本文共 12240 字,大约阅读时间需要 40 分钟。
目录
正则表达式语法
1、正则表达式定义了字符串的模式,可以用来搜索、编辑或处理文本。
2、正则表达式并不仅限于某一种语言,基本上每一种编程语言都会有,语法规则基本一致,只是使用上稍有差别。
3、Java 正则表达式主要使用 java.util.regex 包下的三个类:
| Pattern | Pattern 对象表示一个正则表达式的匹配模式,调用其公共静态编译方法返回一个 Pattern 对象。 |
| Matcher | Matcher 对象是对输入字符串进行解释和匹配操作的引擎,调用 Pattern 对象的 matcher 方法可以获得 Matcher 实例 |
| PatternSyntaxException | 表示一个正则表达式模式(Pattern)中的语法错误。 |
4、Java 正则表达式中 "\" 表示转义字符,其后的字符具有特殊的意义,如 "\\d" 用于表示数字字符匹配,等效于 [0-9]
| 字符 | 说明 |
|---|---|
| \ | 将下一字符标记为特殊字符、文本、反向引用或八进制转义符。如"n"匹配字符"n","\n"匹配换行符,序列"\\\\"匹配"\\". |
| ^ | 匹配输入字符串开始的位置。 |
| $ | 匹配输入字符串结尾的位置。 |
| * | 匹配前面的字符或子表达式出现零次或多次。如,zo* 匹配 "z" 和 "zoo",* 等效于 {0,}。 |
| + | 匹配前面的字符或子表达式出现一次或多次。如,zo+ 与"zo"和"zoo"匹配,但与"z"不匹配,+ 等效于 {1,}。 |
| ? | 匹配前面的字符或子表达式零次或一次。如 do(es)? 匹配 "do" 或 "does" 中的 "do"。? 等效于 {0,1}。 |
| { n} | n 是非负整数,正好匹配 n 次。例如,"o{2}" 与 "Bob" 中的 "o" 不匹配,但与 "food" 中的两个 "o" 匹配。 |
| { n,} | n 是非负整数,至少匹配 n 次。例如,"o{2,}" 不匹配 "Bob" 中的 "o",而匹配 "foooood" 中的所有 o。 |
| { n,m} | m 和 n 是非负整数,其中 n <= m,匹配至少 n 次,至多 m 次,例如 "o{1,3}" 匹配 "fooooood" 中的头三个 o。 |
| . | 匹配除"\r\n"之外的任何单个字符。若要匹配包括"\r\n"在内的任意字符,请使用诸如"[\s\S]"之类的模式。 |
| (pattern) | 匹配 pattern 并捕获该匹配的子表达式,结合 group 可以取值。若要匹配括号字符 ( ),请使用"\("或者"\)"。 |
| x|y | 匹配 x 或 y,例如,'z|food' 匹配"z"或"food",'(z|f)ood' 匹配"zood"或"food"。 |
| [xyz] | 字符集,匹配包含的任一字符。例如,"[abc]" 匹配 "plain" 中的 "a"。 |
| [^xyz] | 反向字符集。匹配未包含的任何字符。例如,"[^abc]" 匹配 "plain" 中 "p","l","i","n"。 |
| [a-z] | 字符范围。匹配指定范围内的任何字符。例如,"[a-z]" 匹配 "a" 到 "z" 范围内的任何小写字母。 |
| [^a-z] | 反向范围字符。匹配不在指定的范围内的任何字符。例如,"[^a-z]"匹配任何不在"a"到"z"范围内的任何字符。 |
| \d | 数字字符匹配。等效于 [0-9]。后面没有指明个数时,默认都是 1. |
| \D | 非数字字符匹配。等效于 [^0-9]。 |
| \f | 换页符匹配。等效于 \x0c 和 \cL。 |
| \n | 换行符匹配。等效于 \x0a 和 \cJ。 |
| \r | 匹配一个回车符。等效于 \x0d 和 \cM。 |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等。与 [ \f\n\r\t\v] 等效。 |
| \S | 匹配任何非空白字符。与 [^ \f\n\r\t\v] 等效。 |
| \t | 制表符匹配。与 \x09 和 \cI 等效。 |
| \v | 垂直制表符匹配。与 \x0b 和 \cK 等效。 |
| \w | 匹配任何单词字符,包括下划线。与"[A-Za-z0-9_]"等效。 |
| \W | 与任何非单词字符匹配。与"[^A-Za-z0-9_]"等效。 |
Pattern 正则模式
