本文共 4461 字,大约阅读时间需要 14 分钟。
在2017杭州云栖大会阿里云大数据计算服务(MaxCompute)专场上,阿里巴巴高级技术专家李睿博为大家分享了阿里云大数据计算服务MaxCompute对于开源系统的支持和融合,以及在拥抱开源和生态的时候阿里巴巴的技术团队遇到过哪些问题和挑战。
本文内容根据嘉宾演讲视频以及PPT整理而成。

在2016年杭州云栖大会上,大数据计算服务团队已经分享过MaxCompute在开源方面的支持和融合了,那次分享的主题叫做“MaxCompute的生态开放之路”。其实在阿里巴巴自己的历史上的早些时候存在过Hadoop和自研的大数据平台长期共存的时期,所以关于MaxCompute和开源生态之间的争论有很多。但是就计算服务团队而言,对于开源秉持的是非常开放的态度。去年讲支持开源,今年的目标则是将MaxCompute打造成为阿里巴巴自研的一站式的数据解决方案,为了实现这个目标,今年更换了一个词叫做融合,从支持到融合的转变,阿里巴巴还是做了很多事情的。

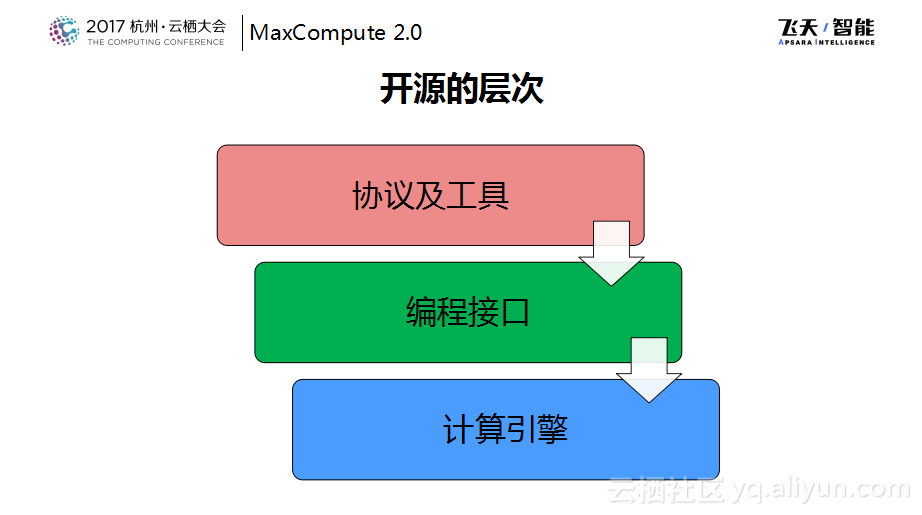
如下图所示,从技术栈的角度来看,这也是这几年从用户接口层面成立开源系统一步一步做下来的大概这样的几个层次。最早是对于开源的或者事实标准的工具层面进行接入,希望用户可以更加方便地接入MaxCompute的系统,然后在编程接口层面做了兼容,这样主要是为了保护用户的投资,包括帮助集团内部“登月”的过程更加平滑,今年的最新工作则是对于开源引擎做了更多的融合工作。
在开源协议层面主要的关注点是JDBC、Hive的协议,这里无外乎是让已有的支持JDBC的工具可以直接接入到MaxCompute系统上来。如下图右侧所示,可以通过像JDBC驱动、Zeppelin、Workbench、Pentaho、TalenD这样的数据分析工具是可以直接对接到MaxCompute上面来做数据分析的。