本文共 3178 字,大约阅读时间需要 10 分钟。
深度学习超大模型的分布式训练的探索(一)
1 背景
数据是算法的石油,伴随着近年来大数据的广泛兴起与机器算力的巨大提升,深度学习大行其道,已经深入到了人们生活的方方面面。在搜索、推荐、购物、广告、短视频以及金融风控等领域,深度的影响着亿万大众。
这些行业每天都在产生大量的数据,超大规模的数据量促进深度学习技术的发展,同时模型变大后也需要更多数据来训练,以前的单机训练逐渐变成了集群训练,成为一个循环,数据规模越来越大,同时模型规模也越来越大,从最初的几M到T级别。同时众所周知,最近几年的算法基本是在吃深度学习的红利,从业者使用DNN、CNN、RNN等模型以及变种,加上attention、GRU等机制,就可以保证模型的效果,产生巨大的收益。但是最近内卷这个词被频频提到,代表着红利逐渐消失,使用目前的算法模型进行业务演进遇到巨大的难题,很多算法与策略都已经使用过了,对于业务的效果提升都已经产生了。这个时候就需要从大基建层面进行探索,笔者有幸带领团队在联邦学习领域进行了探索,并且实现了跨域超大规模数据的联合建模,并且产生了显著的业务效果,也算是开拓了一个新的业务场景吧。同时也深刻的意识到还有一个领域可以进行深度,那就是深度学习超大规模模型,产生表征能力与泛化能力更强的超大模型,进一步提升业务的指标,提升用户体验,造福亿万大众。
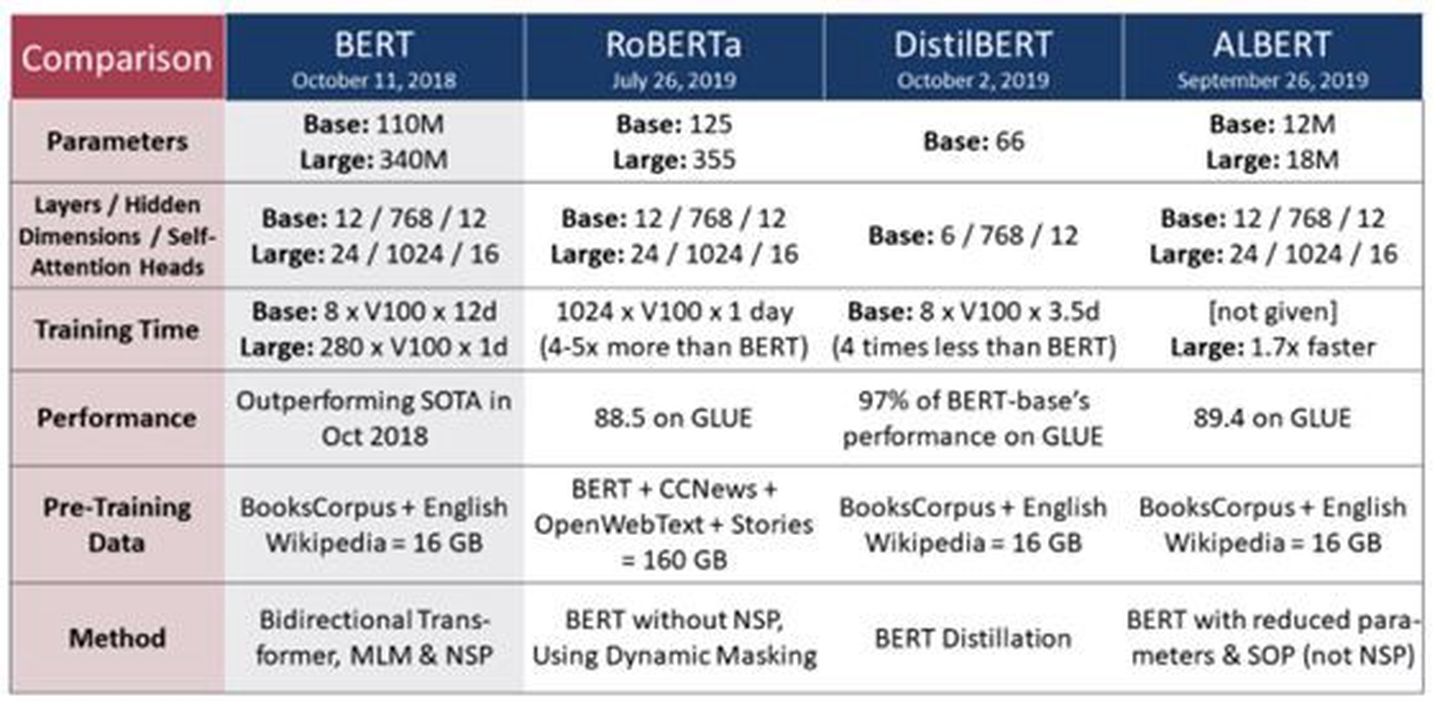
以NLP场景为例,模型呈现出来越来越大的趋势,从Bert到GPT3,模型参数越来越多,并且模型的大小也从几个G到上T不等,给整个机器学习的框架带来了严峻的考验。模型分类:GPT-3有8个不同的模型,参数从1.25亿到1750亿不等。
- 模型大小:最大的GPT-3模型有1750亿参数。这比最大的BERT模型大470倍(3.75亿个参数)
- 体系结构:GPT-3是一种自回归模型,使用仅有解码器的体系结构。使用下一个单词预测目标进行训练