1、指定为字符串的正则表达式必须首先被编译为此类的实例,然后可将得到的模式用于创建 Matcher(匹配器) 对象,依照正则表达式,该对象可以与任意字符序列匹配。执行匹配所涉及的所有状态都驻留在匹配器中,所以多个匹配器可以共享同一模式。
//匹配零个或多个数字 private static Pattern pattern0_9 = Pattern.compile("[0-9]*"); @org.junit.Test public void test1() { Matcher matcher1 = pattern0_9.matcher("314"); Matcher matcher2 = pattern0_9.matcher("3.14"); //matches:将整个目标字符序列与模式匹配,输出 true,false System.out.println(matcher1.matches()+","+matcher2.matches()); } 2、Patten 类定义了一个方法,以便在正则表达式只使用一次时调用,该方法编译一个表达式,并在单个调用中匹配输入序列:
//匹配大小写字母、数字、下划线 @Test public void test2() { //"\w"表示单词字符,即 大小写字母、数字、下划线,所以输出 true,false //matches 方法将整个整个字符串与模式进行匹配,匹配成功返回 true,否则 false boolean matches1 = Pattern.matches("\\w+", "Wmx_328");//第一个反斜杆是转义字符 boolean matches2 = Pattern.matches("\\w+", "Wmx3.28"); System.out.println(matches1 + "," + matches2); } 类是线程安全的,类不是线程安全的。
static ( regex) | 将给定的正则表达式编译为模式 |
( input) | 创建一个匹配器,匹配给定的输入与此模式 |
static boolean ( regex, input) | 编译给定的正则表达式,并尝试匹配给定的输入 |
[] ( input) | 将给定的输入序列用正则模式进行匹配分割,未匹配上时,返回整个目标字符串 |
[] ( input, int limit) | 限制匹配次数为 limit -1 次,负数和0表示不做限制. |
3、compile(String regex) 与 matcher(CharSequence input)方法上面已经做了简单的演示,下面演示 split 方法,其实它
private static Pattern pattern_ = Pattern.compile("_"); @Test public void test3() { String input = "89U_78P_G67-8P_长城"; //使用正则模式对目标字符串进行分割,limit=0 等同于 split(input) // limit=2实质是分割一次,匹配一次后不再进行匹配分割 String[] split1 = pattern_.split(input); String[] split3 = pattern_.split(input, 0); String[] split2 = pattern_.split(input, 2); System.out.println(Arrays.asList(split1));//[89U, 78P, G67-8P, 长城] System.out.println(Arrays.asList(split2));//[89U, 78P_G67-8P_长城] System.out.println(Arrays.asList(split3));//[89U, 78P, G67-8P, 长城] } Matcher 匹配器
查找方法
1、可以通过调用 Pattern 的 matcher 方法创建匹配器,matcher 查找方法如下:
| boolean lookingAt() | 尝试将从区域开头开始的输入序列与该模式匹配。即从头开始匹配,只要头部一部分匹配上就行,不需要整个匹配. |
| boolean find() | 尝试查找与该模式匹配的输入序列的下一个子序列。即只要其中一部分能匹配上,就返回 true。 |
| boolean find(int start) | 重置此匹配器,然后尝试查找匹配该模式、从指定索引开始的输入序列的下一个子序列。 |
| boolean matches() | 尝试将整个区域与模式匹配。即必须全部匹配才返回 true. |
