本文共 10889 字,大约阅读时间需要 36 分钟。
背景
以官方例子为例,记录下如何使用oozie调度任务,首先进入oozie的解压根目录
调度普通任务
1、解压oozie根目录里的oozie-examples.tar.gz
# tar -zxvf oozie-examples.tar.gz
2、在oozie根目录新建目录,将解压得到的examples里的app/shell目录复制其中
# mkdir oozie-apps# cp -r examples/apps/shell/ oozie-apps/
3、切换到oozie-apps/shell目录下,编写待执行脚本p1.sh
# cd oozie-apps/shell/# vim p1.sh
p1.sh负责输出当前日期到指定文件
/sbin/date > /home/szc/p1.log
4、修改job.properties文件
# vim job.properties
将nameNode、jobTracker的ip换成自己的,修改exapmplesRoot和oozie.wf.application.path,定义变量EXEC为脚本在examplesRoot下的路径,这里就是p1.sh
nameNode=hdfs://192.168.57.141:8020jobTracker=192.168.57.141:8032queueName=defaultexamplesRoot=oozie-appsoozie.wf.application.path=${nameNode}/user/${user.name}/${examplesRoot}/shellEXEC=p1.sh 5、修改workflow.xml文件
# vim workflow.xml
start标签里定义shell-node结点就是任务的起点,所以我们修改shell-node结点,将exec标签修改为${EXEC},表示引用EXEC变量的值;增加file标签,内容为脚本文件在hdfs中的路径#脚本文件;删除原有的check-output和fail-output标签即可