当然JDBC也提供了一个标准的JDBC编程接口,这样对于用户而言,编程成本更小,可以直接把之前在数据库上使用的一些代码拿过来使用。在Hive Thrift这一层,提供了Hive Thrift协议的兼容接口,在这一层之上基本上所有的Hive生态链都可以支持,包括Hive的ODBC驱动、Hive的命令行工具等。除此之外还有ETL工具支持,这一部分主要负责对于多种数据源数据的导入导出。
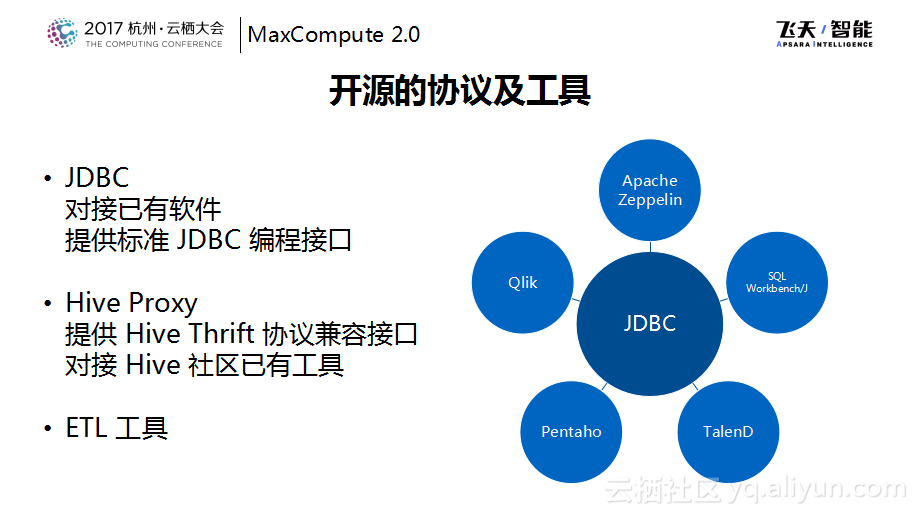
除了协议和工具的支持,MaxCompute还打通了用户接入系统的第一层门槛,也就是用户可以避开阿里巴巴自研的工具链直接对接到MaxCompute系统上。
而接下来需要面对的问题就是工具可以对接上来,但是在工具中所写的SQL在一两年之前还需要写MaxCompute所定义的SQL,而这个SQL与Hive SQL、标准的SQL以及Oracle的SQL还是会有些区别的,这就会导致之前的代码难以迁移。MaxCompute的SQL团队去年的时候也花费了很大的精力跟随MaxCompute 2.0推出了一系列特性来对于Hive做了全面的兼容,保护了用户的代码投资,可以让用户更加平滑地迁移到MaxCompute上来,包括现在可以完整兼容Hive的类型系统、完整兼容Hive的內建UDF甚至包括用户自己为Hive开发的UDF也可以直接搬到MaxCompute的SQL里面运行,并且目前也已经支持了外表,也就是数据可以不只是在MaxCompute里面,其可以在外部的OSS等的任何地方。MaxCompute SQL在语法层面也做了相当多的细节改进,使得其可以兼容Hive的语法。

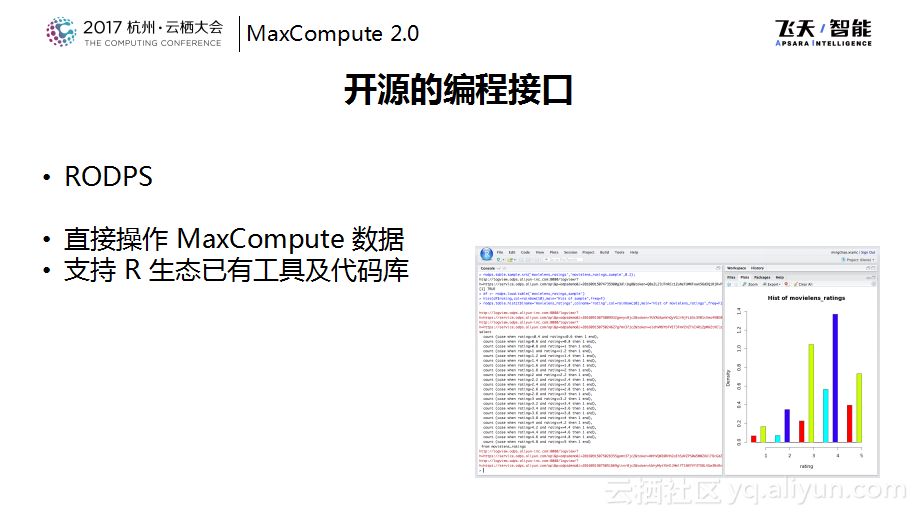