private static Pattern pattern_a_z = Pattern.compile("[a-z]+"); @Test public void test4() { Matcher matcher1 = pattern_a_z.matcher("123"); Matcher matcher2 = pattern_a_z.matcher("span123"); Matcher matcher3 = pattern_a_z.matcher("span"); //输出:false,false,true System.out.println(matcher1.matches() + "," + matcher1.lookingAt() + "," + matcher1.find()); //输出:true,false,true System.out.println(matcher2.find() + "," + matcher2.matches() + "," + matcher2.lookingAt()); //输出:true System.out.println(matcher3.matches()); } 索引方法
2、matcher 索引方法可以获取匹配位置的索引:
| int start() | 返回上一个匹配的起始索引 |
| int start(int group) | 返回在上一个匹配操作期间,由给定组所捕获的子序列的初始索引 |
| int end() | 返回最后一个字符匹配后的偏移量。 |
| int end(int group) | 返回在上一个匹配操作期间,由给定组所捕获子序列的最后字符之后的偏移量。 |
private static Pattern pattern_a_z = Pattern.compile("[a-z]+"); @Test public void test5() { Matcher matcher = pattern_a_z.matcher("2020 i love you! 0329"); while (matcher.find()) { /*输出: start=5,end=6 start=7,end=11 start=12,end=15 */ System.out.println("start=" + matcher.start() + ",end=" + matcher.end()); } } 替换方法
3、matcher 替换方法可以对匹配的部分进行替换:
| Matcher appendReplacement(StringBuffer sb, String replacement) | 实现非终端添加和替换步骤。 |
| StringBuffer appendTail(StringBuffer sb) | 实现终端添加和替换步骤。 |
| String replaceAll(String replacement) | 替换匹配到的输入字符串中的每个子序列。 |
| String replaceFirst(String replacement) | 替换匹配到的输入字符串中的第一个子序列。 |
| static String quoteReplacement(String s) | 返回指定字符串的字面替换字符串。这个方法返回一个字符串,就像传递给Matcher类的appendReplacement 方法一个字面字符串一样工作。 |
//[] 表示字符集,匹配其中包含的任一字符 private static Pattern pattern_code = Pattern.compile("[<>\\w'/=:]"); @Test public void test6() { String input = "万里长城"; Matcher matcher = pattern_code.matcher(input); //替换匹配到的所有子序列为空,输出:find = true, 万里长城 boolean find = matcher.find(); String replaceAll = matcher.replaceAll(""); System.out.println("find = " + find + "," + replaceAll); //重置匹配器,重新开始匹配 matcher.reset(); //注意:虽然 matchers 返回 false,但是对于匹配上的目标照样能进行替换 //输出:matches = false, 万里长城 boolean matches = matcher.matches(); String replaceAll2 = matcher.replaceAll(""); System.out.println("matches = " + matches + "," + replaceAll2); //replaceFirst:只替换匹配的第一个,输出:span style='color:red'>万里长城 System.out.println(matcher.replaceFirst("")); } group 捕获分组