${jobTracker} ${nameNode} mapred.job.queue.name ${queueName} ${EXEC} my_output=Hello Oozie /user/root/oozie-apps/shell/${EXEC}#${EXEC} Shell action failed, error message[${wf:errorMessage(wf:lastErrorNode())}]
6、上传oozie-apps到hdfs中/user/${user.name}目录中,这里用户名为root
# cd ../..# /home/szc/cdh/hadoop-2.5.0-cdh5.3.6/bin/hadoop fs -put oozie-apps/ /user/root
上传完成后,可以在namenode的webui中找到这个目录和其中三个文件
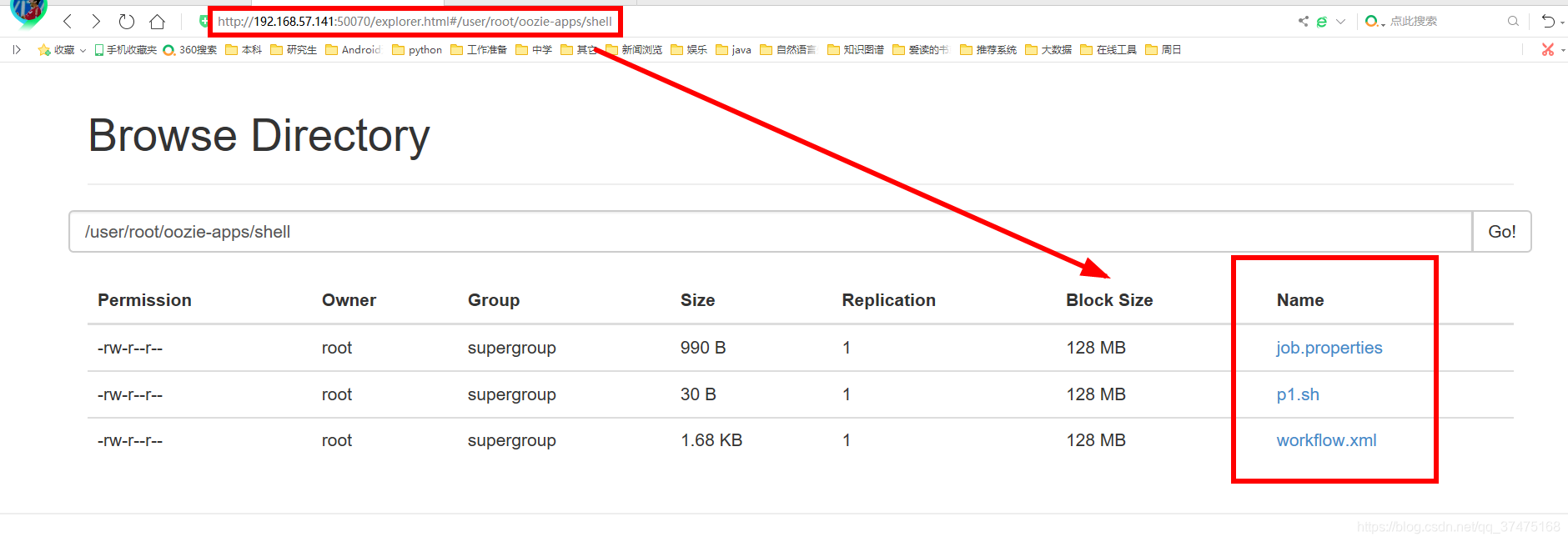
7、执行任务,指定oozie地址和配置文件,这里配置文件路径为hdfs中用户名目录下的路径
# bin/oozie job -oozie http://192.168.57.141:11000/oozie -config oozie-apps/shell/job.properties -runjob: 0000003-200428221417435-oozie-root-W
执行成功会得到job的id,并且可以在oozie的webui中看到此任务,并且状态为RUNNING

多刷新几次,就会在此页面的Done Jobs里看到已经完成的此任务
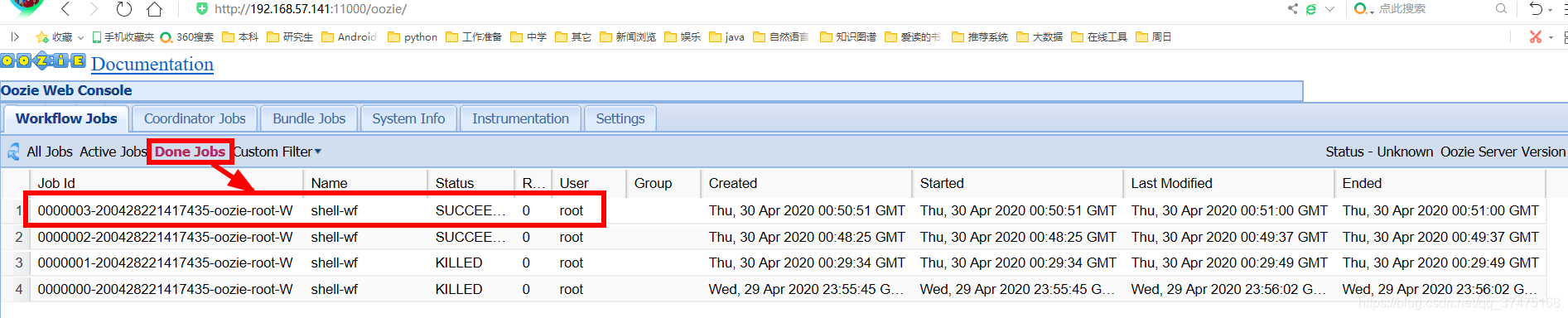
任务成功后,我们可以在执行此任务的namenode的/home/szc下看到ps1.log
$ cat /home/szc/p1.logThu Apr 30 08:50:57 CST 2020
调度多个任务
1、在oozie根目录\oozie-apps\shell目录下新建ps2.sh,内容如下
/sbin/date > /home/szc/p2.sh
2、修改job.properties,加入EXEC2
