Hierarchical Question-Image Co-Attention for Visual Question Answering
NIPS 2016
Paper:
Code:
Related Blog:
Introduction:
本文提出了一种新的联合图像和文本特征的协同显著性的概念,使得两个不同模态的特征可以相互引导。
此外,作者也对输入的文本信息,从多个角度进行加权处理,构建多个不同层次的 image-question co-attention maps,即:word-level,phrase-level and question-level。
最后,在 phrase level,我们提出一种新颖的 卷积-池化策略(convolution-pooling strategy)来自适应的选择 the phase size。
Methods:
1. Notation:
问题 Q = {q1, ... , qT},其中 qt 是第 t 个单词的特征向量。我们用 qtw, qtp, qts 分别表示 在位置 t 处的 Word embedding,phrase embedding 以及 question embedding。
图像特征表示为 V = {v1, ... ,vN},其中,vn 是空间位置 n 处的特征向量。
图像和问题的 co-attention features 在每一个层次,都可以表示为:v^, q^。
不同模块和层的权重可以表示为 W。
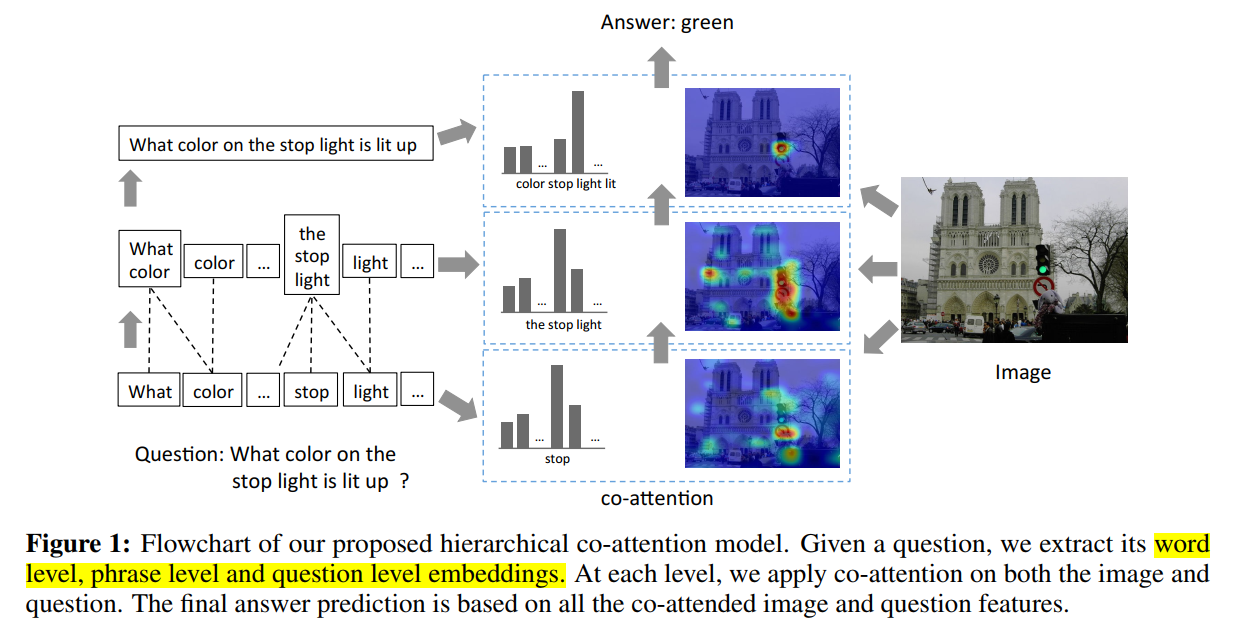
2. Question Hierarchy:
给定 the 1-hot encoding of the question words Q, 我们首先将单词映射到单词空间,以得到:Qw. 为了计算词汇的特征,我们采用在单词映射向量上采用 1-D 卷积。具体来说,在每一个单词位置,我们计算 the Word vectors with filters of three window sizes 的内积:unigram, bigram and trigram. 对于第 t 个单词,在窗口大小为 s 时的卷积输出为:
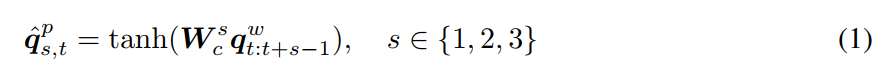