目前社区的原生的深度学习框架无法满足这种超大规模模型的需求,各家厂商也进行了深度的跟进与探索,作为核武的威慑力存在,百家齐放、百家争鸣。笔者打算写一系列文章,用来和大家一起探讨深度学习超大规模分布式的方案,本章先对目前的情况进行下分析,并且提出一些探索的方向,接下来的一段时间会继续进行深度的跟进。
2 目前行业解决方案
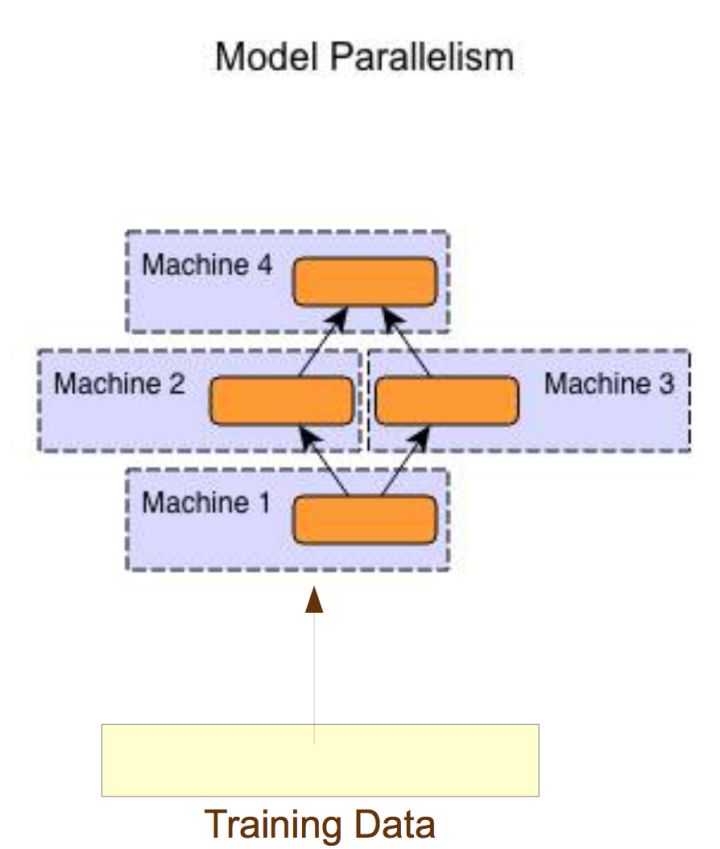
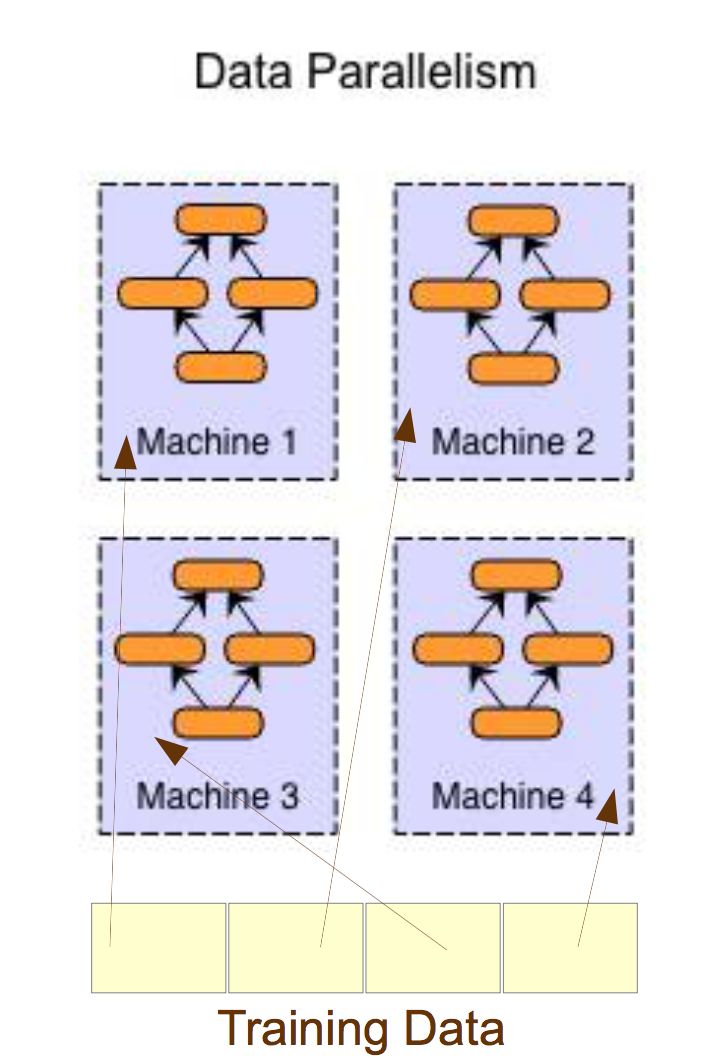
分布式训练的优势在于可以做到并行化,按照并行方式的不同,模型训练可以分为数据并行和模型并行:
- 模型并行:对不同机器,数据输入相同,运行网络模型的不同部分。
- 数据并行:对不同机器,数据输入不同,每个机器运行样本的一部分,但是运行的网络模型是相同,然后将所有机器的计算结果按照某种方式合并。
优劣比较:
- 当模型计算较大,并且对于时效要求较高的情况下,一机8卡(GPU)仍然无法满足算力的情况下,可以使用这个方法,但是整体扩展性差,集群数量增加后并行脚本可能需要改动。
- 相对应的数据并行,各个部分相互独立,仅仅使用各自的算力,集群扩展性更好,是目前的主流方式。
3 梯度更新的问题
单纯的模型并行梯度更新不是问题,但是在数据并行时,每台机器上都会有一份模型梯度,因此需要将集群中多台机器的梯度累加求均值,并用得到全局Average gradients 更新权重,训练的时候从PS进行权重与参数的拉取。不过这里面涉及几个问题?
- 问题1:什么时候进行多台机器的梯度累加?
- 问题2:如何高效的在多台机器间做梯度累加?
下面我们看下针对这两个问题的目前行业的解决方案。
问题一:梯度累加的时机
其实本质上是梯度更新方式,目前存在两种:
1 同步更新
所有worker都在同一个时间点做梯度更新,也就是等待所有worker的梯度都计算完毕后再统一做更新,因此计算最慢的机器会成为更新效率的瓶颈。