nameNode=hdfs://192.168.57.141:8020jobTracker=192.168.57.141:8032queueName=defaultexamplesRoot=oozie-appsoozie.wf.application.path=${nameNode}/user/${user.name}/${examplesRoot}/shellEXEC1=p1.shEXEC2=p2.sh
3、修改workflow.xml,加入shell-node2结点,并修改EXEC相关内容
${jobTracker} ${nameNode} mapred.job.queue.name ${queueName} ${EXEC1} my_output=Hello Oozie /user/root/oozie-apps/shell/${EXEC1}#${EXEC1} ${jobTracker} ${nameNode} mapred.job.queue.name ${queueName} ${EXEC2} my_output=Hello Oozie /user/root/oozie-apps/shell/${EXEC2}#${EXEC2} Shell action failed, error message[${wf:errorMessage(wf:lastErrorNode())}]
4、删除hdfs中原有的shell,上传新的
# /home/szc/cdh/hadoop-2.5.0-cdh5.3.6/bin/hadoop fs -rm -r /user/root/oozie-apps/shell20/04/30 09:10:23 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable20/04/30 09:10:23 INFO fs.TrashPolicyDefault: Namenode trash configuration: Deletion interval = 0 minutes, Emptier interval = 0 minutes.Deleted /user/root/oozie-apps/shell# /home/szc/cdh/hadoop-2.5.0-cdh5.3.6/bin/hadoop fs -put oozie-apps/shell /user/root/oozie-apps20/04/30 09:10:47 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
5、执行oozie任务
