Learning Dynamic Memory Networks for Object Tracking
ECCV 2018Updated on 2018-08-05 16:36:30
Paper:
Code: (Tensorflow Implementation)
【Note】This paper is developed based on Siamese Network and DNC(Nature-2016), please check these two papers for details to better understand this paper.
DNC: Paper:
Siamese Network based tracker: Paper:
Another tracking paper which also utilizes memory network:
=================================
Motivation:想利用动态记忆网络(Dynamic Memory Network)来动态的更新 target template,以使得基于孪生网络的跟踪算法可以更好的掌握目标的 feature,可以学习到更好的 appearance model,从而实现更加准确的定位。
Method:主要是基于 Dynamic Memory Network 来实现目标物体的准确更新。通过动态的存储和读写 tracking results,来结合原始的 object patch,基于 Siamese Network Tracker 进行跟踪,速度可以达到:50 FPS。
Approach Details:
Dynamic Memory Networks for Tracking:
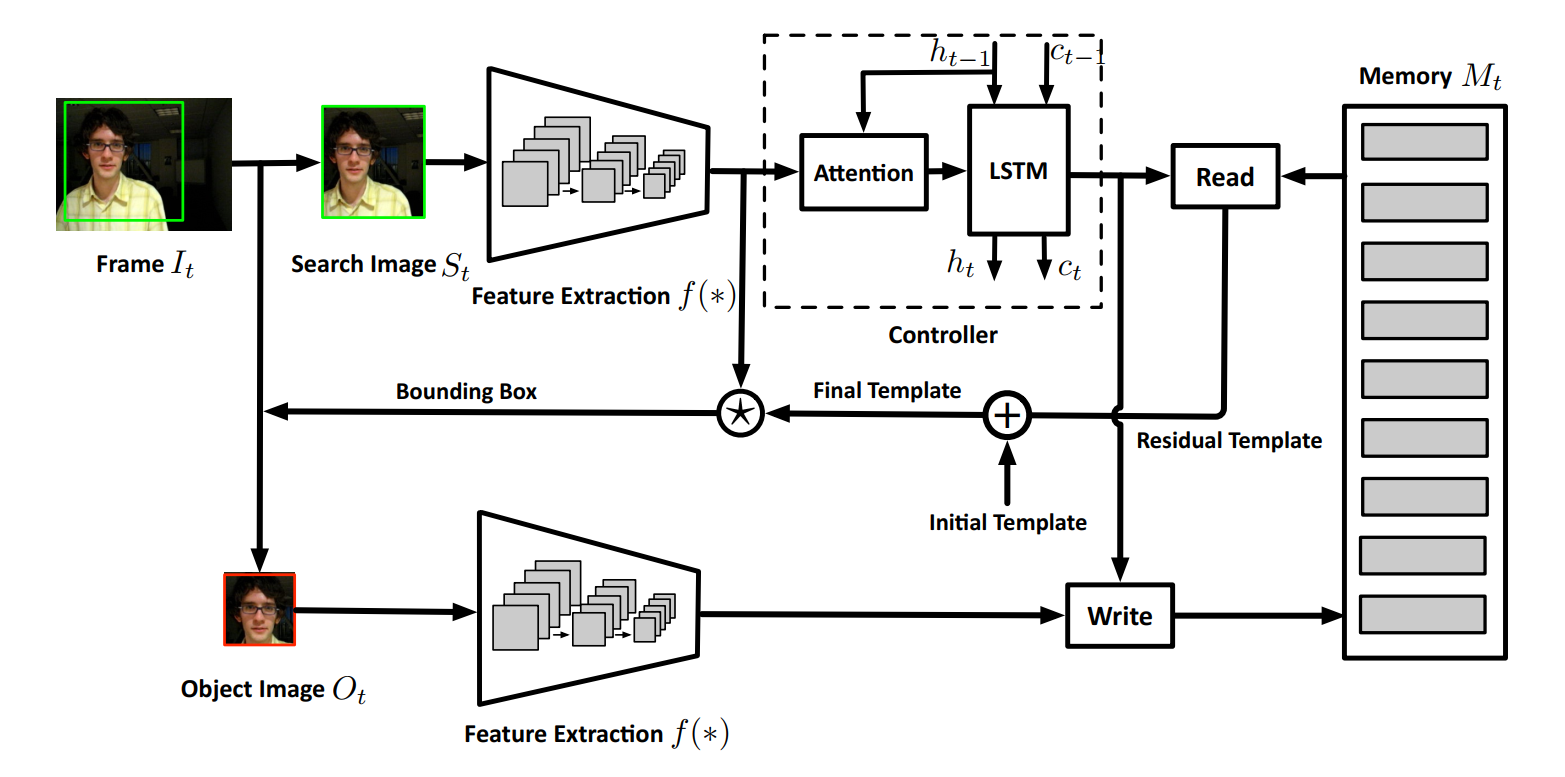
1. Feature Extraction:
本文的特征提取方面,借鉴了 SiamFC;此处不细说。
2. Attention Scheme:
