本文共 1739 字,大约阅读时间需要 5 分钟。
上回书说道收缩数据库时,采用了一个比较粗暴的办法,直接新建库,然后复制表结构。因为是测试环境,所以操作没问题。
但是,建了数据库以后,发现输入插入中文的数据都变成乱码了。
这肯定是字符集有问题。可以变更数据库字符集来解决,怎么变更字符集呢?
根据网上找的资料,变更数据库Collocation,也就是中文版SQL SERVER中数据库-右键-属性-选项中的排序规则,选为中文,也就是Chinese_PRC_CI_AS
网上的解释是:
-------------------------------------------------------------------------------------------------------------------------------------
参数解释如下:
前半部份:指UNICODE字符集,Chinese_PRC_指针对大陆简体字UNICODE的排序规则。
排序规则的后半部份即后缀 含义:
_BIN 二进制排序
_CI(CS) 是否区分大小写,CI不区分,CS区分
_AI(AS) 是否区分重音,AI不区分,AS区分
_KI(KS) 是否区分假名类型,KI不区分,KS区分
_WI(WS) 是否区分宽度WI不区分,WS区分
区分大小写:如果想让比较将大写字母和小写字母视为不等,请选择该选项。
区分重音:如果想让重音和非重音字母视为不等,请选择该选项。如果选择该选项,
比较还将重音不同的字母视为不等。
区分假名:如果想让比较将片假名和平假名日语音节视为不等,请选择该选项。
区分宽度:如果想让比较将半角字符和全角字符视为不等,请选择该选项。
---------------------------------------------------------------------------------------------------
设置完成后,并没有起作用,发现新增的数据中文还是乱码的。
是不是需要重启SQL SERVER服务才生效呢?
重启完还是不行。
也可以通过改变字段,原有的varchar改为nvarchar。改完以后,发现新增的数据变成中文的了。这也算是解决了吧。
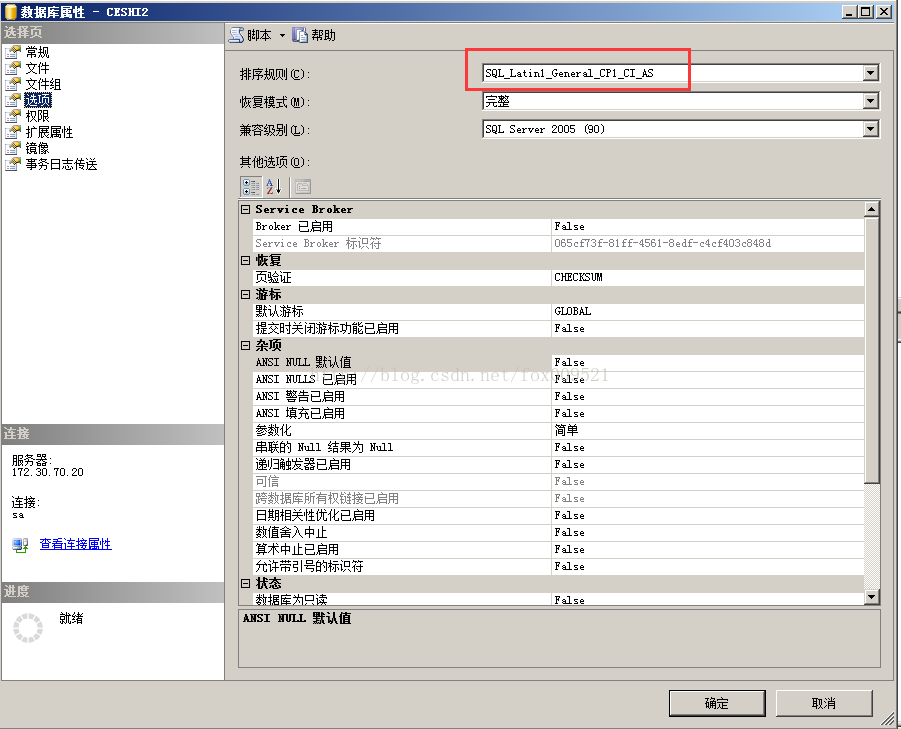
后来想了一下,会不会是新建的数据库默认排序规则是SQL_Latin1_General_CP1_CI_AS,所以会出现乱码的情况呢?