# bin/oozie job -oozie http://192.168.57.141:11000/oozie -config oozie-apps/shell/job.properties -run
完成后,可以在webui对应任务中的Job DAG中看到任务的有向无环图
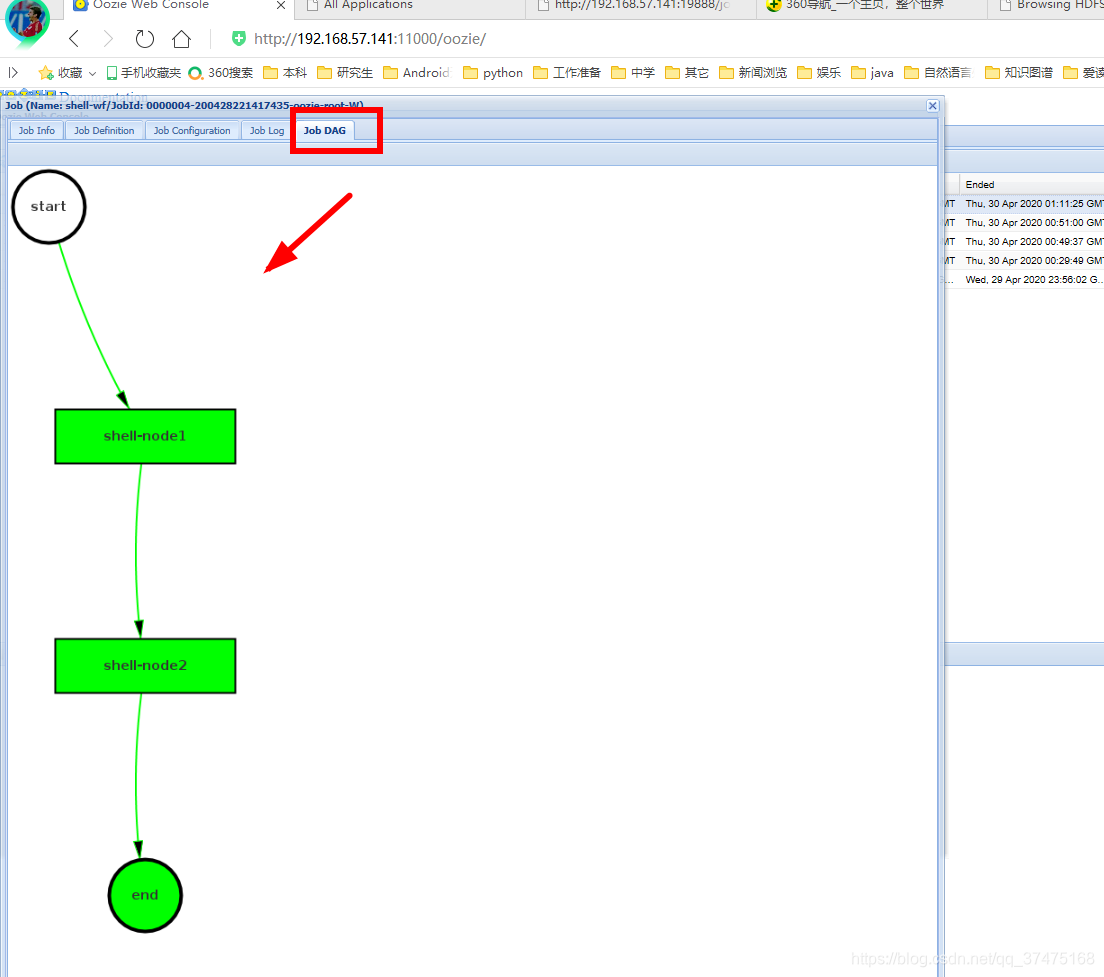
最后,在执行map任务的namenode的/home/szc目录下可以看到ps1.log和ps2.sh
$ cat /home/szc/p1.logThu Apr 30 09:11:14 CST 2020$ cat /home/szc/p2.shThu Apr 30 09:11:22 CST 2020
调度定时任务
切换到oozie根目录
1、修改conf/oozie-site.xml,在最后添加时区设置
# vim conf/oozie-site.xml
对应代码如下
oozie.processing.timezone GMT+0800
2、修改oozie-server/webapps/oozie/oozie-console.js文件,修改时区
# vim oozie-server/webapps/oozie/oozie-console.js
对应代码如下
function getTimeZone() { Ext.state.Manager.setProvider(new Ext.state.CookieProvider()); return Ext.state.Manager.get("TimezoneId","GMT+0800");} 3、重启oozie服务,清空浏览器缓存
# bin/oozied.sh stop# bin/oozied.sh start
清空浏览器缓存,重启浏览器,再次进入oozie的webui,查看Done jobs,可以发现时间都变成了东八区时间
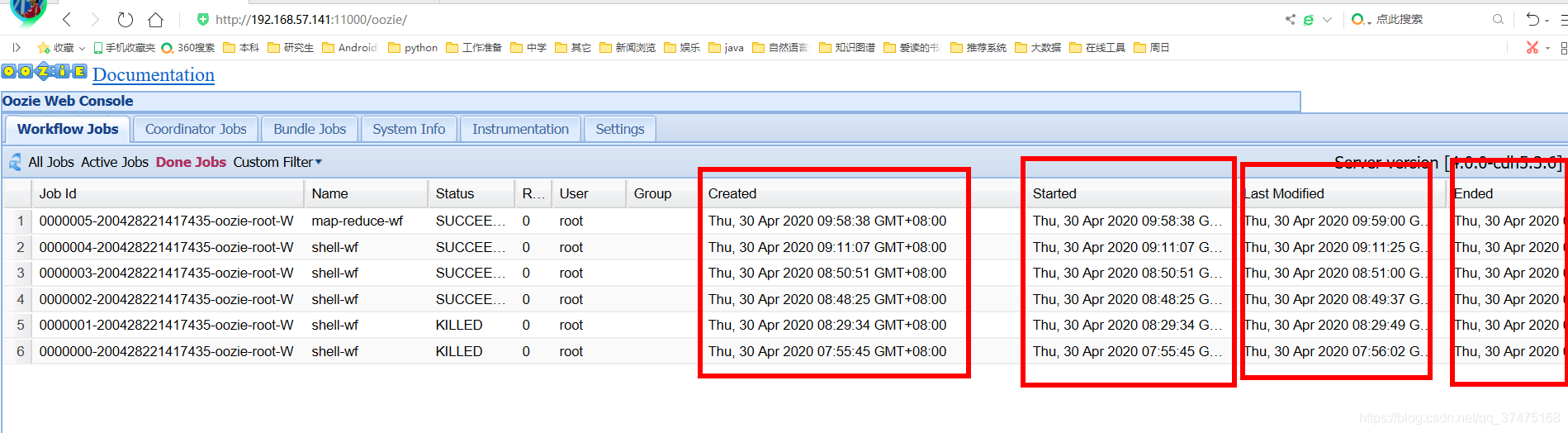
