本文共 7499 字,大约阅读时间需要 24 分钟。
Fast Single Image Rain Removal via a Deep Decomposition-Composition Network
[paper]
我的博客尽可能提取文章内的主要传达的信息,既不是完全翻译,也不简单粗略。论文的motivation和网络设计细节,将是我写这些博客关注的重点。
目录
Abstract
This paper designs a novel multi-task leaning architecture in an end-to-end manner to reduce the mapping range from input to output and boost the performance. Concretely, a decomposition net is built to split rain images into clean background and rain layers. Different from previous architectures, our model consists of, besides a component representing the desired clean image, an extra component for the rain layer. During the training phase, we further employ a composition structure to reproduce the input by the separated clean image and rain information for improving the quality of decomposition.
本文设计的是一个双任务学习 框架。分解网络学习去雨图像和雨滴图像。合成网络学习雨图合成。
Introduction
Previous Arts and Challenges
From the perspective of required input amount, existing rain removal methods can be divided into two classes, i.e. multi-image based and single image based methods. Early attempts on deraining basically belong to the former category.
The work in [7] employs two constraints to automatically find and exclude possible rain streaks, and then fills up the holes by averaging the values of their temporal neighbors, which releases the professional requirement. Several follow-ups along this technique line including [30] and [26] try to improve the accuracy of rain streak detection or/and the quality of background inpainting.
A more elaborated review on the multi-image based rain streak removal approaches can be found in [20]. Generally, this kind of methods can provide reasonable results when the given information is of sufficient redundancy, but this condition is often violated in practice.
去雨算法分为多幅图像和单图像两类。 一种多幅图像去雨方法是将雨迹识别然后扣除,然后用邻近背景均值填补。
给定足够信息,这种方法效果还好,但往往不太可能。
These prior-based methods even with the help of trained dictionaries/GMMs, on the one hand, are still unable to catch sufficiently distinct features for the background and rain layers. On the other hand, their computational cost is way too huge for practical use.
基于先验知识的单幅图像去雨算法也存在很多问题。。。
deep detail network (DDN)
convolutional neural network (CNN) based method to jointly detect and remove rain streaks from a single image (JORDER)
image deraining conditional general adversarial network (ID-CGAN)
以上是几个基于深度学习的单幅图像去雨算法。
Though the deep learning based strategies have made a great progress in rain removal compared with the traditional methods, two challenges still remain:
• How to enhance the effectiveness of deep architectures for better utilizing training data and achieving more accurate restored results;
• How to improve the efficiency of processing testing images for fulfilling the high-speed requirement in real-world (realtime) tasks.
两个challenges:有效去雨,快速去雨。(感觉废话。)
Our Contributions
1. deep decomposition-composition network (DDC-Net)
decomposition net is built for splitting rainy images into clean background and rain layers. The volume of model is retained small with promising performance. Hence, the effectiveness of the architecture is boosted.
composition net is for reproducing input rain images by the separated two layers from the decomposition net, aiming to further improve the quality of decomposition.
2. According to the screen blending mode, instead of the simple additive blending, we synthesize a training dataset containing 10, 400 triplets [rain image, clean background, rain information].
3. Experimental results on both synthetic and real images are conducted to reveal the high-quality recovery by our design, and show its superiority over other state-of-theart methods. Our method is signifficantly faster than the competitors, making it attractive for practical use. All the trained models and the synthesized dataset are available at https://sites.google.com/view/xjguo.
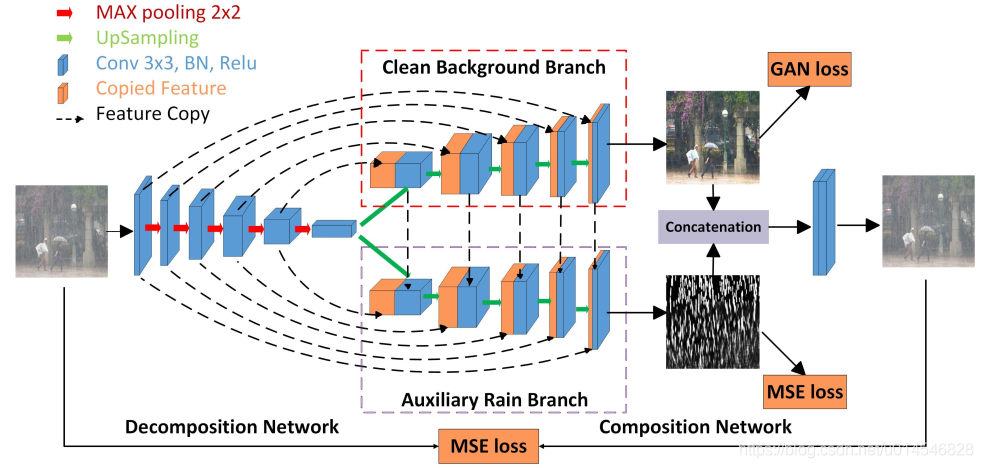
Deep Decomposition-Composition Network (DDC-Net)
Decomposition Net
decomposition branch based on the residual encoder and decoder architecture with specific designs for clean background and rain layer prediction as follows:
1) the first two convolutional layers in the encoder are changed to dilated convolution [24] to enlarge the receptive field. The stride of our dilated convolutional layer is 1 × 1 with padding. We use max-pooling to down-sample feature maps;
2) we use two decoder networks (clean background branch and auxiliary rain branch) to recover the clean background and rain layer respectively; and
3) features from the deconvolution module of the clean background branch are concatenated to the auxiliary rain branch for better obtaining rain information during the up-sampling stage (the downward arrows). The principle behind is that the background features are expected to help exclude textures belonging to the background from the rain part.