其中,Wcs 是权重参数。单词级别的向量 Qw 是 approximately 0-padding before feeding into bigram and trigram convolutions to maintain the length of the sequence after convolution. 给定卷积的结果,我们然后 在每一个单词位置,跨越不同的 n-grams 采用 max-pooling 以得到 phrase-level features:
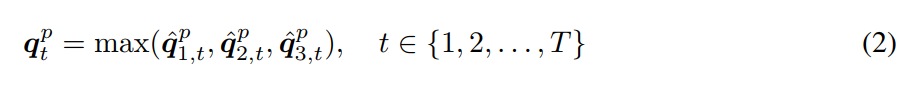
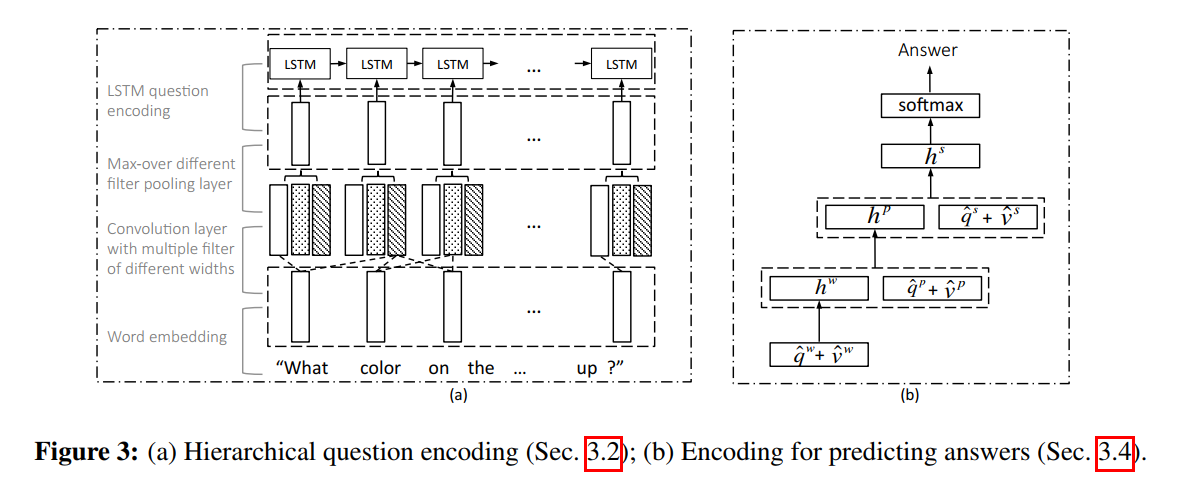
我们的 pooling method 不同于前人的方法,可以自适应的选择 different gram features at each time step, 并且可以保持原始序列的长度和序列。我们利用 LSTM 来编码 max-pooling 之后的 sequence 。对应的 question-level feature 是第 t 个时间步骤的 LSTM hidden vector。
3. Co-Attention:
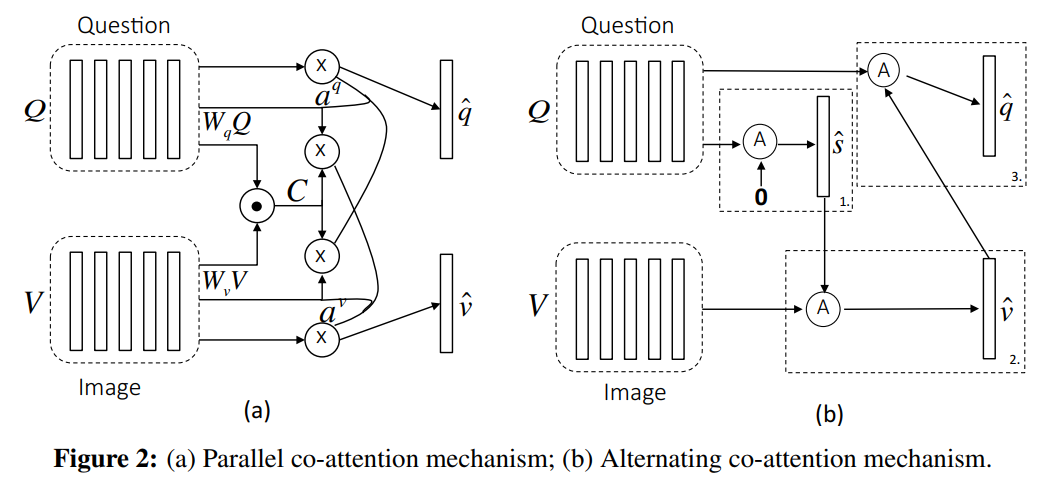
我们提出两种协同显著的机制(two co-attention mechanism),第一种是 parallel co-attention,同时产生 image 和 question attention。第二种是 alternating co-attention,顺序的产生 image 和 question attentions。如图2所示,这些 co-attention mechanisms 可以在所有问题等级上执行。
【Parallel Co-Attention】 这种 attention 机制尝试同时对 image 和 question 进行 attend。我们通过计算 图像 和 问题特征在所有的 image-locations and question-locations 进行相似度的计算。具体来说,给定一个图像特征图 V,以及 问题的表达 Q,放射矩阵 (the affinity matrix)C 可以计算如下:

其中,Wb 包括了权重。在计算得到 affinity matrix 之后,计算 image attention 的一种可能的方法是:simply maximize out the affinity over the locations of other modality, i.e.