4、把examples目录下apps/cron目录复制到oozie-apps目录下,并切换到里面
# cp -r examples/apps/cron oozie-apps/# cd oozie-apps/cron/
5、修改job.properties、workflow.xml和coordinator.xml文件
job.properties主要修改namenode的ip、hdfs目录、起止时间。注意,起止时间必须设置成未来时间
nameNode=hdfs://192.168.57.141:8020jobTracker=192.168.57.141:8032queueName=defaultexamplesRoot=oozie-appsoozie.coord.application.path=${nameNode}/user/${user.name}/${examplesRoot}/cronstart=2020-04-30T11:02+0800 # 开始时间end=2020-04-30T11:30+0800 # 结束时间workflowAppUri=${nameNode}/user/${user.name}/${examplesRoot}/cronEXEC3=p3.sh p3.sh就是把时间追加到某个文件中
date >> /home/szc/p3.log
workflow.xml主要修改执行的脚本
${jobTracker} ${nameNode} mapred.job.queue.name ${queueName} ${EXEC3} my_output=Hello Oozie /user/root/oozie-apps/cron/${EXEC3}#${EXEC3}
coordinator.xml主要修改任务的时间间隔(frequency)为5分钟
${workflowAppUri} jobTracker ${jobTracker} nameNode ${nameNode} queueName ${queueName}
6、回到oozie根目录下,把cron目录上传到hdfs中
