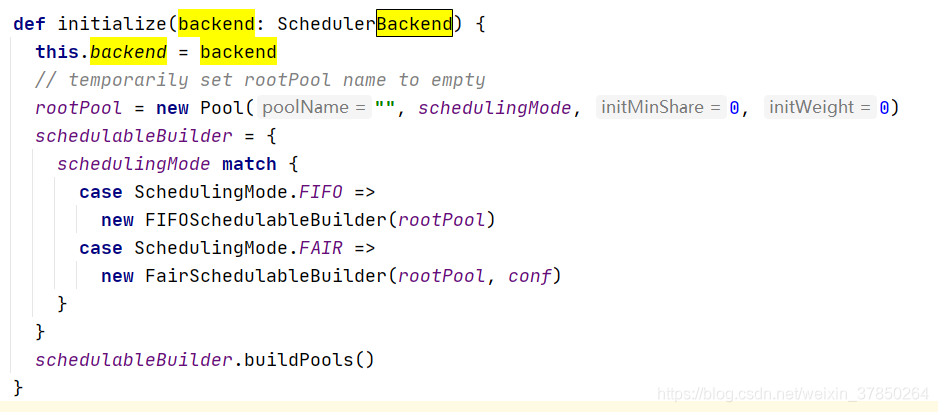 3.Taskscheduler对象开始运行start()方法;注意其start方法其实是调用sparkdeployschedulerbackend的start()方法,
3.Taskscheduler对象开始运行start()方法;注意其start方法其实是调用sparkdeployschedulerbackend的start()方法, 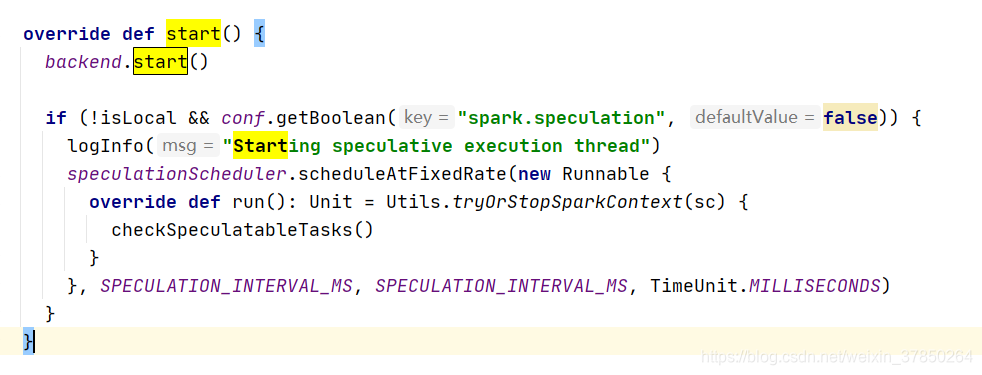 而在sparkdeployschedulerbackend的start方法中主要就是做了以下两个工作:
而在sparkdeployschedulerbackend的start方法中主要就是做了以下两个工作: 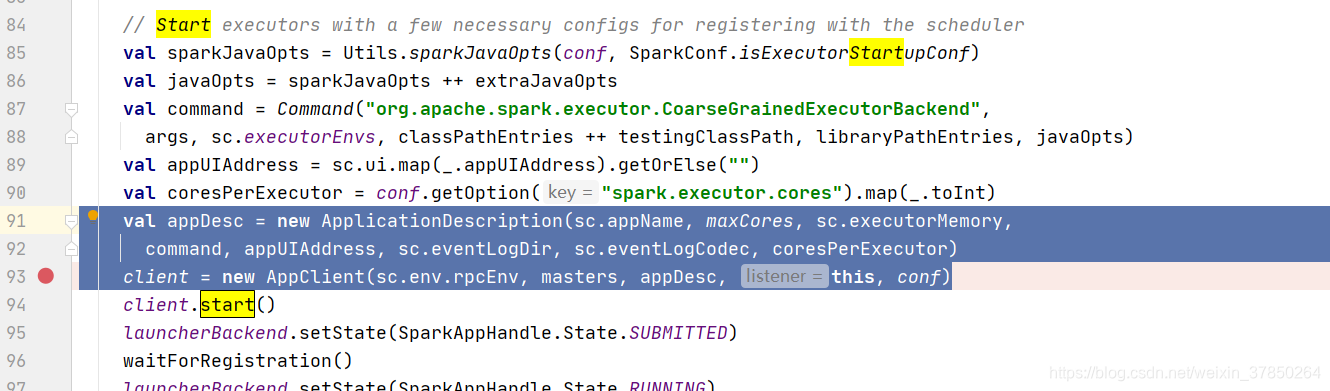 这个applicationDescription,它就是代表了当前执行application的一些情况,包括最大需要多少个core,每个slave需要多少个内存; 其次创建了一个appclient,1.6之前是akka,后面版本是netty,它是一个接口,负责为application与spark集群进行通信,它会接收一个spark master的url,以及一个applicationDescription,和一个集群监听器,以及各种事件发生时监听器;
这个applicationDescription,它就是代表了当前执行application的一些情况,包括最大需要多少个core,每个slave需要多少个内存; 其次创建了一个appclient,1.6之前是akka,后面版本是netty,它是一个接口,负责为application与spark集群进行通信,它会接收一个spark master的url,以及一个applicationDescription,和一个集群监听器,以及各种事件发生时监听器; 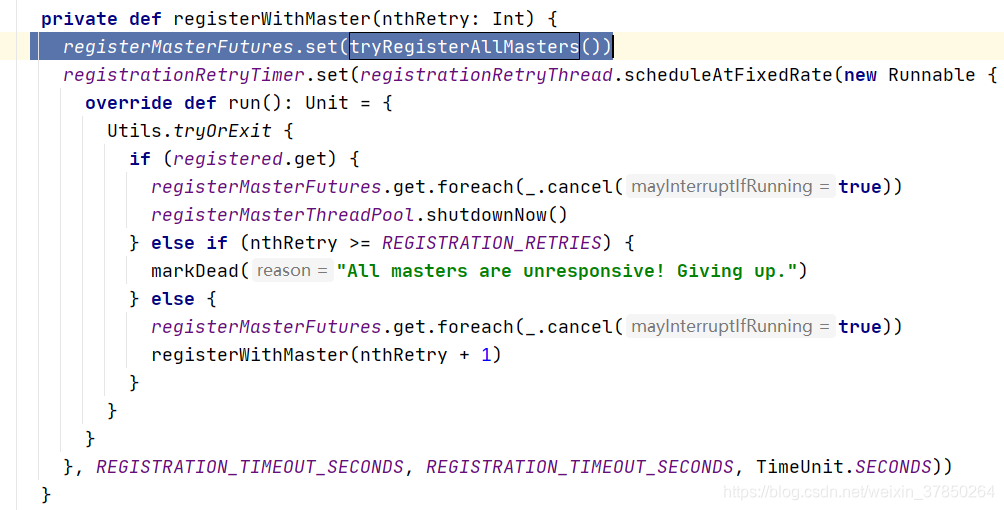
发布日期:2021-11-18 17:47:12
浏览次数:10
分类:技术文章
本文共 1975 字,大约阅读时间需要 6 分钟。
文章目录
一、sparkcontext整体架构
Taskscheduler:
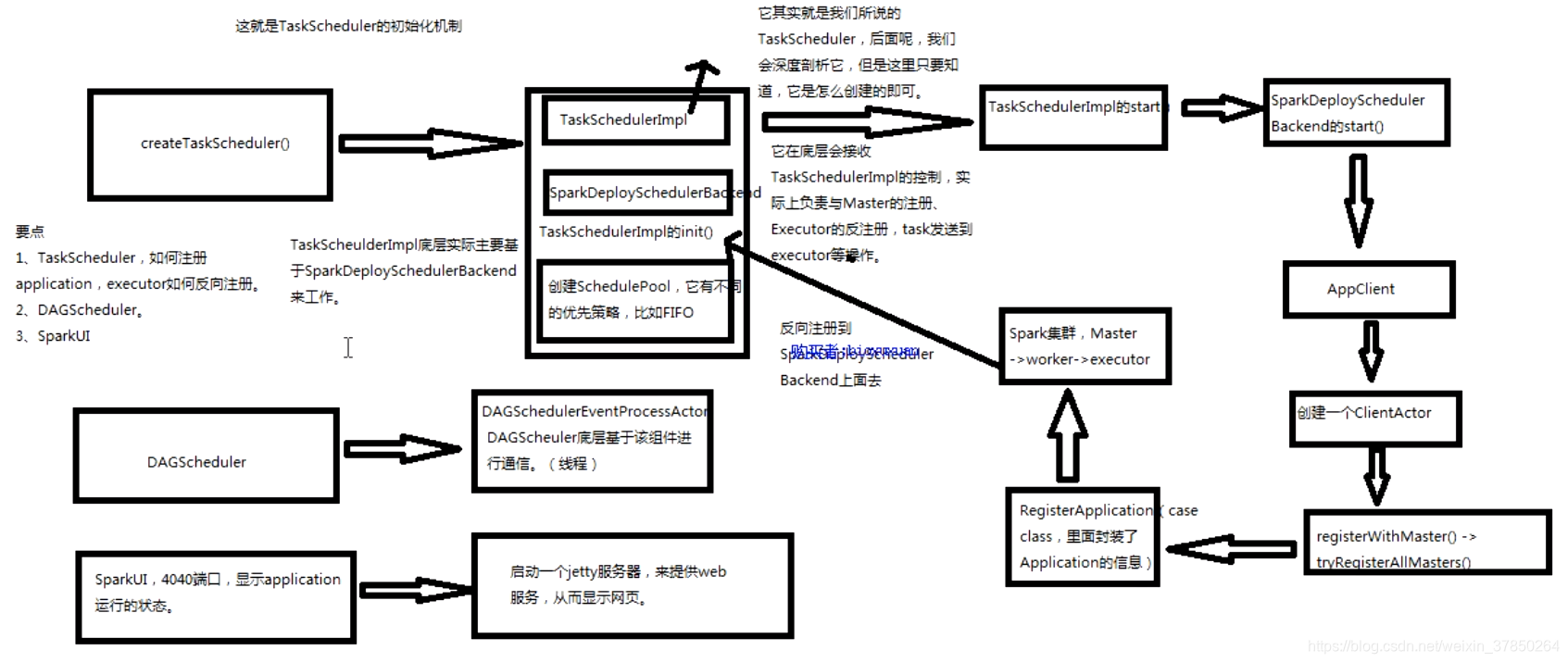
- createTaskscheduler():1.会创建一个TaskschedulerImpl:它其实就是一个Taskscheduler;2.也会创建一个SparkDeploySchedulerBackend:它在底层会接收TaskScheduler的控制,实际上负责与master的注册,executor的反注册,task发送到executor等;3.会调用taskschedulerImp的init()方法:创建一个schedulerPool,它有不同的优先策略,比如FIFO,Capacity,Fair等;
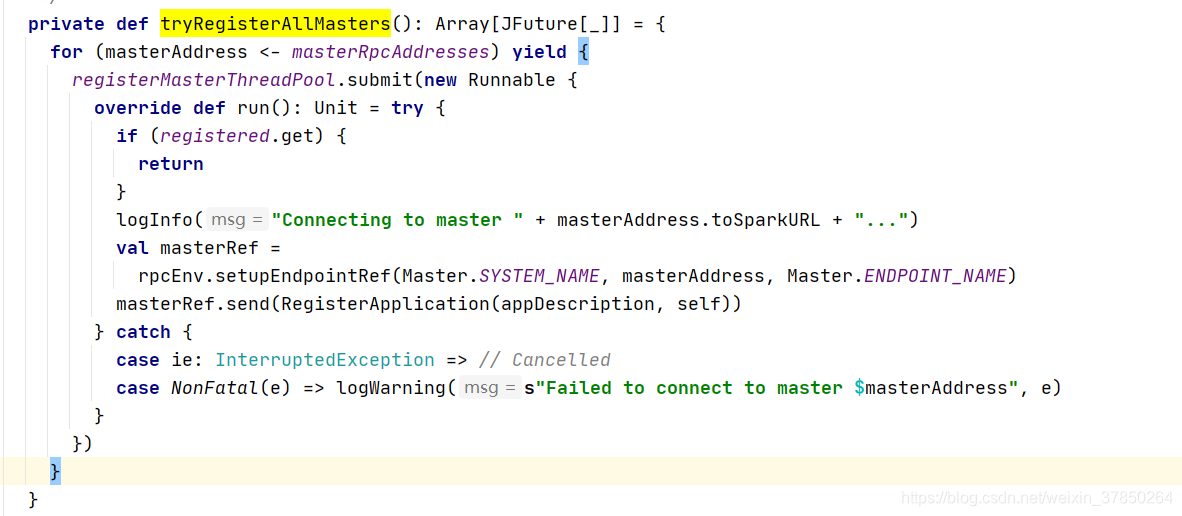
- 创建后TaskschedulerImpl后,会调用TaskschedulerImpl的start()方法,在其方法内部又会调用SparkDeploySchedulerBackend的start(); 同理,在其方法创建一个AppClient, 会在Appclient创建一个ClientActor线程,在线程里面会调用两个方法,registerWithMaster->tryRegisterAllMasters();这两个master会向Master发送一个RegisterApplication(是一个case class,里面封装了Application的信息)
- Spark集群,Master接收到RegisterApplication,在worker中找到executor,反向注册到SparkDeploySchedulerBackend上面去;
Tip:TaskSchedulerImpl底层主要基于SparkDeploySchedulerBackend来工作;
DAGScheduler
- DAGSchedulerEventProcessActor:DAGScheduler底层基于该组件进行通信(线程)
SparkUI:
- 4040端口,显示application运行状态,启动一个jetty服务器,来提供web服务,从而显示到网页
基本流程如下:
二、核心源码:
创建sparkcontext对象之后,会在里面调用sparkcontext的createTaskScheduler()和创建一个DAGScheduler对象;
1.TaskScheduler
1.SparkContext调用createTaskScheduler后,针对不同种类的deploy(standalone,yarn,mesos),首先先创建TaskSchedulerImpl,再生成一个SparkDeploySchedulerbackend();然后调用TaskSchedulerImpl对象的初始化方法;
2.TaskSchedulerImpl对象的初始化方法主要是新建了一个调度线程池 3.Taskscheduler对象开始运行start()方法;注意其start方法其实是调用sparkdeployschedulerbackend的start()方法, 而在sparkdeployschedulerbackend的start方法中主要就是做了以下两个工作: 这个applicationDescription,它就是代表了当前执行application的一些情况,包括最大需要多少个core,每个slave需要多少个内存; 其次创建了一个appclient,1.6之前是akka,后面版本是netty,它是一个接口,负责为application与spark集群进行通信,它会接收一个spark master的url,以及一个applicationDescription,和一个集群监听器,以及各种事件发生时监听器; 2.DAGScheduler:
1.实现了面向stage的调度机制的高层次调度层。它会为每个job计算一个关于stage的DAG(有向无环图),追踪RDD和stage的输出是否物化了(物化就是说,写入了磁盘或者内存等地方),并且寻找一个最小消耗(最优,最小)调度机制来运行job。
2.它会将stage作为taskset提交到底层的TaskSchedulerImpl上,并在集群运行它们(task). 3.除了除了stage的DAG,它还负责决定运行每个task的最佳位置,基于当前的缓存状态,将这些最佳位置提交给底层的TaskSchedulerImpl。此外,它还会处理由于shuffle输出文件丢失导致的失败,在这种情况下,旧的stage可能hi被重新提交。一个stage内部的失败,如果不是由于shuffle文件丢失锁导致的失败,会被Taskscheduler处理,它会被多次尝试每一个task,直到最后超过最大尝试次数,才回去取消整一个stage;
转载地址:https://blog.csdn.net/weixin_37850264/article/details/111941329 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
路过,博主的博客真漂亮。。
[***.116.15.85]2024年04月05日 02时52分36秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
段永平大佬!
2019-04-26
mysql-connector-java与Mysql、Java的对应版本
2019-04-26
移动2020面试题:斗地主
2019-04-26
MySQL 表锁、行锁、间隙锁、页锁介绍分析
2019-04-26
codeforces 789A(数学)
2019-04-26
Codeforces 796A
2019-04-26
dp46上 HDU2084
2019-04-26
dp46上 HDU1421
2019-04-26
UESTC 1324线段树
2019-04-26
POJ1651 区间dp
2019-04-26
spfa、Dijkstra、Floyd算法最短路算法详解
2019-04-26
HDU4725(spfa+双端队列优化)
2019-04-26
PowerOj 2392(树状数组 or CDQ分治)
2019-04-26
HDU 6119(区间交叉问题)
2019-04-26
hdu 6143(精妙的递推)
2019-04-26
数位dp
2019-04-26
Power oj 2540 (FFT卷积)
2019-04-26
hdu 6165(dfs or bfs or tarjan+topsort)
2019-04-26
hdu 6168(stl)
2019-04-26
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 307332030 位访客
访问时间: 2024-04-23 23:45:24
访问IP: 3.21.231.245
Copyright © 2020 - 2023 blog.css8.cn 京ICP备2021015314号-1
手机版