1、Marcher 类中的 group(int group) 方法用于提取 (pattern) 中的值,这个括号起到一个分组的作用,一个括号分为一组,从左至右索引从 1 开始,如 group(1) 指的是第一个括号中 pattern 匹配的内容,group(2) 指的第二个括号,依此类推,group(0)则是所有括号匹配的值字符串拼接。
2、若要匹配括号字符 ( ),请使用"\("或者"\)" 进行转义,否则默认会被作为分组处理。
3、下面举一个非常应景的例子,做网络爬虫的时候,爬取下来的时间字符串通常不太规则,比如:
网易新闻文章的时间格式:2020-03-29 10:45:00 来源: 央视新闻客户端
搜狐新闻文章的时间格式:2020-03-29 13:40 来源:环球网 凤凰新闻文章的时间格式:2020年03月28日 20:08:23
显然如果我们想将爬取下来的文章的发布时间存储到自己的库中,则必须对它进行提取,利用 Matcher 的 goup 方法可以轻松的将其中的时间提取出来。
/**使用静态遍历加快编译速度,Pattern 类是线程安全的 * pattern1:提取 yyyy-MM-dd HH:mm:ss * pattern2:提取 yyyy-MM-dd HH:mm * pattern3:提取 yyyy-MM-dd */ private static Pattern pattern1 = Pattern.compile("[\\s\\W]*(\\d{4})[-年_\\s](\\d{1,2})[-月_\\s](\\d{1,2})[\\s\\W]*(\\d{1,2})[::时](\\d{1,2})[::分](\\d{1,2})[\\s\\W]*"); private static Pattern pattern2 = Pattern.compile("[\\s\\W]*(\\d{4})[-年_\\s](\\d{1,2})[-月_\\s](\\d{1,2})[\\s\\W]*(\\d{1,2})[::时](\\d{1,2})[\\s\\W]*"); private static Pattern pattern3 = Pattern.compile("[\\s\\W]*(\\d{4})[-年_\\s](\\d{1,2})[-月_\\s](\\d{1,2})[\\s\\W]*"); /** * 提取文本中的时间 * * @param input * @return */ public static Date parserDate(String input) { Date resultDate = null; try { //格式话日期 SimpleDateFormat dateFormat = new SimpleDateFormat("yyyyMMddHHmmss"); //无论哪个规则匹配上,都赋值给公共的 matcher,用于后续统一处理 Matcher matcher1 = pattern1.matcher(input); Matcher matcher2 = pattern2.matcher(input); Matcher matcher3 = pattern3.matcher(input); Matcher matcher = null; //注意只有先匹配上正则表达式,才能用 matcher.group 取值. if (matcher1.find()) { matcher = matcher1; } else if (matcher2.find()) { matcher = matcher2; } else if (matcher3.find()) { matcher = matcher3; } if (matcher != null) { //待取值的分组个数,值先用 list 存储 int groupCount = matcher.groupCount(); List dataList = new ArrayList<>(6); //注意 group 索引从1开始,按顺序匹配正则中的 () for (int i = 0; i < groupCount; i++) { String