测试了一下,先新建了一个库,没有指定排序规则,默认就是SQL_Latin1_General_CP1_CI_AS。
新建了两个表,插入一个中文数据,看了下。
CREATE TABLE T_TMP(F_CONTENT VARCHAR(2000)) INSERT INTO T_TMP (F_CONTENT) VALUES('测试') select * from T_TMP CREATE TABLE T_TMP1(F_CONTENT NVARCHAR(2000)) INSERT INTO T_TMP1 (F_CONTENT) VALUES('测试') select * from T_TMP1 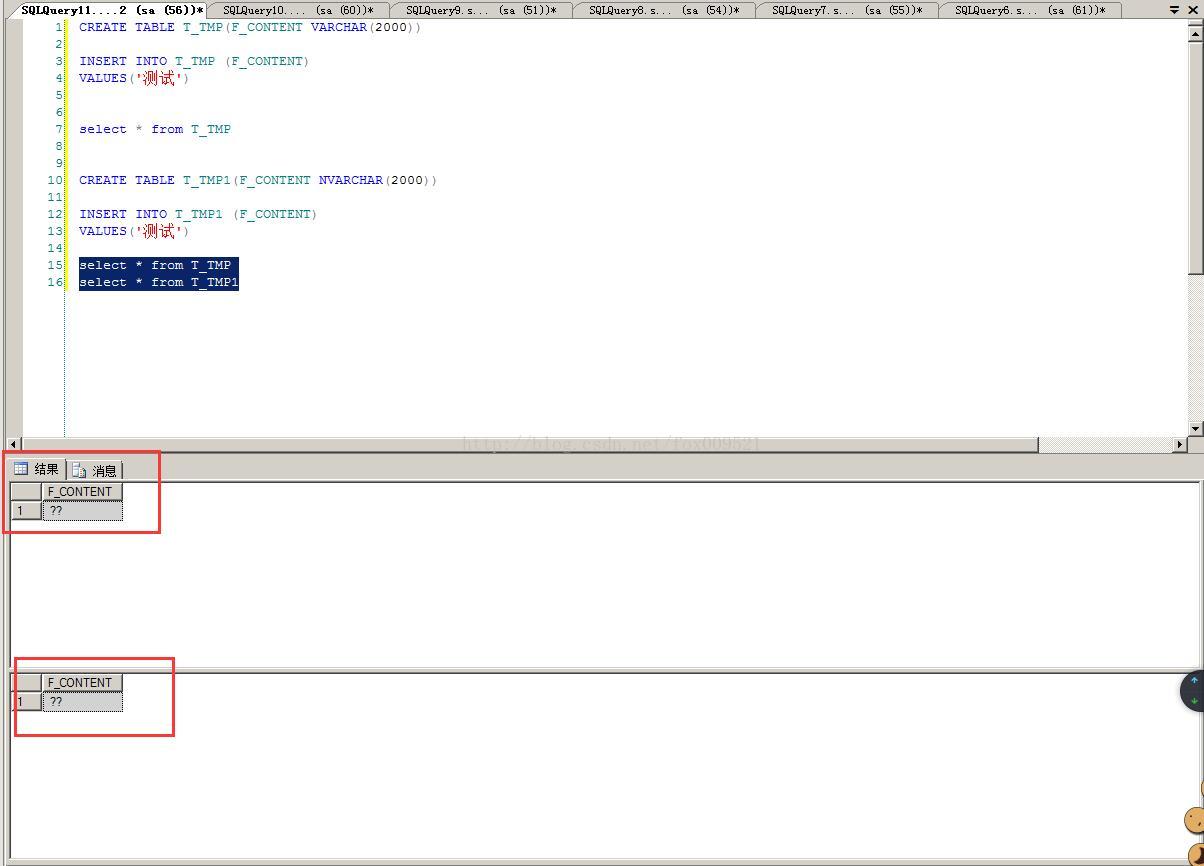
果然都是乱码的。
看来以后,新建数据库的时候,还是要注意字符集的问题呀。
暂且记录下来,以后可不能犯傻了。
知行办公,专业移动办公平台 https://zx.naton.cn/ 【总监】十二春秋之,3483099@qq.com; 【Master】zelo,616701261@qq.com; 【运营】运维艄公,897221533@qq.com; 【产品设计】流浪猫,364994559@qq.com; 【体验设计】兜兜,2435632247@qq.com; 【】淘码小工,492395860@qq.com;iMcG33K,imcg33k@gmail.com; 【】人猿居士,1059604515@qq.com;思路的顿悟,1217022114@qq.com; 【java】首席工程师MR_W,feixue300@qq.com; 【测试】土镜问道,847071279@qq.com; 【数据】fox009521,42151960@qq.com; 【安全】保密,你懂的。
转载地址:https://blog.csdn.net/fox009521/article/details/78285253 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