本文介绍 Attention 机制引入的动机为:Since the object information in the search image is needed to retrieve the related template for matching, but the object location is unknown at first, we apply an attention mechanism to make the input of LSTM concentrate more on the target. 简单来讲,就是为了更好的确定所要跟踪的目标的位置,以更加方便的提取 proposals。
作者采用大小为 6*6*256 的 square patch 以滑动窗口的方式,对整个 search image 进行 patch 的划分。为了进一步的减少 square patch 的大小,我们采用了一种 average pooling 的方法:

那么,经过 attend 之后的 feature vector,可以看做是这些特征向量的加权组合(the weighted sum of the feature vectors):

其中,L 是图像块的个数,加权的权重可以通过 softmax 函数计算出来,计算公式如下:
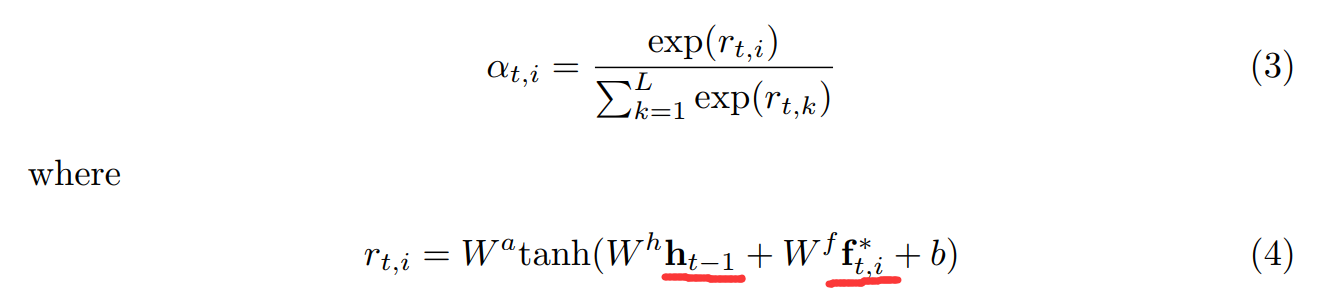
其中,这个就是 attention network,输入是:LSTM 的 hidden state $h_{t-1}$,以及 a square patch。另外的 W 以及 b 都是可以学习的网络权重和偏差。
下图展示了相关的视觉效果:

3. LSTM Memory Controller
此处,该网络的控制也是通过 lstm 来控制的,即:输入是上一个时刻的 hidden state,以及 当前时刻从 attention module 传递过来的 attended feature vector,输出一个新的 hidden state 来计算 memory control signals,即:read key, read strength, bias gates, and decay rate。
4. Memory Reading && Memory Writting && Residual Template Learning:
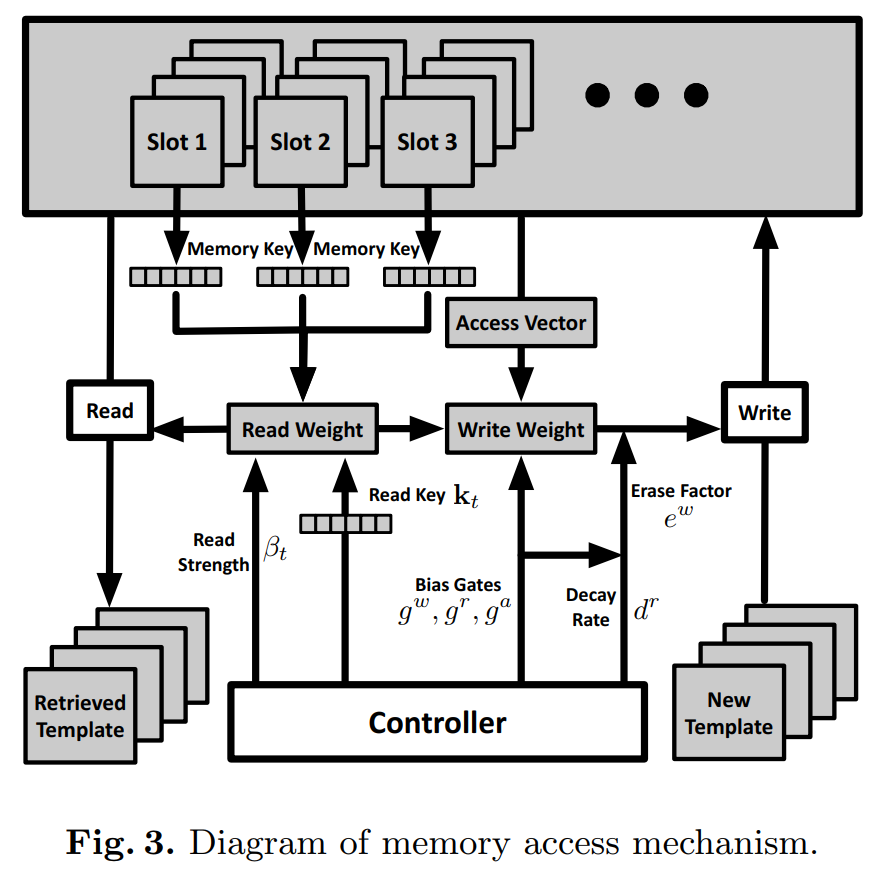
==>> 我们可以从 如下的这两个视角来看点这个 read 和 write 的问题:
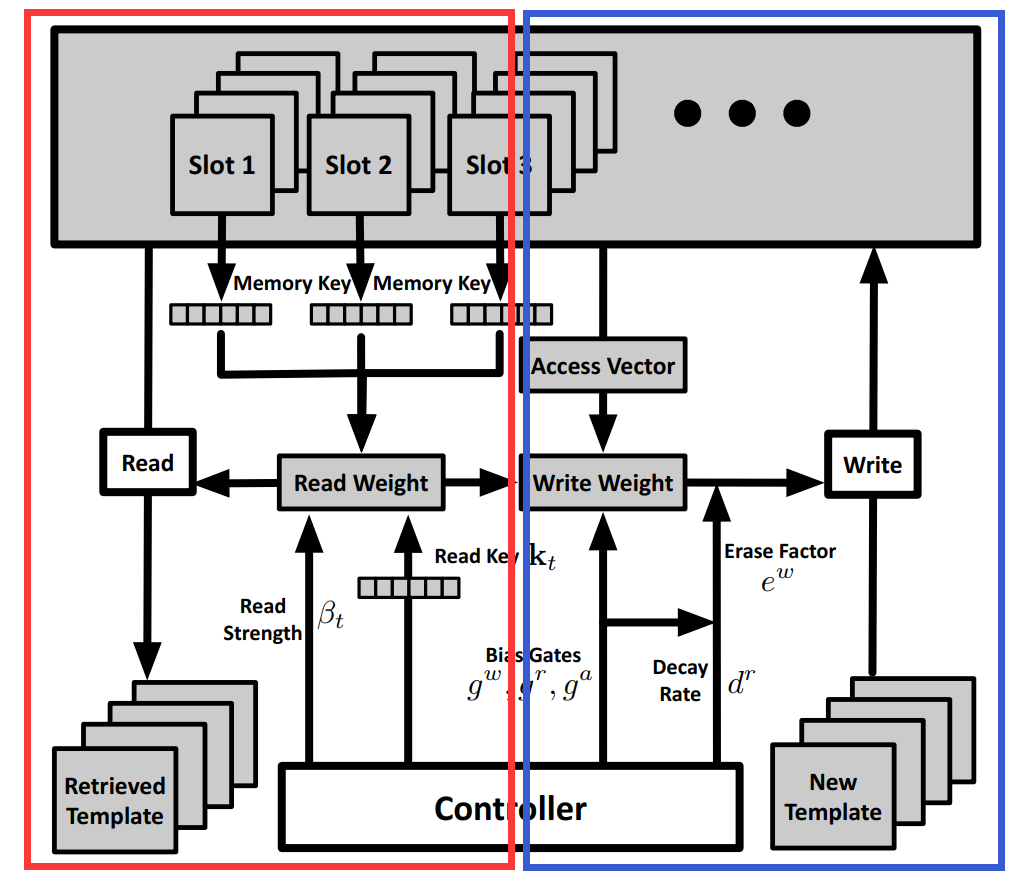
对于 Read,给定 LSTM 的输入信号,我们可以获得 Read Key 及其对应的 read strength,然后根据这个 vector 和 memory 中的记忆片段,进行 read weight 的计算,然后确定是否读取对应的 template;
具体来说:
(1) read key 及其 read strength 的计算可以用如下的公式:
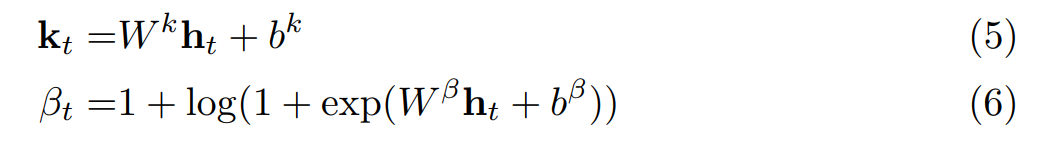
(2)read weight:
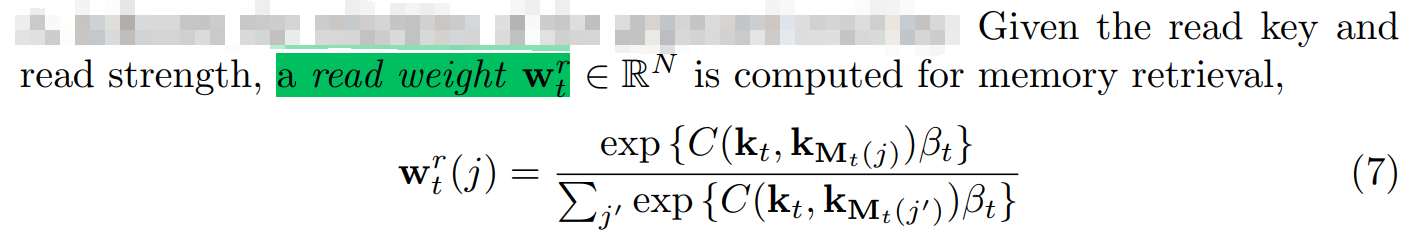
(3)the template is retrieved from memory:
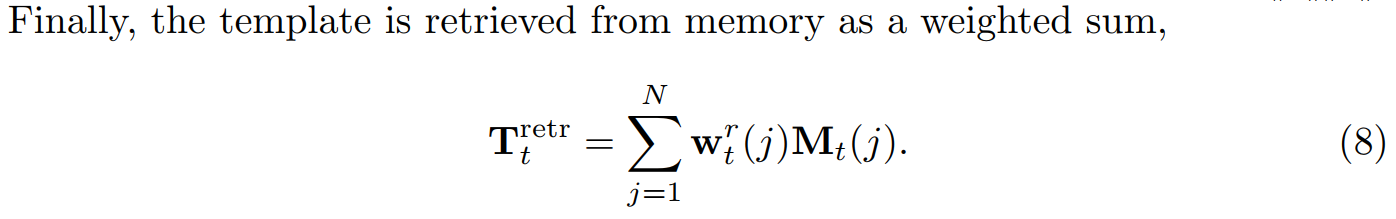
(4)最终模板的学习,可以通过如下公式计算得出:

对于 Write,给定 LSTM 的输入信号,我们可以计算 BiasGates 的三个值,从而知道 衰减率(decay rate),可以计算出 擦除因子(erase factor),我们根据获得的 write weight,来控制是否将 new templates 写入到 memory 中,以及写入多少的问题。、
(1)The write weight:
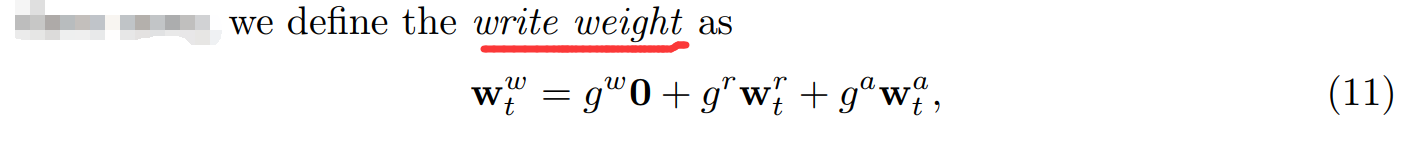
(2)The write gate:

(3)The allocation weight:

(4)最终模板的写入以及写入多少的控制:

==>> Experimental Results:
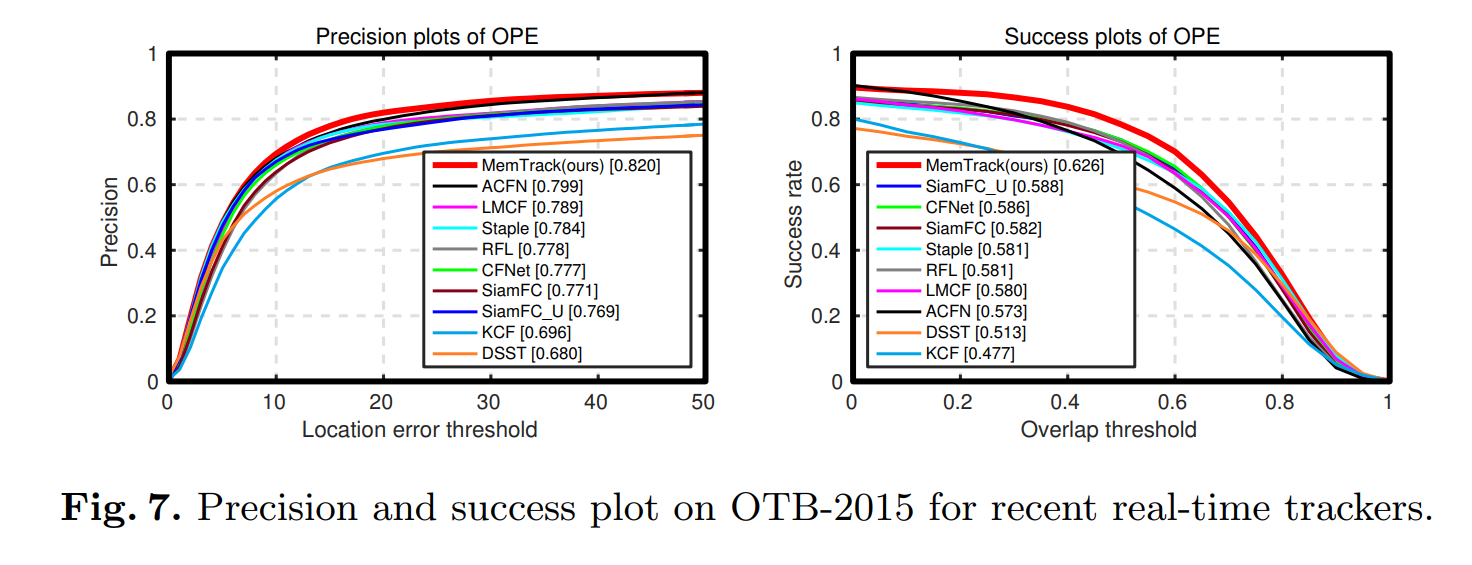
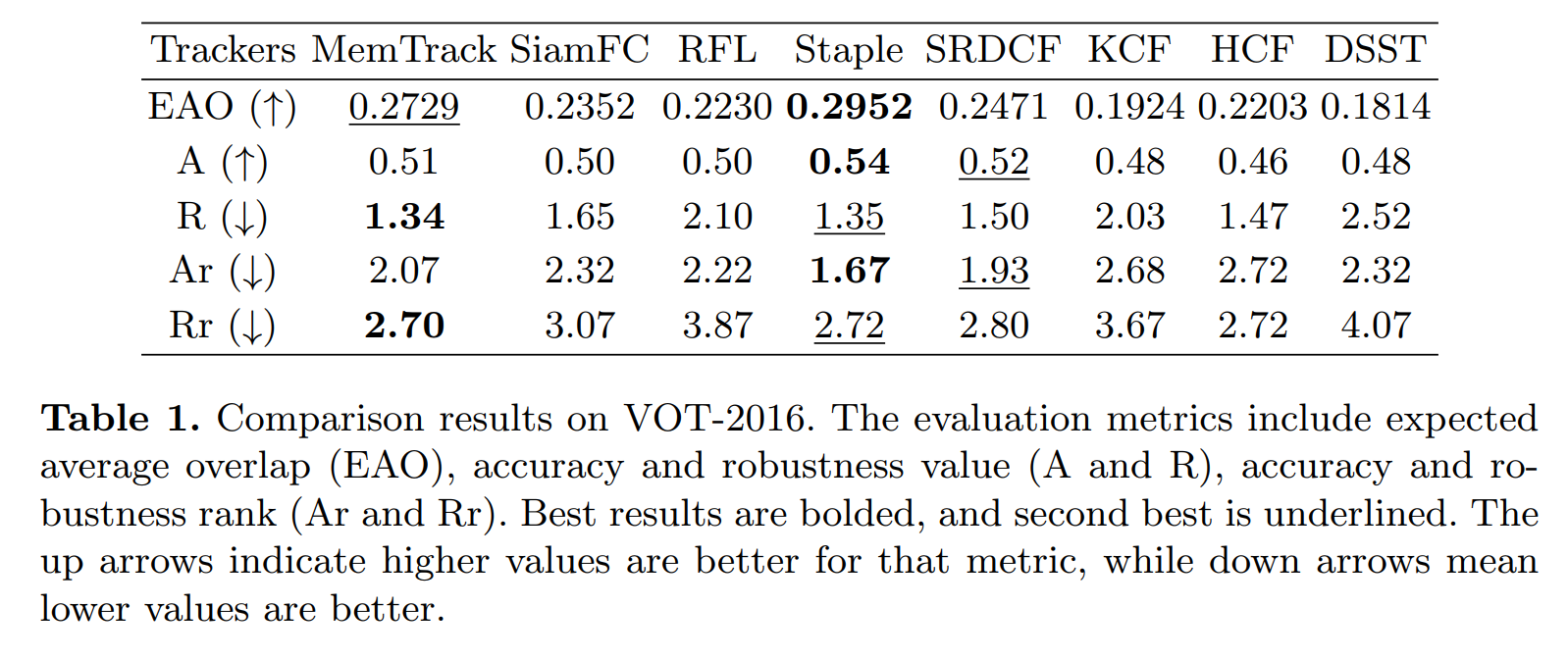
==