group = matcher.group(i + 1); //对于 月、天、时、分、秒 很可能出现单位数,如 2018-8-8 3:2:6,所以需要补齐 group = group.length() == 1 ? "0" + group : group; dataList.add(group); } //最后对于不满足 yyyyMMddHHmmss 的,比如 2018-8-8,后续统一用 00 代替 for (int j = dataList.size(); j < 6; j++) { dataList.add("00"); } //直接将 list 转字符串 [2020, 03, 29, 10, 45, 00],然后去掉其中不需要的字符 [、]、, 以及空格 String time = dataList.toString().replaceAll("[\\[\\],\\s]", ""); //最后解析成日期 resultDate = dateFormat.parse(time); } } catch (ParseException e) { e.printStackTrace(); } return resultDate; } public static void main(String[] args) { String input1 = "网易 2020-03-29 10:45:00 来源: 央视新闻客户端"; String input2 = "搜狐 2020-03-9 3:40 来源:环球网"; String input3 = "凤凰 2020年3月28日 20:8:23 "; String input4 = "腾讯 2020年1月8日 今天天气晴."; String input5 = "腾讯 2020年的1月8日号 今天天气晴.";//这个是匹配不上的 SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"); System.out.println(dateFormat.format(parserDate(input1)));//2020-03-29 10:45:00 System.out.println(dateFormat.format(parserDate(input2)));//2020-03-09 03:40:00 System.out.println(dateFormat.format(parserDate(input3)));//2020-03-28 20:08:23 System.out.println(dateFormat.format(parserDate(input4)));//2020-01-08 00:00:00 System.out.println(parserDate(input5));//null } 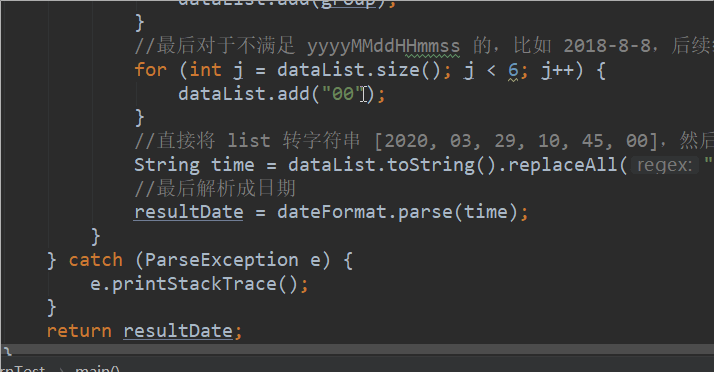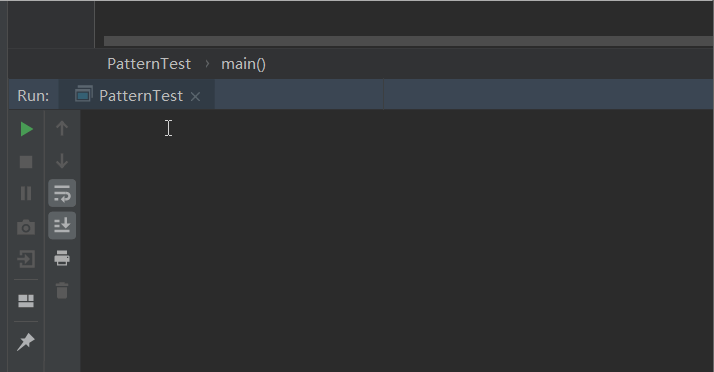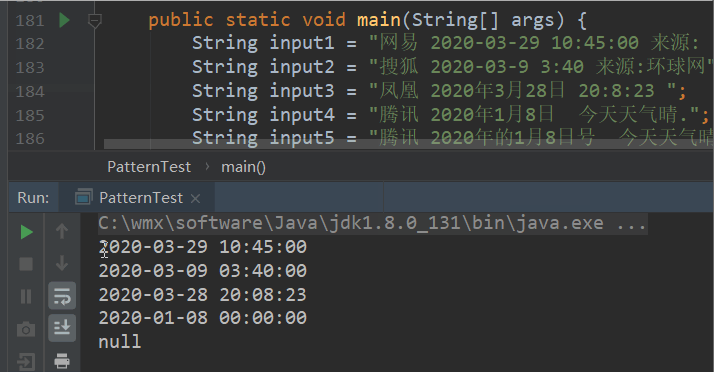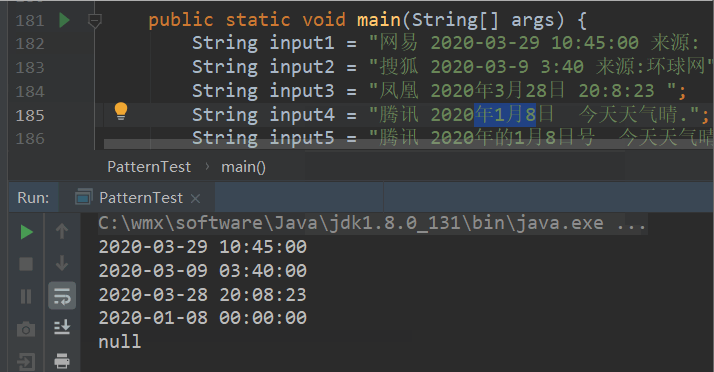
常用正则表达式
| 数字 | ^[0-9]*$ 或者 \d+ |
| 字母 | [a-zA-Z]+ |
| 中文汉字 | [\u4E00-\u9FFF]+ |
| IP v4 地址 | \b((?!\d\d\d)\d+|1\d\d|2[0-4]\d|25[0-5])\.((?!\d\d\d)\d+|1\d\d|2[0-4]\d|25[0-5])\.((?!\d\d\d)\d+|1\d\d|2[0-4]\d|25[0-5])\.((?!\d\d\d)\d+|1\d\d|2[0-4]\d|25[0-5])\b |
| IP v6 地址 | (([0-9a-fA-F]{1,4}:){7}[0-9a-fA-F]{1,4}|([0-9a-fA-F]{1,4}:){1,7}:|([0-9a-fA-F]{1,4}:){1,6}:[0-9a-fA-F]{1,4}|([0-9a-fA-F]{1,4}:){1,5}(:[0-9a-fA-F]{1,4}){1,2}|([0-9a-fA-F]{1,4}:){1,4}(:[0-9a-fA-F]{1,4}){1,3}|([0-9a-fA-F]{1,4}:){1,3}(:[0-9a-fA-F]{1,4}){1,4}|([0-9a-fA-F]{1,4}:){1,2}(:[0-9a-fA-F]{1,4}){1,5}|[0-9a-fA-F]{1,4}:((:[0-9a-fA-F]{1,4}){1,6})|:((:[0-9a-fA-F]{1,4}){1,7}|:)|fe80:(:[0-9a-fA-F]{0,4}){0,4}%[0-9a-zA-Z]+|::(ffff(:0{1,4})?:)?((25[0-5]|(2[0-4]|1?[0-9])?[0-9])\.){3}(25[0-5]|(2[0-4]|1?[0-9])?[0-9])|([0-9a-fA-F]{1,4}:){1,4}:((25[0-5]|(2[0-4]|1?[0-9])?[0-9])\.){3}(25[0-5]|(2[0-4]|1?[0-9])?[0-9])) |