# /home/szc/cdh/hadoop-2.5.0-cdh5.3.6/bin/hadoop fs -put oozie-apps/cron/ /user/root/oozie-apps/
7、执行任务
# bin/oozie job -oozie http://192.168.57.141:11000/oozie -config oozie-apps/cron/job.properties -run
8、到时间时,在oozie的webUI界面中的Coordinator Jobs标签下,可以看到我们的定时任务
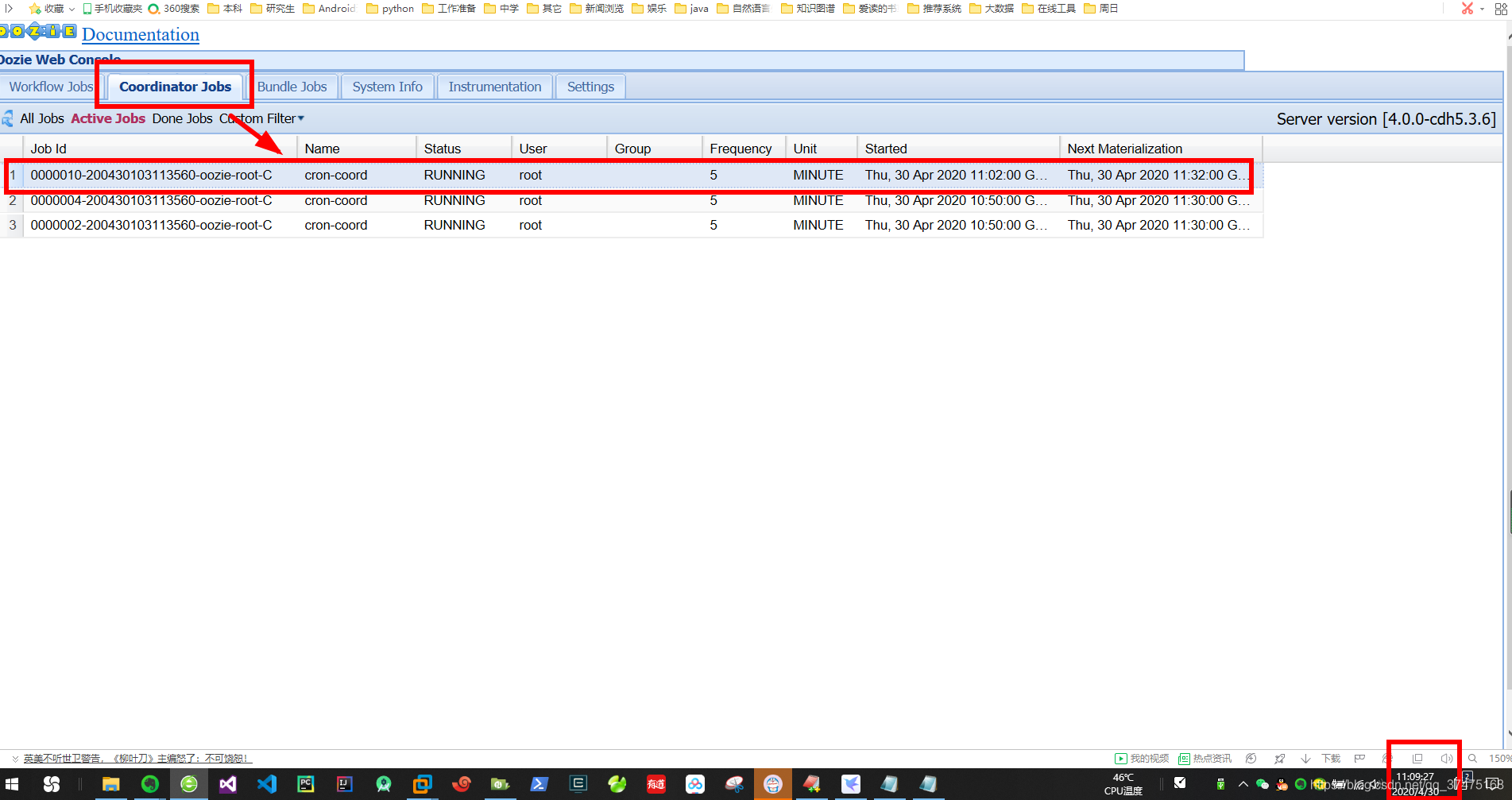
点击它,发现11点2分和7分的任务已经执行完毕
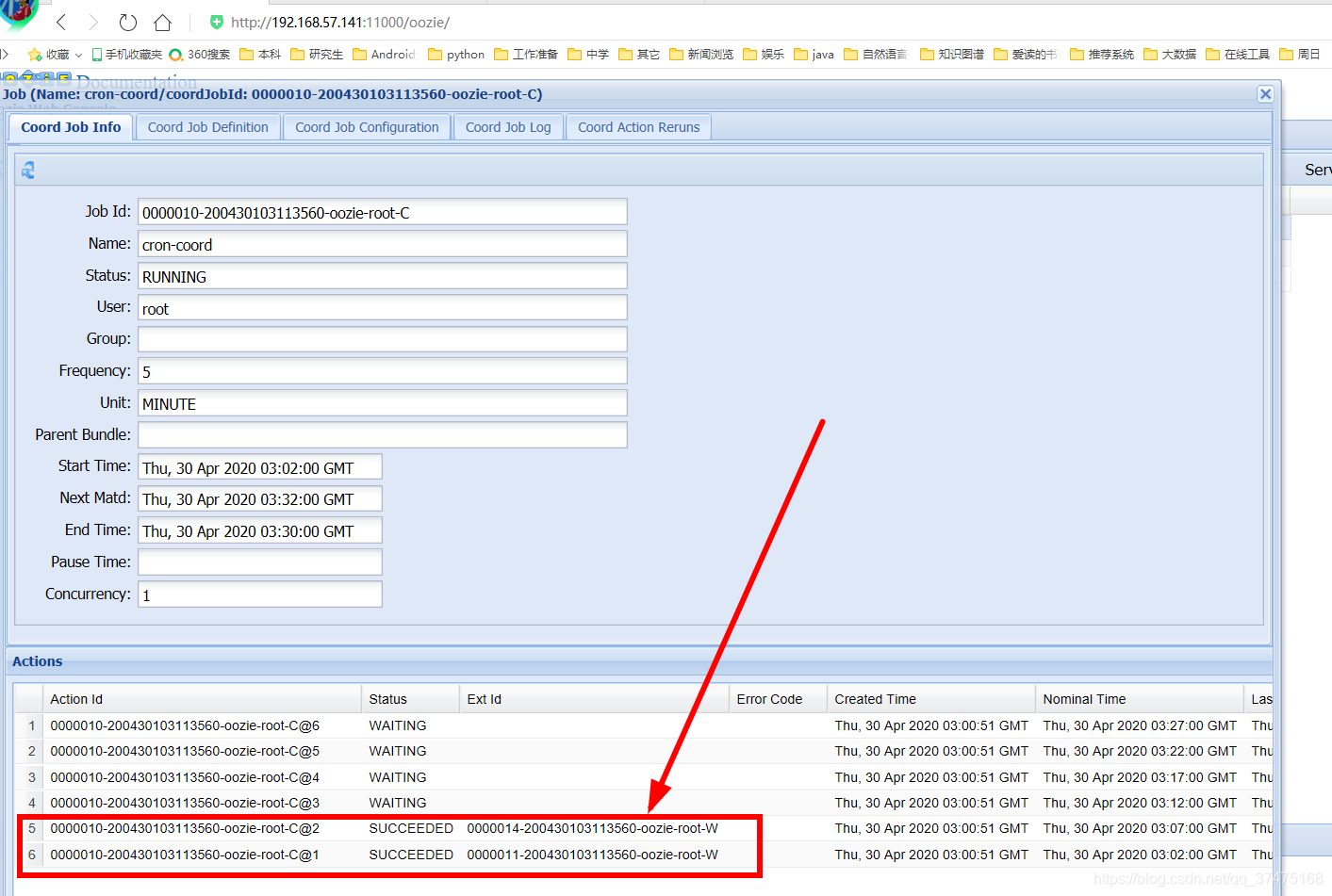
并且在文件中也有对应输出
# cat /home/szc/p3.logThu Apr 30 11:02:07 CST 2020Thu Apr 30 11:07:08 CST 2020
调度MapReduce任务
调度MR任务和调度普通任务类似,只是需要在workflow.xml中指定mapper等属性
1、切换到hadoop根目录下,构建wordcount.txt文件,作为测试用例
2、上传wordcount.txt到hdfs,用yarn运行待测MR任务的jar包
# bin/hadoop fs -put wordcount.txt /user/root# bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0-cdh5.3.6.jar wordcount /user/root/wordcount.txt /user/root/out
3、完成后,在集群的webui界面找到词频统计应用,点击History
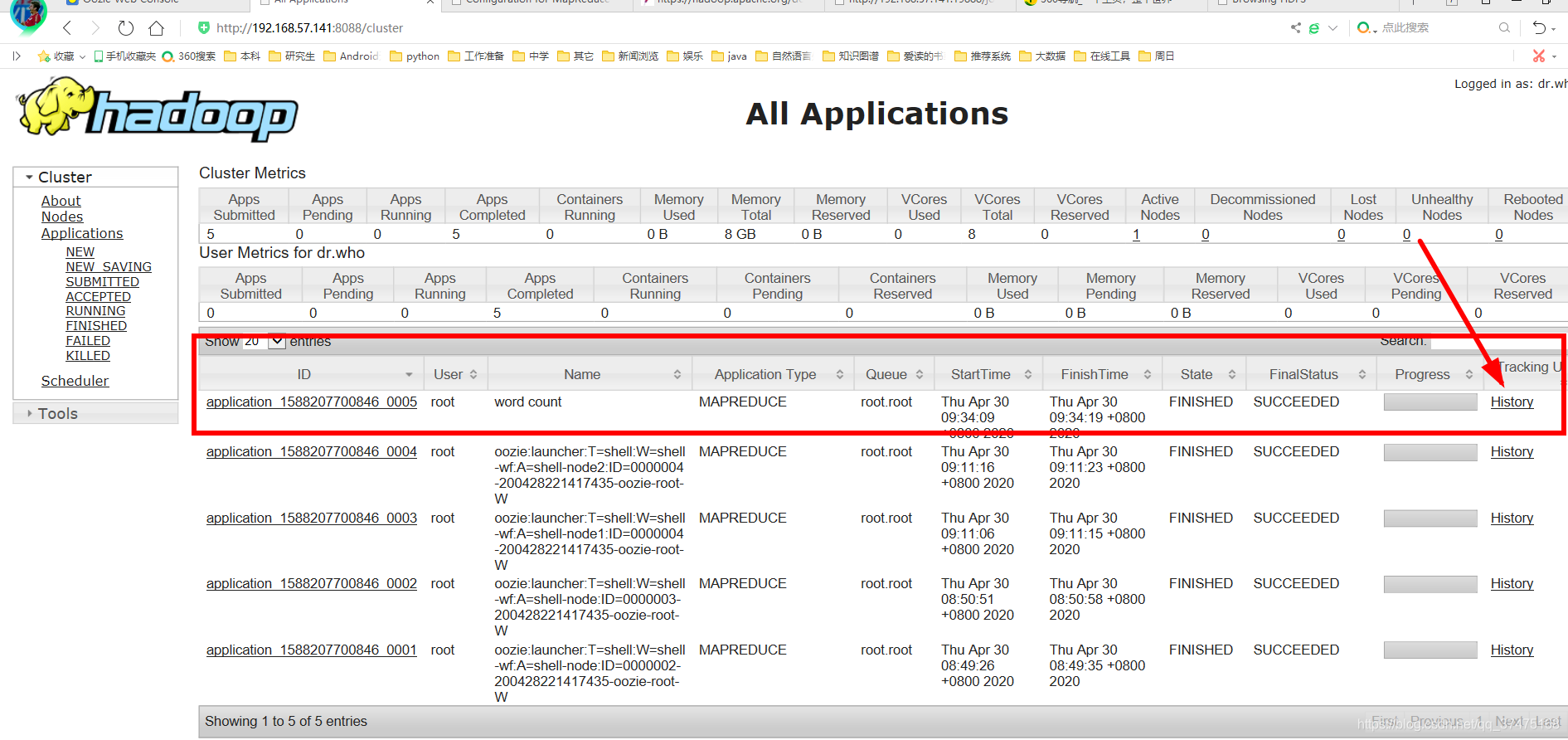
进入如下界面,点击右侧的Configuration,查看此任务的配置
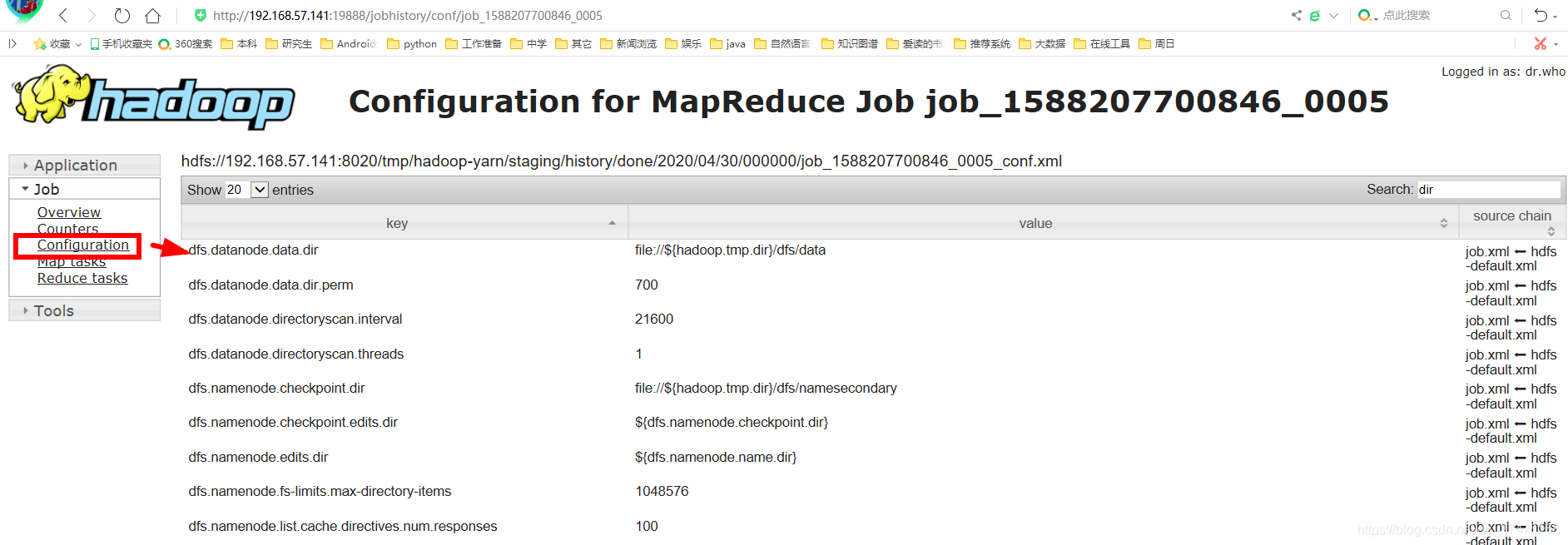
在右侧搜索框中搜索属性,包括map.class、reduce.class、combine.class、output.key、output.value、mapper.new-api、reducer.new-api