可能80%以上的用户都是通过SQL的接口来使用MaxCompute系统的,但是也有很多传统的数据分析师是通过R语言进行数据分析,所以很多MaxCompute也做了RODPS,这是R上的插件,当将这个插件装到R上之后就直接打通了从R到MaxCompute的桥梁,可以直接将R的table直接转化为DataFrame。后续可以在使用R自己生态上面使用R原生的DataFrame进行分析和各种各样的报表展示,这样就不需要用户将数据导出来再导入到R里面去的繁琐过程。
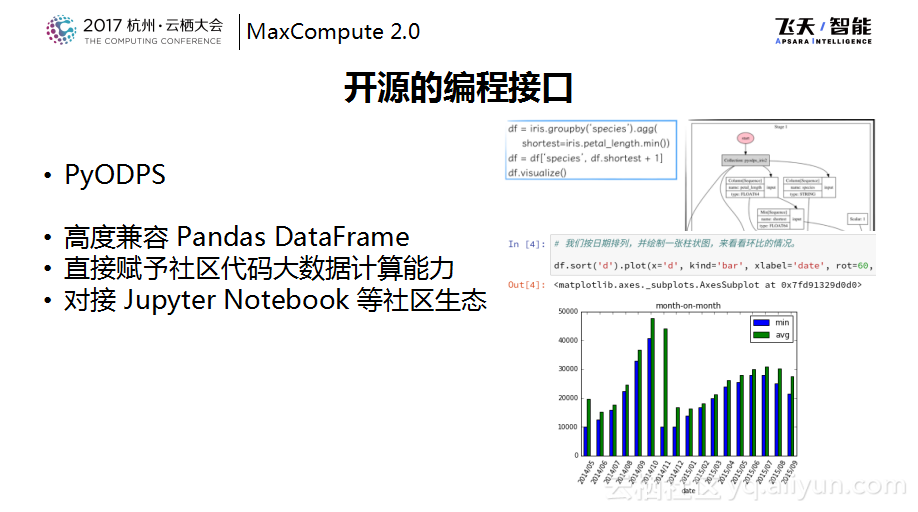
既然提到了R,也要提到Python。因为目前Python社区在通用编程以及大数据分析方面的上涨势头也非常好。像在Python社区中的Pandas DataFrame这套API也是数据分析师非常喜欢的编程接口。MaxCompute在Python SDK的基础之上提供了一套高度兼容Pandas DataFrame的自研DataFrame,这套自研DataFrame的不同点在于其实际执行是在MaxCompute里面,而刚才提到的R则是将数据导入到R里面进行单机的分析。在这边可以做到对于一个MaxCompute表建成一个DataFrame,然后再用像一个DataFrame做GroupBy或者Filter等计算,这一切都发生在MaxCompute的服务端,这样就可以直接给社区的已有代码赋予大数据计算的能力,也希望通过这样的形式把MaxCompute的计算能力赋予给社区。同时也注意到Python社区中Jupyter Notebook这些工具链非常好用,所以也将DataFrame做了很多的可视化集成工作,可以在Notebook上面实现一些展示效果非常好的信息。
当完成了以上这些工作之后,在协议、工具以及编程接口方面已经有了比较大的进步或者说比较好的支持,但是还是不得不面临非常多的用户的问题,比如MaxCompute对于Spark API的支持等问题。因为开源的计算引擎非常多,每种计算引擎都是针对各自的细分场景的。