4) It is worth to note that we have tried to feed rain features into the background branch, but this operation did not show noticeable improvement on performance. The reason is that since the rain textures are typically much simpler and more regular than the background textures, the improvement is not obvious or negligible.
Decomposition Net 包括四个内容解释:
1)encoder的前两层采用了膨胀卷积,卷积核1x1,padding就应该和dilation相同。下采样用的是max-pooling。
2)两个分支完成两个任务。
3)背景分支的特征图要 channel 相加到雨滴分支,但
4)雨滴分支的特征图不与背景分支共享。
5)encoder和decoder都为降维5层。
后面是本文的一大特点,即用人工合成的图片作为预训练,而真实的配对的雨图与无语图作为fine-tune训练,对参数进行微调。
Pre-train on synthetic images:
Since the decomposing problem is challenging without paired supervision, a model can learn arbitrary mapping to the target domain and cannot guarantee to map an individual input to its desired clean background and rain layers. Therefore, we first cast the image deraining problem as a paired image-to-image mapping problem.
The losses of clean background and rain layer in the decomposition in the pre-training stage:
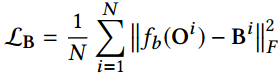
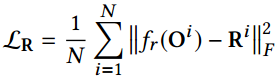
B表示去雨图像,R表示雨滴图像,O是雨图像。
注意,与结构图上给的不一样哦:从这段文字推断,预训练只用了这两个L2 loss。具体看代码有没有用GAN loss,还要参考代码。
Fine-tune on real images:
as the synthetic rain layer cannot distinguish the effect of attenuation and splash in real scene radiance, we use some collected real rain-free and rainy images to fine-tune our model.
generative adversarial network GAN loss
之所以要采用两步训练,是因为文章认为,人工合成的雨图并不能代表真实的雨图。所以,单一的用人工合成图像训练模型的参数不准确,需要用真实雨图进行参数微调,自监督训练。
Composition Net
Our composition net aims to learn the original rainy image from the outputs of decomposition model, then use the constructed rainy image as the self-supervised information to guide the backpropagation.
合成网络的目的是,将分解网络得到的去雨图像和雨滴图像合成雨图像,作为自监督信息来引导反向传播。
concatenate the clean background image and the rain layer from the decomposition network, and then adopt an additional CNN block to model the real rainy image formulation. The proposed composition network could achieve a more general formation process and accounts for some unknown phenomenon in real images.
合成方法是:concatenate分解的两个输出,即去雨图像和雨滴图像,然后通过一个CNN 层。这么做的原因是,雨图 生成模型并不能完全反应真实雨图的形成物理机制,所以用CNN学习复杂且不知道的雨图形成物理过程。
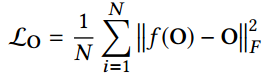
O是原雨图像,f(O)是生成的雨图像。
Training Dataset
本文用的人工合成雨图也不是简单的相加模型,而是screen mode:
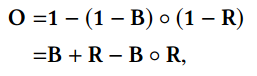
clean background images B are from BSD300 dataset . Moreover, the rain part R is generated following the steps with varying intensities, orientations and overlaps.
无雨图像是从BSD300数据集获得,雨滴图R是经过改变强度、方向和重叠操作后得到。
BSD300: https://www2.eecs.berkeley.edu/Research/Projects/CS/vision/bsds/
varying method: http://www.photoshopessentials.com/photo-effects/rain/
我的笔记
这篇文章有两个学习点:
1. 多任务模型。
适用于一次完两张或者多张图像的生成任务。
2. 两次训练模型。
适用于人工合成图像与真实图像并不完全吻合的应用场景。同时,需要两个数据集:人工合成数据集(大量,预训练);真实配对的数据集(少量,微调,多任务时至少有一个标签) 。
转载地址:https://blog.csdn.net/u014546828/article/details/101177034 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