| 手机号码 | (?:0|86|\+86)?1[3-9]\d{9} |
| 座机号码 | 0\d{2,3}-[1-9]\d{6,7} |
| 邮编,兼容港澳台 | ^(0[1-7]|1[0-356]|2[0-7]|3[0-6]|4[0-7]|5[0-7]|6[0-7]|7[0-5]|8[0-9]|9[0-8])\d{4}|99907[78]$ |
| 出生日期/生日 | ^(\d{2,4})([/\-.年]?)(\d{1,2})([/\-.月]?)(\d{1,2})日?$ |
| 汉字、英文字母、数字和下划线 | ^[\u4E00-\u9FFF\\w]+$ |
| 时分秒时间正则 | \d{1,2}:\d{1,2}(:\d{1,2})? |
| 社会统一信用代码 | ^[0-9A-HJ-NPQRTUWXY]{2}\d{6}[0-9A-HJ-NPQRTUWXY]{10}$ |
| 只能输入n位的数字 | ^\d{n}$ |
| 只能输入至少n位的数字 | ^\d{n,}$ |
| 只能输入[m,n]位的数字 | ^\d{m,n}$ |
| 只能输入整数或者有两位小数的正实数 | ^[0-9]+(\.[0-9]{2})?$ |
| 只能输入整数或者有1~3位小数的正实数 | ^[0-9]+(\.[0-9]{1,3})?$ |
| 只能输入非零的正整数 | ^\+?[1-9][0-9]*$ |
| 只能输入非零的负整数 | ^\-[1-9][0-9]*$ |
| 只能输入长度为3的字符 | ^.{3}$ //"."表示 任何字符,不需要转义 |
| 只能输入由数字和26个英文字母组成的字符串 | ^[A-Za-z0-9]+$ |
| 英文字母 、数字和下划线 | ^\w+$ |
| 以字母或下划线开头,只能包含字母、数字、下划线,长度为6~18 | ^[a-zA-Z_]\w{5,17}$ |
| 验证 Email 地址 | ^\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*$ 或者 (\\w|.)+@\\w+(\\.\\w+){1,2} |
| 广义 URL 地址 | [a-zA-z]+://[^\s]* |
| Http Url 地址 | (https://|http://)?([\w-]+\.)+[\w-]+(:\d+)*(/[\w- ./?%&=]*)? |
| 中国车牌号码(兼容新能源车牌) | ^(([京津沪渝冀豫云辽黑湘皖鲁新苏浙赣鄂桂甘晋蒙陕吉闽贵粤青藏川宁琼使领][A-Z](([0-9]{5}[ABCDEFGHJK])|([ABCDEFGHJK]([A-HJ-NP-Z0-9])[0-9]{4})))|([京津沪渝冀豫云辽黑湘皖鲁新苏浙赣鄂桂甘晋蒙陕吉闽贵粤青藏川宁琼使领]\d{3}\d{1,3}[领])|([京津沪渝冀豫云辽黑湘皖鲁新苏浙赣鄂桂甘晋蒙陕吉闽贵粤青藏川宁琼使领][A-Z][A-HJ-NP-Z0-9]{4}[A-HJ-NP-Z0-9挂学警港澳使领]))$ |
| 15、18 位 身份证号码校验 | (^[1-9]\d{5}\d{2}((0[1-9])|(10|11|12))(([0-2][1-9])|10|20|30|31)\d{3}$)|(^[1-9]\d{5}(18|19|([23]\d))\d{2}((0[1-9])|(10|11|12))(([0-2][1-9])|10|20|30|31)\d{3}[0-9Xx]$) |
| 18位身份证号码 | [1-9]\d{5}[1-2]\d{3}((0\d)|(1[0-2]))(([012]\d)|3[0-1])\d{3}(\d|X|x) |
转载地址:https://wangmaoxiong.blog.csdn.net/article/details/81076129 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