其好处是用户最开始在使用的时候可以快速搭建,能够很快地上手,学习资料也比较多,但是总会有一些问题,比如规模或者资源利用效率的问题等,用户就会想这份作业通过现有的系统能不能迁移到MaxCompute上来托管给阿里云的服务,这个时候就会面临这样的选择,这就和集团内的“登月”计划的初衷是一样的。当然“登月”的效果是大家都想要的,因为数据都放在一起之后,数据所产生的威力是非常大的,但是“登月”的过程,大家都想轻松一些。
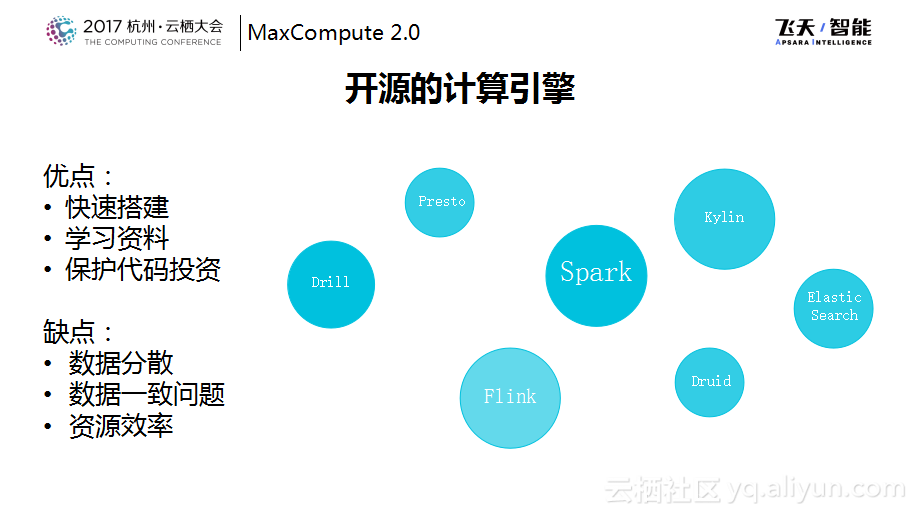
之前计算服务团队也对于开源的API的兼容做了很多尝试,如果用一套自研的计算引擎来兼容各种各样的API是不太现实的事情,所以后来转换了思路,考虑能否在保持自研优势的基础之上更好地拥抱开源生态。在保持数据存储、资源调度以及安全控制的统一的基础之上,将开源的计算引擎也直接运行在MaxCompute平台之上,这也是服务计算团队今年主要做的事情,也就是联合计算平台,通过将开源的系统运行在MaxCompute平台上使得MaxCompute获得更好的兼容能力。这也就是对于开源的态度从支持走向融合,希望通过MaxCompute提供一站式的大数据解决方案。
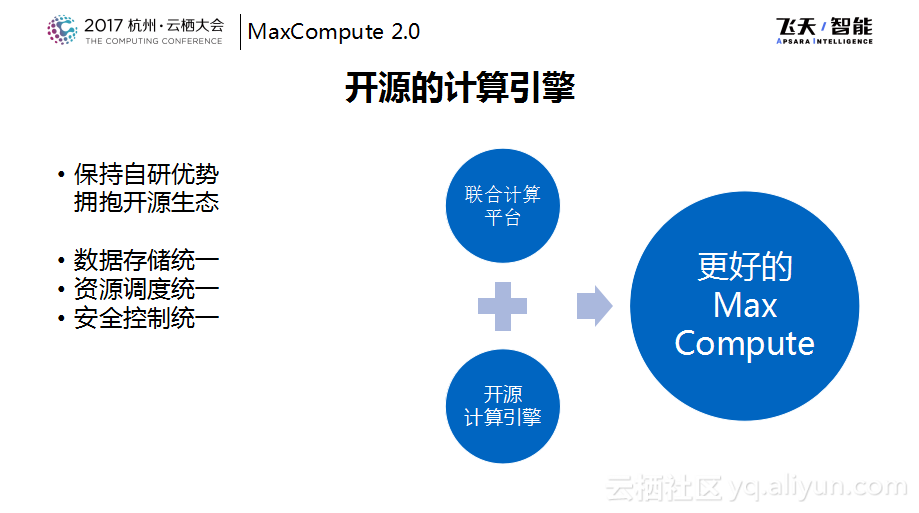
接下来分享一下联合计算平台,刚才提到了三个统一,对于这三个统一而言,真的要将其实现就会变成这四个挑战。
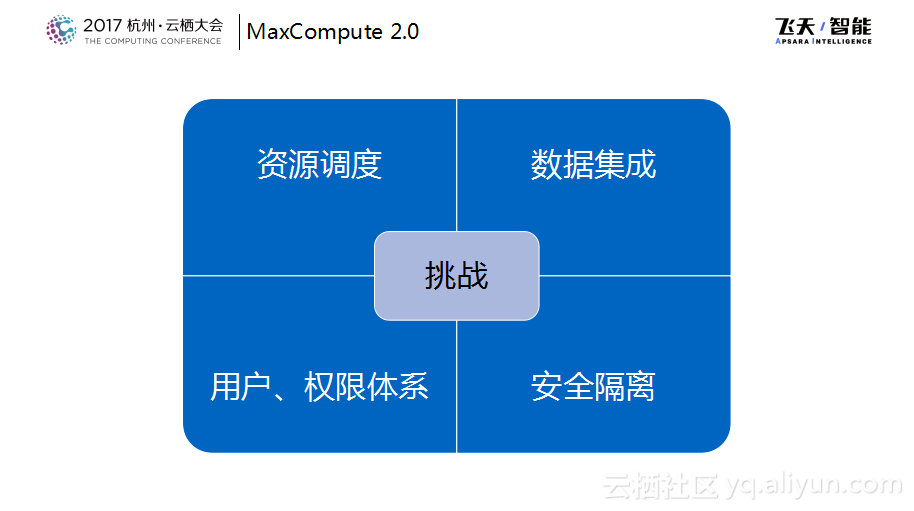
因为开源的系统通常会有比如一套Spark集群、一套Flink集群等,这些往往都是独立的集群,需要做资源调度的整合。通常开源系统中的用户权限控制相对比较弱,大家可能会把集群拆分成为多个来做权限的隔离。但是因为MaxCompute是一个统一的SaaS服务,那么在用户的鉴权、权限控制方面以及运行时的隔离方面有很多的工作需要做。最后当数据都放在一起之后,其实也需要有让Spark API以及其他的API能够访问已经在MaxCompute里面数据的能力,那么就是所提到的数据集成的这些内容。面临这些挑战,接下来会用一个例子来讲联合计算平台是怎样实现的。