2 异步更新
只要有一个worker计算完梯度并且发起更新请求时,就会立即对参数发起更新,而不等待其他worker。但是可能会存在收敛效率不佳,因为一些速度慢的节点总会提供过时的梯度方向,导致梯度方向有偏差。对于落后于当前迭代的梯度,常见做法就是丢掉。这个地方可以做下优化,采用半异步的模型,在一定程度进行同步,能够保证模型的收敛效果,代价是降低一部分训练的速度,不过这个大家对比模型不收敛而做无用功,也算是值得的。

问题二:梯度累加的效率
1 Parameter server 方式
首先单独分出一台或者多台机器做梯度累加,一般称为Parameter Server(简称PS)。所有workerpush自己的梯度到PS,PS做完累加求均值后,再由Worker前向训练的时候去pull。
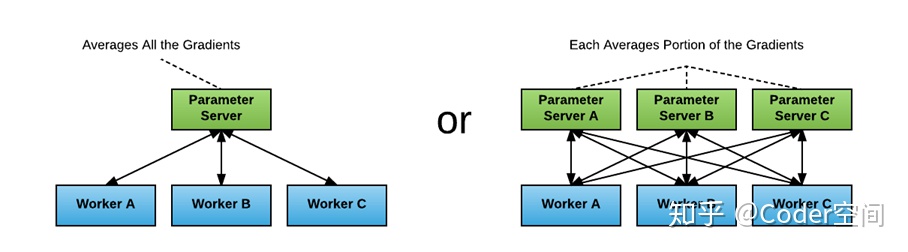 深度学习 模型训练 梯度累加 Parameter Server
深度学习 模型训练 梯度累加 Parameter Server
2 AllReduce 方式
所谓All reduce,**其目标是高效地将不同机器中的数据归并(reduce)之后再把结果分发给各个机器。**AllReduce有很多种不同的实现,目前比较高效是实现之一就是Ring All reduce,下面我们以三台机器为例来说明下。
第一阶段, scatter-reduce阶段
- Step 1:

-
Step 2:

-
Step 3:

-
Step 4:

-
Step 5:

第二阶段,all-gather阶段:
- Step 1:

- Step 2:

- Step 3:

- Step 4:

大功告成,All reduce主要是利用节点间的累加计算代替了PS的工作,上面的步骤较多,但是在工程实现的时候,很多动作可以是并行的,同时ALL Reduce模式主要是同步的模式,这点大家要知晓。
All Reduce算法是从高性能计算领域引入到深度学习模型训练中的,这类算法也被称为集合通信(Collective Communication )算法。当然现在不需要我们手动去实现算法,只需要直接调用一些底层的通信库就可以了。比如:Nvidia的NCCL支持GPU多机多卡通信,同时也做了很多优化,以在PCIe、Nvlink、InfiniBand上实现较高的通信速度。当然也可以使用经典的openMPI库里面的ring allreduce算法。
总结思考
本文是深度学习超大模型的分布式训练的第一章,主要先从一些行业内的做法和大家做些同步,当我们想要超越的时候,最应该做的是要了解目前的情况是什么,有哪些优劣点,从而探索我们要做什么,那么下来我先简单谈些一些个人认为比较合适的点。
-
模型并行+数据并行:结合笔者的以往的经验,这个可以比较优雅的解决。
-
原生PS + 改造Worker + 外挂PS的模式:XDL、BytesPS、百度的PaddlePaddle等基本都是这个思路,以一个大的分布式的hash table来解决大规模稀疏的问题,并且在性能与效果上做平衡,需要在variable的初始化、更新、读取以及优化器等方面做一系列工作,并且需要完美的加入到原来框架的流程中去,比如Tensorflow就是要完美的加入图中,以在线服务类比,说白了就是的session流,按照框架的套路加进去就好。
-
原生PS + 改造Worker + 外挂PS的模式 + All Reduce的混合模式:这个是笔者最近思考的,不过发现好像有些公司已经在做了,我觉得这个也是个很好的思路,值得尝试,核心将树状的稠密的计算网络,做成星图分散式网络,本质还是分布式的思想,只不过均摊的更加均匀而已,所以有些知识要灵活运用。
-
通信优先级调度、RDMA 、PCIe switch 与 NUMA 的优化,IB卡的引入,从更底层更细节的层面进行关注。
上面的点,先放在这,接着查些资料、调调代码,有句话说的话,千里之行,始于足下,踏踏实实的吧,先做些实验,欢迎大家一起来讨论,大家携手一起讨论,构建更大更强的模型。
欢迎关注个人微信公众号“秃顶的码农”,干货不断!

转载地址:https://blog.csdn.net/qq_22054285/article/details/117225332 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