4、切换到oozie根目录,把examples/apps/map-reduce目录复制到oozie-apps目录下
# cp -r examples/apps/map-reduce/ oozie-apps/
5、进入oozie-apps/map-reduce目录,修改job.properties文件
nameNode=hdfs://192.168.57.141:8020jobTracker=192.168.57.141:8032queueName=defaultexamplesRoot=oozie-appsoozie.wf.application.path=${nameNode}/user/${user.name}/${examplesRoot}/map-reduce/workflow.xmloutputDir=map-reduce 6、修改workflow.xml文件,指定map.class、reduce.class、combine.class、output.key、output.value、mapper.new-api、reducer.new-api等属性
${jobTracker} ${nameNode} mapred.job.queue.name ${queueName} mapred.mapper.new-api true mapreduce.job.map.class org.apache.hadoop.examples.WordCount$TokenizerMapper mapred.reducer.new-api true mapreduce.job.combine.class org.apache.hadoop.examples.WordCount$IntSumReducer mapreduce.job.reduce.class org.apache.hadoop.examples.WordCount$IntSumReducer mapreduce.job.output.key.class org.apache.hadoop.io.Text mapreduce.job.output.value.class org.apache.hadoop.io.IntWritable mapred.map.tasks 1 mapred.input.dir /user/root/wordcount.txt mapred.output.dir /user/root/output Map/Reduce failed, error message[${wf:errorMessage(wf:lastErrorNode())}]
7、删除lib目录中原有jar包,替换成待测jar包
# rm -rf lib/*# cp /home/szc/cdh/hadoop-2.5.0-cdh5.3.6/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0-cdh5.3.6.jar lib/
8、上传mapreduce目录到hdfs中/user/root/oozie-apps目录下
# cd ..# /home/szc/cdh/hadoop-2.5.0-cdh5.3.6/bin/hadoop fs -put map-reduce/ /user/root/oozie-apps/
9、执行任务
# bin/oozie job -oozie http://192.168.57.141:11000/oozie -config oozie-apps/map-reduce/job.properties -run
执行完成后,可以在hdfs中我们指定的输出目录下看到结果
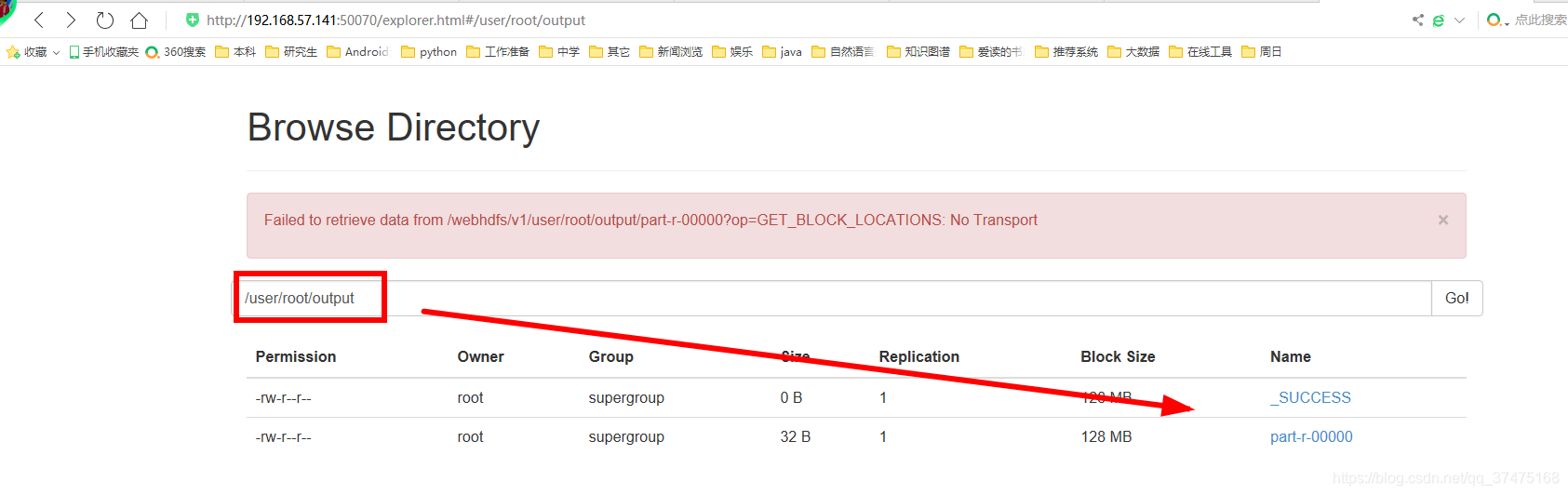
结语
总结一下oozie这个用于实时任务的调度的hadoop组件
功能模块:
1、workflow:顺序执行流程结点,支持fork、join
2、coordinator:定时触发workflow,控制任务的开始和结束
workflow常用结点:
1、控制流结点:控制工作流的开始、结束以及执行路径等
2、动作结点:执行具体的动作,比如拷贝文件、执行脚本等
转载地址:https://blog.csdn.net/qq_37475168/article/details/105964956 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