下图是标准的SparkOnYarn的标准的作业的简单架构示意图,当然在这里为了简化并没有将所有的角色画出来。这里可以看到通过一个客户端可以提交一个Spark作业,这个Spark作业会有自己的一个Master,Master会向Resource Manager申请资源,然后Resource Manager通知Node Manager将Spark的Container启动起来。对于Spark作业而言就变成了一个Spark+若干Container这样的一个结构。在作业外面还有一个Browser可以直接访问到App Master的WebUI上面,或者在运行完成之后会下沉到HistoryServer上面,可以来看作业的运行状态。这是一个标准的Spark的运行方式。
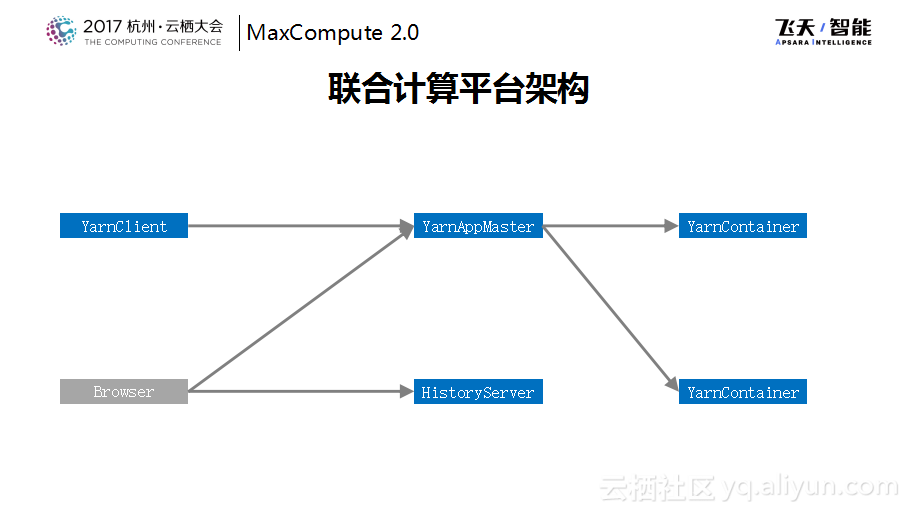
联合计算平台所做的事情是这样的,把像是Spark或者其他的开源计算引擎包装成MaxCompute内部的一个Task,在这里叫做CupidTask。然后通过MaxCompute统一的restfulAPI提交CupidTask,这里用户的认证以及鉴权都是在统一的接入层进行的,也就是说在这里就杜绝了用户访问到没有权限访问的Spark资源,这样的SparkTask会给每个角色外面都包装一个管理者角色,叫做CupidMaster和CupidWorker。在资源调度这层其实是由CupidMaster来代理的,这样就可以统一地走飞天的资源调度,然后由CupidMaster代理了APPMaster对于资源的管理。
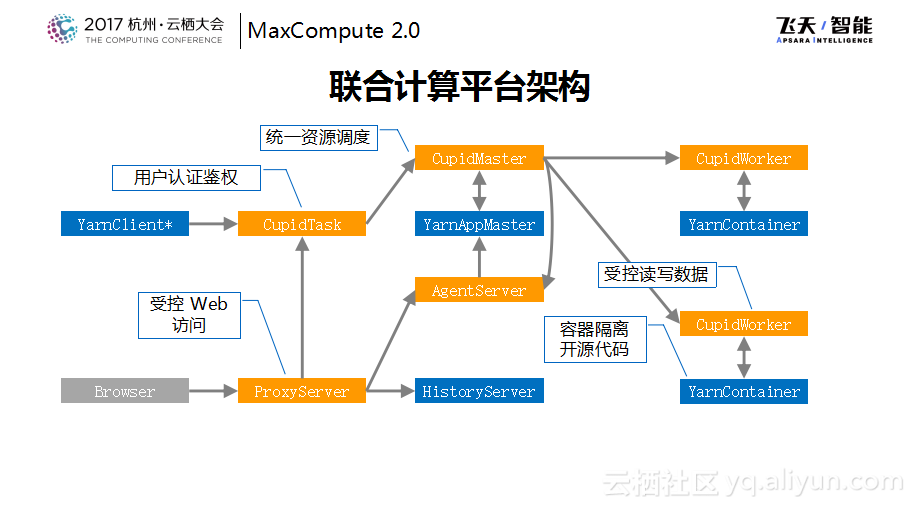