![]()
并非选择 the max activation,我们发现如果我们将这个 affinity matrix 看做是一个 feature,然后学习去预测 image 和 question attention maps 可以提升最终的结果:
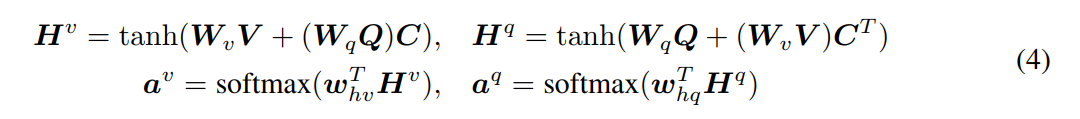
其中 Wv 和 Wq,whv,whq 是权重参数。av 和 aq 是每一个图像区域 vn 和 单词 qt 的 attention probability。放射矩阵 C 将 question attention space 转换为 image attention space. 基于上述 attention weights,图像 和 问题 attention vectors 可以看做是 image feature 和 question feature 的加权求和:
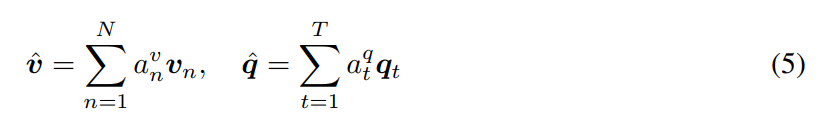
【Alternating Co-Attention】分步的协同 attention ,简单来讲,包括三个步骤:
1)summarize the question into a single vecror q;
2)attend to the image based on the question summary q ;
3)attend to the question based on the attended image feature.
我们定义 attention operation x^ = A(X; g),将图像特征 X 以及 从问题得到的 attention guidance g 作为输入,然后输出 the attended image vector。这些操作可以表达为:
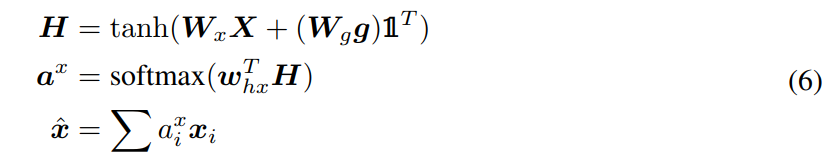
其中,空心符号1 是元素全为 1 的向量。
4. Encoding for Predicting Answers :
我们将 VQA 看做是一个 classification task,我们从所有的三个层次的 attended image and question features 来预测答案。我们用 MLP 来迭代的编码 the attention features:
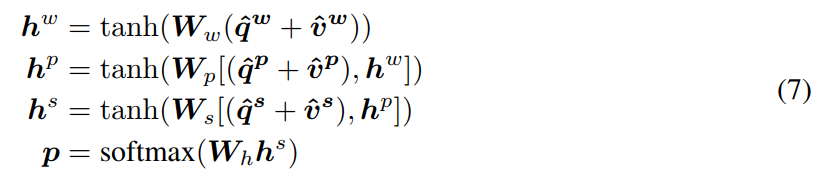
Experiments:

