Spark源码(二)——依赖剖析
发布日期:2021-11-18 17:47:11
浏览次数:11
分类:技术文章
本文共 551 字,大约阅读时间需要 1 分钟。
文章目录
一、窄依赖
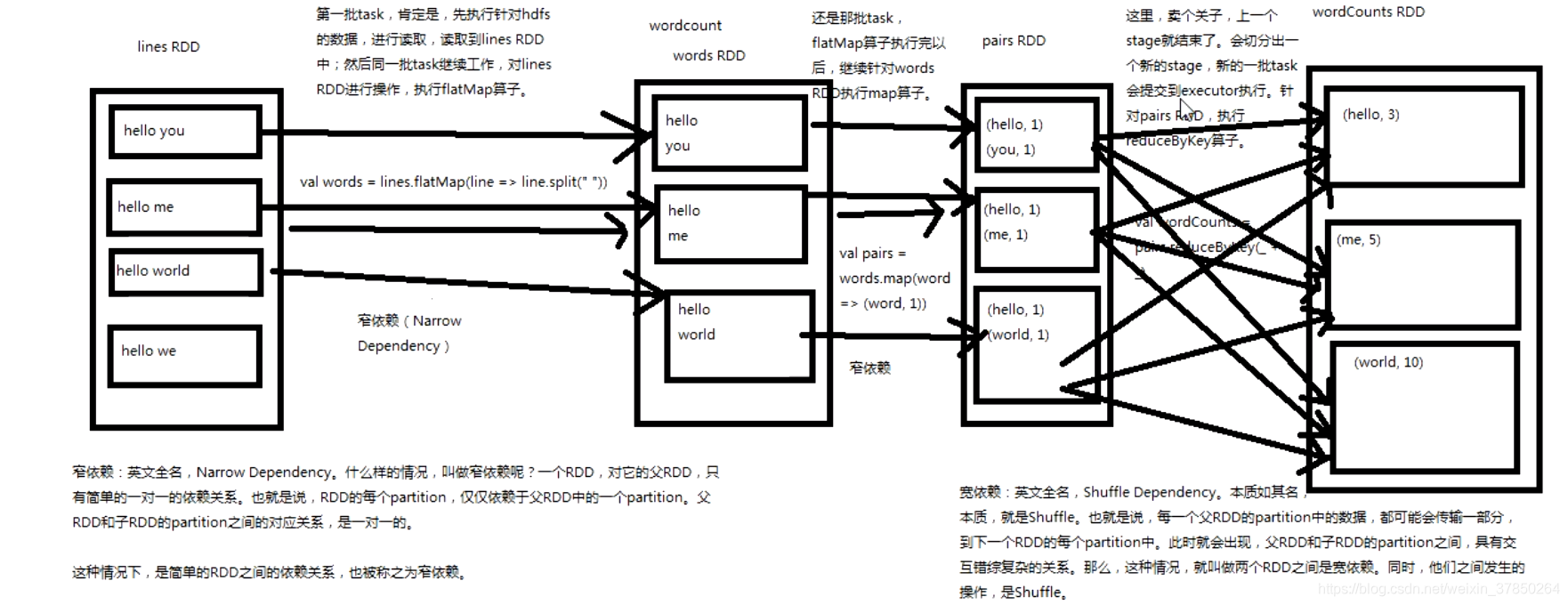
narrow dependecy,一个RDD,对它的父RDD,只有简单的一对一依赖关系,也就是说,RDD的每一个partition仅仅依赖于父RDD中的一个partiotion,父RDD和子RDD的partiotion之间的对应关系是一对一的;
二、宽依赖
shuffle dependency, 本质如其名,就是shuffle,也就是说,每一个父RDD的partition中的数据,都可能传输到下一个RDD的每一个partition中,此时就会出现,父RDD和子RDD的partition之间具有交错复杂的关系,那么这种情况就叫做两个RDD之间的宽依赖,同时他们之间发生的操作称之为shuffle;
融合到前面的架构
- 第一批task,肯定是,先执行针对hdfs的数据,进行读取,读取到lines RDD中,然后同一批task继续工作,对lines RDD进行操作,执行flatmap算子
- 还是那批task,flatmap算子执行完以后,继续针对words RDD执行map算子,生成Paris RDD;
- 上一个stage就结束了,会切分出一个新的stage,新的一批task会提交到executor执行,针对Paris RDD,执行reducebykey算子; 以下是工作流程:
转载地址:https://blog.csdn.net/weixin_37850264/article/details/111938183 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
初次前来,多多关照!
[***.217.46.12]2024年04月12日 06时40分02秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
HashMap的有关知识点大综述
2021-06-29
【面试篇】Java容器面试大集合
2021-06-29
【Linux篇】Linux常用命令之性能优化
2021-06-29
【Leetcode刷题篇】leetcode240 搜索二维矩阵II
2021-06-29
【Leetcode刷题篇】Leetcode714 买卖股票的最佳时机含手续费
2021-06-29
【Leetcode刷题篇】leetcode123 买卖股票的最佳时机 III
2021-06-29
【Leetcode刷题篇】leetcode188 买卖股票的最佳时机IV
2021-06-29
【Leetcode刷题篇/面试篇】经典动态规划-买卖股票问题总结汇总
2021-06-29
【Java锁体系】五、隐式锁和显式锁的区别(Synchronized和Lock的区别)
2021-06-29
【Java锁体系】七、JMM内存模型详解
2021-06-29
【Java锁体系】八、MESI缓存一致性协议讲解
2021-06-29
【面试篇】Java锁体系
2021-06-29
【面试篇】JVM体系
2021-06-29
【Leetcode刷题篇】leetcode406 根据身高重建队列
2021-06-29
【Leetcode刷题篇】leetcode581 最短无序连续子数组
2021-06-29
【Leetcode刷题篇】leetcode538 把二叉搜索树转换为累加树
2021-06-29
【多线程与高并发】线程的优先级是怎么回事?
2021-06-29
【多线程与高并发】Java守护线程是什么?什么是Java的守护线程?
2021-06-29
【Leetcode刷题篇/面试篇】-前缀树(Trie)
2021-06-29
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 306296424 位访客
访问时间: 2024-04-19 21:32:50
访问IP: 3.135.200.211
Copyright © 2020 - 2023 blog.css8.cn 京ICP备2021015314号-1
手机版