因为开源的代码写起来比较灵活,而作为运行在一起的Service也需要保护用户的数据安全,所以开源代码需要严格地放在隔离的环境中,而不会看到和自己的数据无关的地方,而自己的数据是通过CupidWorker来实现的,所以开源代码所能够看到的数据一定是通过授权和认证体系同意之后才能访问的数据并且通过CupidWorker同步给下面的容器。通过这样的方式将标准的Spark作业变成了一种MaxCompute作业,这样就实现了某种程度的混跑,所以数据是同一份,既可以使用MaxCompute自己的SQL来处理这份数据,也可以使用Spark数据来处理这份数据。
下图所示的是运行的展示效果,其实与原生社区的版本在运行起来基本上看不出有什么区别。
MaxCompute与开源的融合,在协议和工具层面做的一些支持都是之前在MaxCompute RestfulAPI服务之上通过SDK来实现的。而在MaxCompute里面的组件也是对于开源进行了支持,包括自己的SQL对于Hive做了非常多的兼容工作,另外通过联机计算平台的形式将开源的系统迁移到MaxCompute平台里面。目前专有云的版本已经有了支持Spark等的版本,借助于联合计算平台,Spark等可以天然地在外围作为开源API进行支持,整个的这套资源都是架构在飞天体系之上,希望通过融合的架构提供给用户以更加灵活的选择。用户可以将已有的数据和应用搬迁上来,用原来的Spark或者机器学习作业继续在上面运行。如果遇到问题,也可以同一份数据既落到MaxCompute里面也可以直接对于这份数据使用PAI引擎进行计算,这样就可以产生更大的价值。
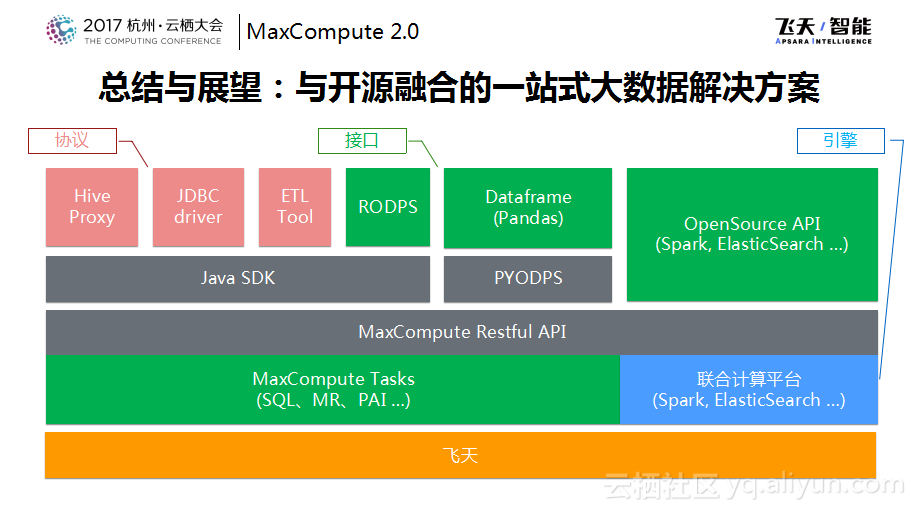
未来,我们也希望将联合计算平台的能力逐步地开放出来,可以方便地将开源社区的成果直接应用到MaxCompute体系中。

转载地址:https://blog.csdn.net/qq_35267530/article/details/78364895 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
